Kapitel 10 Zusammenhang nominalskalierter Merkmale
Bislang wurde der Zusammenhang zwischen zwei dichotomen Merkmalen angeschaut. In Beispiel 9.2 wird die Anwendung eines Herbizides (Ja/Nein) mit Lymphdrüsenkrebs (Tumor/Kein Tumor) verglichen. Was wäre jedoch, wenn der Lymphdrüsenkrebs mit drei Ausprägungen (Kein Tumor / gutartiger Tumor / bösartiger Tumor) erhoben wird? Im Folgenden wird aufgezeigt, wie sich die bisher kennengelernten Methoden mit wenig Aufwand auf den Fall von einem oder zwei nominalskalierter Merkmale ausgeweitet werden kann.
10.1 Zusammenhang nominalskalierter Merkmale beschreiben
Beispiel 10.1 (Akademischer Erfolg bei verschiedenen Lernstilen) Das Lernen wird von Pädagog:innen oft vereinfachend in Lernstile unterteilt. Eine Unterteilung ist in einen visuellen, einen auditiven und einen kinästhetischen Lernstil. Pädagog:innen wollten nur herausfinden, ob der akademische Erfolg vom Lernstil abhängt und haben dazu Pädagogik-Studierende nach der Abschlussprüfung nach ihrem Abschluss (genügend, gut und ausgezeichnet) und ihrem dominanten Lernstil befragt.
Hier sollen also zwei nominalskalierte Merkmale verglichen werden. Die Daten können wie bei der Vierfeldertafel in zwei Formaten gespeichert werden: Entweder wird eine Zeile pro Beobachtung verwendet oder die Zeilen geben die Ausprägungskombinationen zusammen mit der Anzahl Beobachtungen an. Um eine Übersicht über die erhobenen Daten zu erhalten, wird wieder eine Kreuztabelle erstellt. Für diese sogenannte Mehrfeldertabelle wird die Zählung jeder Ausprägungskombination der beiden Merkmale aufsummiert, siehe Abbildung 10.1. Die Mehrfeldertabelle kann in Jamovi unter Analysen > Häufigkeiten > Kreuztabellen > Unabhängige Stichproben erstellt werden.
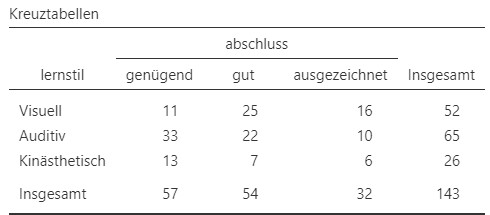
Abbildung 10.1: Mehrfeldertabelle mit absoluten Häufigkeiten der Daten Lernstil und Abschlusserfolg.
Die Zellen der Mehrfeldertabellen werden allgemein mit einem Zeilenindex \(i\) und einem Spaltenindex \(j\) bezeichnet. Die Zelle \(i = 1\) und \(j = 3\) enthält also Informationen zu Personen mit ausgezeichnetem Abschluss bei visuellem Lernstil. Die Anzahl Beobachtungen in der Zelle werden mit \(o_{ij}\) für observed bezeichnet, zum Beispiel \(o_{13} = 16\). Der Zeilenindex geht von \(1\) bis \(I\) und der Zeilenindex von \(1\) bis \(J\). Da beide Merkmale im Beispiel genau \(3\) Ausprägungen habe ist hier \(I\) und \(J\) genau \(3\).
Trotz der verbesserten Übersicht ist es aufgrund der verschiedenen Randhäufigkeiten schwer Auffälligkeiten in der Mehrfeldertabelle zu erkennen. Um dies zu vereinfachen, können der Tabelle die relativen Häufigkeiten (bezüglich Zeile oder Spalte) hinzugefügt werden, siehe Abbildung 10.2. Dies wird in Jamovi berechnet indem unter Zellen > Prozentsätze die Optionen Zeile und oder Spalte angewählt werden.
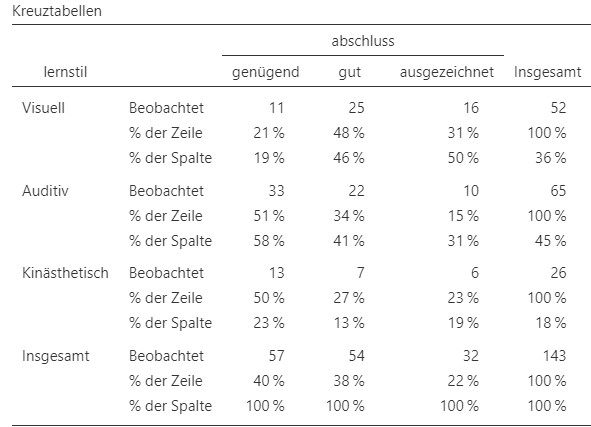
Abbildung 10.2: Mehrfeldertabelle mit absoluten und relativen Häufigkeiten der Daten Lernstil und Abschlusserfolg.
Es kann zum Beispiel festgestellt werden, dass beim visuellen Lernstil mit \(31\%\) ein viel höherer Anteil einen ausgezeichneten Abschluss macht als bei den Lernstilen auditiv mit \(15\%\) oder kinästhetisch mit \(23\%\). Die Frage ist nun, ob dieser Zusammenhang zwischen Lernstil und Abschluss auf die Zufallsstichprobenziehung zurückzuführen ist oder ob man davon ausgehen kann, dass der Zusammenhang auch in der Population (also allen Pädagogikstudierende) übertragen lässt.
10.2 Zusammenhang nominalskalierter Merkmale testen
Um dies zu testen, kann der im letzten Kapitel besprochene \(\chi^2\)-Test für dichotome Merkmale erweitert werden. Die Nullhypothese ist, dass die beiden nominalskalierten Merkmale, hier der Lernstil und der Abschluss, unabhängig voneinander sind. Der Test funktioniert nun genau gleich wie der Vierfeldertest. Für jede Zelle \(ij\) wird unter der Annahme der Unabhängigkeit der zwei Merkmale die erwartete Anzahl Beobachtungen \(e_{ij}\) berechnet. Die erwartete Anzahl Beobachtungen kann in Jamovi unter Zelle > Anzahl > Erwartete Anzahl dazugeschaltet werden, siehe Abbildung 10.3.
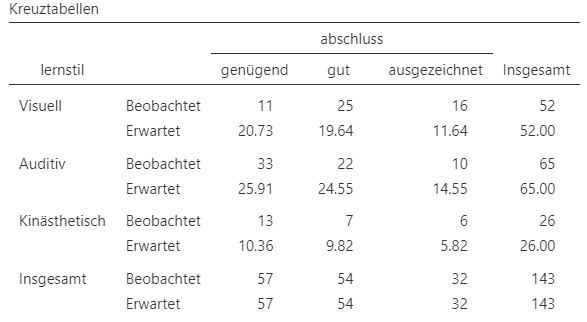
Abbildung 10.3: Mehrfeldertabelle mit beobachteten und unter Unabhängigkeit erwarteten Häufigkeiten der Daten Lernstil und Abschlusserfolg.
Je weiter diese Zahl von der beobachteten Zahl abweicht in einer Zelle abweicht, desto unwahrscheinlicher ist die Unabhängigkeit der beiden Merkmale. Es werden zum Beispiel \(o_{11}=11\) genügende Abschlüsse bei visuellem Lernstil beobachtet. Wenn Lernstil und Abschluss unabhängig wären, würden für diese Kombination \(e_{11} =20.73\) Beobachtungen erwartet.
Der \(\chi^2\)-Mehrfeldertest trägt dem Rechnung, indem die Teststatistik diese Differenz der erwarteten und beobachteten Anzahl austariert und für jede Zelle aufsummiert mit
\[\chi^2 = \sum_{i,j = 1}^{I,J} \frac{(o_{ij} - e_{ij})^2}{e_{ij}} \overset{Bsp}{=} 12.78.\]
Da die beiden Merkmale nominalskaliert sind, kann \(I\) und \(J\) im Gegensatz zu Kapitel 9 auch einen Wert grösser als \(2\) annehmen. Eine grosse Teststatistik spricht demnach wieder gegen die Unabhängigkeit.
Wenn die Stichprobenziehung oft wiederholt wird, kann festgestellt
werden, dass diese Teststatistik einer \(\chi^2\)-Verteilung bei
\[df = (I-1)\cdot (J-1) \overset{Bsp}{=} (3-1)\cdot (3-1) = 2\cdot 2 = 4\]
Freiheitsgraden folgt, siehe Abbildung 9.5. Die Teststatistik des \(\chi^2\)-Mehrfeldertests \(12.78\) wird also mit
der grünen Verteilung in der Abbildung verglichen. Die Werte rechts auf
der Abbildung sind seltener und der beobachtete Wert der Teststatistik liegt so, dass er zu den \(p = .012\) seltensten Beobachtungen zählt, sofern die Unabhängigkeit gilt. Der genaue \(p\)-Wert, kann mit Jamovi unter Statistiken > Tests > $\chi^2$ bestimmt werden. Da der \(p\)-Wert kleiner als \(5\%\) liegt, kann hier die Nullhypothese bei Signifikanzniveau \(\alpha = 5\%\) verworfen werden.
Bei der \(\chi^2\)-Verteilung handelt es sich wieder um eine Annäherung der tatsächlichen Verteilung der Teststatistik. Diese Annäherung ist nur gut, wenn die Anzahl erwartete Beobachtungen in jeder Zelle mindestens \(5\) beträgt. Ist dies nicht gegeben, kann entweder auch im Mehrfelderkontext Fishers exakter Test verwendet werden - wie letzterer genau erweitert wird, wird hier nicht behandelt - oder es können Ausprägungen zusammengefasst werden. Im Beispiel könnte zum Beispiel die Abschlussbewertung als neues Merkmal mit den zwei Ausprägungen genügend und mehr-als-genügend betrachtet werden.
Um die Effektstärke des \(\chi^2\)-Tests anzugeben kann Cramérs V
\[V = \sqrt{\frac{\chi^2}{n\cdot (k-1)}} = \sqrt{\frac{12.78}{143\cdot (3-1)}} = 0.21\]
verwendet werden. Hier stellt \(k\) die kleinere der beiden Dimensionen \(I\) und \(J\) der Mehrfeldertabelle dar. Da im Beispiel \(I\) und \(J\) gleich gross sind können beide als \(k\) verwendet werden. Also ist \(k = 3\) im Beispiel. Cramérs \(V\) ist immer grösser als \(0\) und kleiner als \(1\). Je weiter \(V\) von \(0\) weg ist, desto stärker sind die Merkmale voneinander abhängig. Die Interpretation als Effektstärke erfolgt dabei wie für eine Korrelation mit der Einschränkung, dass hier keine Richtung des Zusammenhangs interpretiert werden kann. Der Wert von \(0.42\) wird demnach als stark eingestuft. Cramérs \(V\) ist in Jamovi unter Statistiken > Nominal > Phi und Cramer's V zu finden.
Für eine Vierfeldertafel, also \(I = 2, J = 2\) entspricht Cramérs \(V\) genau Cramérs \(\phi\).
Eine Alternative zu Cramérs \(V\) ist der Kontingenzkoeffizient nach Pearson
\[C = \sqrt{\frac{\chi^2}{\chi^2+n}} = \sqrt{\frac{12.78}{12.78+143}} = 0.29, \]
wobei \(n\) die Gesamtanzahl Beobachtungen ist. Es gilt \(0 < C < \sqrt{(k-1)/k}\). Der Kontingenzkoeffizient wird also je nach Dimension auf einer unterschiedlichen Skala gemessen, was den intuitiven Vergleich der Werte für verschiedene Anwendungen erschwert. Korrekturmethoden existieren, sind aber weder in Jamovi implementiert noch werden sie oft verwendet. Es wird deshalb empfohlen immer Cramérs \(V\) zu verwenden.
Das Testergebnis wird schliesslich wie folgt berichtet:
Ein \(\chi^2\)-Test ergibt, dass der Abschluss (genügend/gut/ausgezeichnet) und der Lernstil (visuell/auditiv/kinästhetisch) signifikant voneinander abhängig sind, \(\chi^2 (4) = 12.78, p = .012, V = 0.21\). Der Zusammenhang ist als mittel einzustufen.
Hinweis. Für die Mehrfeldertabelle gibt es keine standardmässig verwendeten Grössen wie das relative Risiko oder das Chancenverhältnis. Um den Lesenden eine Datenübersicht zu präsentieren, kann in einer Arbeit zusätzlich zum Berichtensatz die Mehrfeldertabelle mit den absoluten oder und den relativen Häufigkeiten dargestellt werden.
10.3 Übungen
Übung 10.1
In einer Studie zur Bildungsgerechtigkeit soll herausgefunden werden, wie sich die Bildung der Mütter auf die Bildung der Kinder auswirkt. Dazu wurden 1319 Mütter mit Kindern mit abgeschlossenem ersten Bildungsweg nach ihrem und ihrer Kinder höchsten Bildungsabschluss (Sek I, Sek II oder Hochschule) gefragt. Die Daten sind in 10-exr-edu-heredity.sav zu finden.
- Betrachten Sie die Bildungsanteile der Kinder für jede Bildungsgruppe der Mütter. Denken Sie, dass es einen Zusammenhang gibt zwischen der Bildung der Mutter und der Bildung der Kinder?
- Wie gross ist der Anteil der Kinder mit Hochschulbildung deren Mütter höchstens eine Sek I Ausbildung genossen haben? Wie viele Kinder würde man erwarten, wenn die Bildung der Mütter irrelevant wäre für die Bildung der Kinder?
- Ist der Zusammenhang zwischen Bildungsniveau der Mütter und Kinder statistisch nachweisbar? Führen Sie einen \(\chi^2\)-Test durch und berichten Sie das Ergebnis, inklusive Effektstärke nach Cramér.
Klicke hier, um deine Lösung zu überprüfen.
Lösung. Zuerst wird der Datensatz mit Jamovi eingelesen und die
Analyseparameter werden gesetzt, siehe Abbildung
10.4.
Abbildung 10.4: Jamovi Eingabe.
Dies produziert das Analyseergebnis in Abbildung 10.5.
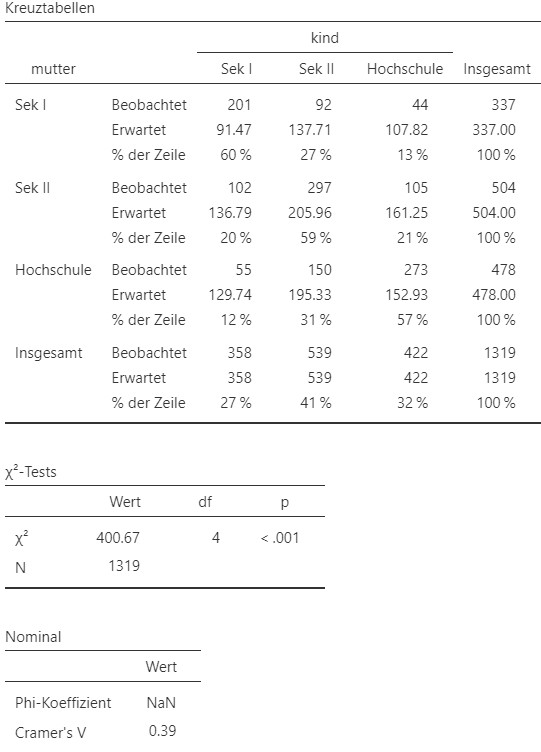
Abbildung 10.5: Jamovi Ausgabe.
Damit kann die Frage nun beantwortet werden:
- Es fällt auf, dass in jeder Bildungsgruppe der Mütter die Kinder mehrheitlich denselben Bildungsabschluss aufweisen. Ein Zusammenhang in der Stichprobe ist also augenscheinlich vorhanden.
- Der Anteil Kinder mit Hochschulbildung deren Mütter höchstens einen Sek I Abschluss haben liegt bei rund \(13\%\). Es würden \(107.82\) Kinder mit Hochschulbildung erwartet, wenn die Bildung der Mutter für die Bildung der Kinder keine Rolle spielen würde. Stattdessen wurden \(44\) Kinder beobachtet.
Ein \(\chi^2\)-Test ergibt, dass die Bildung der Kinder (Sek I/ Sek II / Hochschule) und die Bildung der Mütter (Sek I/ Sek II / Hochschule) signifikant voneinander abhängig sind, \(\chi^2 (4) = 400.67, p < 0.001, V = 0.39\). Der Zusammenhang ist als mittel einzustufen.
Übung 10.2
In einer Studie wurde untersucht, wie sich die Farbe eines Getränks auf die Geschmackswahrnehmung auswirkt (DuBose, Cardello, and Maller 1980). In einem Teil des dazugehörigen Experiments wurden 12 Proband:innen Getränke mit Kirschgeschmackt und verschiedenen Färbungen (rot, organge oder grün) vorgesetzt. Die Proband:innen haben die Getränke probiert und anschliessend angegeben, welche Geschmacksrichtung (heidelbeere/traube, kirsche/erbeere/himbeere, orange/aprikose, zitrone/grapefruit/apfel) sie dem Getränk zuordnen. Die Daten sind in 10-exr-taste-color.sav zu finden.
- Illustrieren Sie mit geeigneten Zahlen in
Jamovi, wie die Geschmackserkennungresponse_flavourmit der Farbe zusammenhängt. - Lässt sich die Aussage auf die Population aller Menschen ausweiten oder bleibt diese beschränkt auf die Stichprobe? Führen Sie einen \(\chi^2\)-Test durch und berichten Sie das Ergebnis, inklusive Effektstärke nach Cramér.
- Die Teststatistik folgt einer \(\chi^2\)-Verteilung mit wie vielen Freiheitsgraden?
- Wie gross ist hier \(k\) in der Berechnung von Cramérs V?
- Sind die Voraussetzungen für den \(\chi^2\)-Test gegeben? Skizzieren Sie gegebenenfalls Alternativen.
Klicke hier, um deine Lösung zu überprüfen.
Lösung. Zuerst wird der Datensatz mit Jamovi eingelesen und die
Analyseparameter werden gesetzt, siehe Abbildung
10.6.
Abbildung 10.6: Jamovi Eingabe.
Dies produziert das Analyseergebnis in Abbildung 10.7.
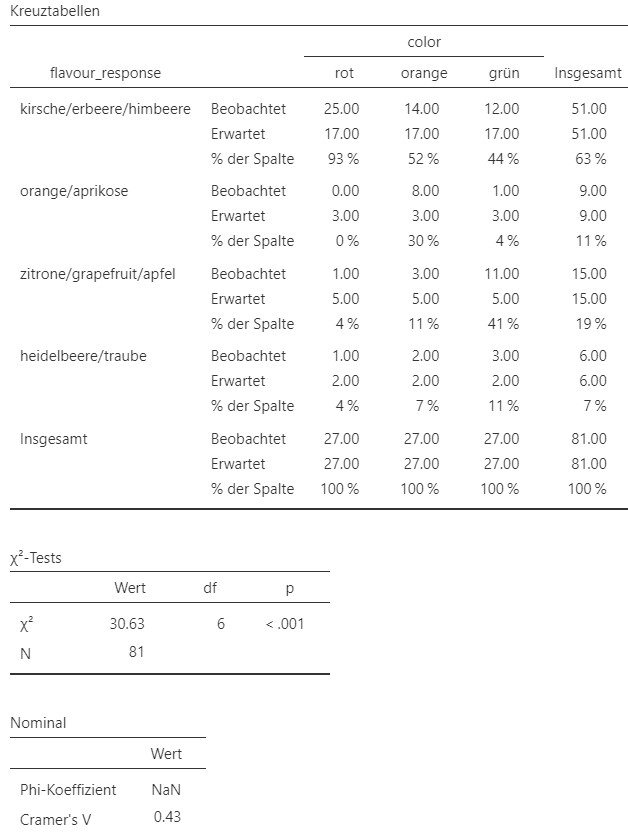
Abbildung 10.7: Jamovi Ausgabe.
Damit kann die Frage nun beantwortet werden:
- Interessant ist hier, wie gross der Anteil der Leute ist, welche den Kirschgeschmack bei verschiedenen Färbungen richtig herausgeschmeckt haben. Wenn das Getränk rot gefärbt ist, erkennen \(93\%\) den Kirschgeschmack richtig. Wenn das Getränk jedoch orange oder grün gefärbt ist, erkennen nur \(52\%\) respektive \(44\%\) den Geschmack richtig. Ebenso spannend ist, dass bei oranger Färbung \(30\%\) einen Aprikosen- oder Orangengeschmack erkennen. Bei grüner Färbung erkennen rund \(41\%\) einen Apfel-, Zitronen- oder Grapefruitgeschmack.
Ein \(\chi^2\)-Test ergibt, dass der erkannte Geschmack (heidelbeere/traube, kirsche/erbeere/himbeere, orange/aprikose, zitrone/grapefruit/apfel) und die Färbung der Getränke (rot, organge oder grün) signifikant voneinander abhängig sind, \(\chi^2 (6) = 30.63, p < 0.001, V = 0.43\). Der Zusammenhang ist als stark einzustufen.
- Die Verteilung der Teststatistik ist \(\chi^2\) bei \((I-1)\cdot (J-1) = (4-1)\cdot (3-1) = 6\) Freiheitsgraden.
- Das \(k\) in der Formel für Carmérs V ist die kleinere Zahl zwischen \(I = 4\) und \(J = 3\), also \(3\).
- Die erwarteten Beobachtungen für die Ausprägungen heidelbeere/traube und orange/aprikose liegen unter \(5\). Die Ergebnisse des \(\chi^2\) Tests sind also nicht valide. Alternativen wären die Zusammenlegung von Ausprägungen oder ein exakter Test nach Fisher und Yates.
Übung 10.3
In einer Studie wurde untersucht, wie sich die Lernstrategie (phonetisch: reimt auf x, selbstreferenz: trifft auf dich zu, semantisch: bedeutet x und strukturhaft: grossbuchstaben) auf die Merkfähigkeit von Wörtern auswirkt (Rogers, Kuiper, and Kirker 1977). Dazu wurde ein Wort mit einer dazugehörigen Aufgabe präsentiert und die Proband:innen mussten das Wort nach 10 Minuten und einer zwischenzeitlichen Ablenkung erinnern (ja/nein). Es wurde gezählt, wieviele Wörter von allen Proband:innen zusammen pro Lernstrategie erinnert wurden. Die Daten sind in 10-exr-memory-strategy.sav zu finden.
- Illustrieren Sie mit geeigneten Zahlen in
Jamovi, wie die Lernstrategie mit der Erinnerungsfähigkeit zusammenhängt. - Lässt sich die Aussage auf die Population aller Menschen ausweiten oder bleibt diese beschränkt auf die Stichprobe? Führen Sie einen \(\chi^2\)-Test durch und berichten Sie das Ergebnis, inklusive Effektstärke nach Cramér.
- Wie gross ist die gefundene Teststatistik? Ist es eher wahrscheinlich oder unwahrscheinlich diese zufällig zu beobachten, wenn die Nullhypothese stimmt? (Vergleichen Sie mit der korrekten Kurve der Abbildung der \(\chi^2\)-Verteilung).
- Wie gross ist hier \(k\) in der Berechnung von Cramérs V?
- Sind die Voraussetzungen für den \(\chi^2\)-Test gegeben? Skizzieren Sie gegebenenfalls Alternativen.
Klicke hier, um deine Lösung zu überprüfen.
Lösung. Zuerst wird der Datensatz mit Jamovi eingelesen und die
Analyseparameter werden gesetzt, siehe Abbildung
10.8.
Abbildung 10.8: Jamovi Eingabe.
Dies produziert das Analyseergebnis in Abbildung 10.9.
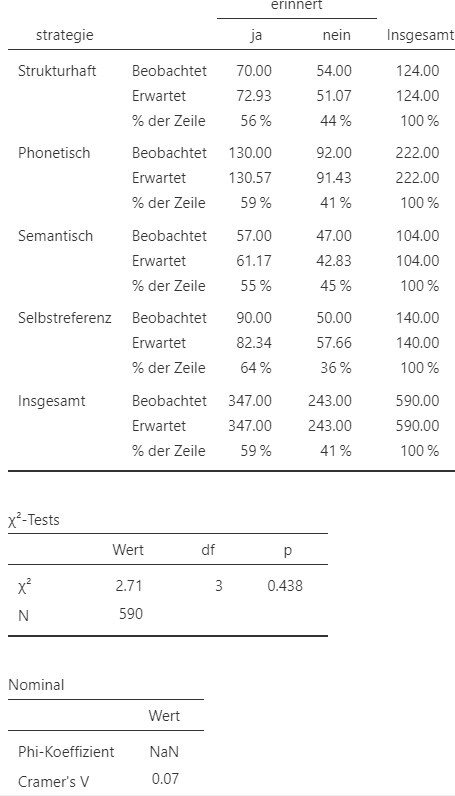
Abbildung 10.9: Jamovi Ausgabe.
Damit kann die Frage nun beantwortet werden:
- Der erinnerte Anteil variert je nach Lernstrategie zwischen \(64\%\) (Selbstreferenz) und \(55\%\) (Semantisch).
Ein \(\chi^2\)-Test ergibt, dass die Lernstrategie (phonetisch, selbstreferenz, semantisch und strukturhaft) und Worterinnerung (erinnert und nicht erinnert) nicht signifikant voneinander abhängig sind, \(\chi^2 (3) = 2.71, p = .438, V = 0.07\). Der Zusammenhang ist als schwach einzustufen.
- Der Wert der Teststatistik liegt bei 2.71. Dieser Wert ist \(\chi^2\)-verteilt bei \(3\) Freiheitsgraden. Dies entspricht auf der referenzierten Abbildung der türkisfarbenen Linie. Auf der Linie kann abgelesen werden, dass ein Wert von 2.71 nicht unwahrscheinlich ist, wenn die Nullhypothese wahr ist. Dies ist auch mit dem hohen \(p\)-Wert zu sehen.
- Das \(k\) in der Formel für Carmérs V ist die kleinere Zahl zwischen \(I = 4\) und \(J = 2\), also \(2\).
- Es werden in allen Zellen \(5\) oder mehr Beobachtugnen erwartet. Die Voraussetzungen für den \(\chi^2\)-Test sind somit gegeben.