Kapitel 5 Zentrale Tendenz testen
Eine andere Fragestellung, welche mit Daten beantwortet werden soll, ist, ob eine gewisse Aussage wahr ist oder falsch. Eine solche Aussage wird Hypothese (Symbol: \(H\)) genannt. Eine Hypothese könnte zum Beispiel sein:
\(H:\) Es regnet.
Ist die Hypothese einmal gefunden, können Daten gesammelt werden, um diese Hypothese zu bestätigen oder zu falsifizieren. Das heisst man geht nach raus ins Feld. Spürt man Regen auf der Haut bedeutet dies, dass \(H\) wahr ist. Spürt man keinen Regen, so ist \(H\) falsch.
Wenn eine Hypothese wahr ist, dann ist das Gegenteil der Hypothese falsch. Weil oft über die Hypothese und ihr Gegenteil debattiert wird, ist es nützlich die beiden auch terminologisch auseinanderhalten zu können. Die Hypothese, welche den bisherigen Informationsstand reflektiert wird Nullhypothese (Symbol \(H_0\)) genannt. War es draussen bei der letzten Messung vor einer Stunde schönes Wetter, dann ist die Nullhypothese
\(H_0:\) Es regnet nicht.
Das Gegenteil der Nullhypothese wird Alternativhypothese (Symbol \(H_1\)) genannt. Im Beispiel ist die Alternativhypothese
\(H_1:\) Es regnet.
Die Nullhypothese bleibt der Stand der Wahrheit, bis sie durch Daten widerlegt wurde. Wenn man noch drinnen ist, kann keine Aussage über die Wahrheit von \(H_0\) und \(H_1\) gemacht werden, da die Daten fehlen. In diesem Fall wird angenommen, dass \(H_0\) weiterhin wahr ist. Wenn man draussen Regen auf der Haut spürt, deutet dieser Datenpunkt darauf hin, dass \(H_0\) nicht länger wahr ist und jetzt wahrscheinlich \(H_1\) wahr ist. In diesem Fall spricht man davon, dass \(H_0\) abgelehnt und \(H_1\) angenommen wird.
5.1 Entspricht der Erwartungswert einem gewissen Wert?
Um eine Hypothese mit Daten überprüfbar zu machen, muss diese in eine Form gebracht werden, welche Daten einbezieht. Eine einfache Form einer solchen überprüfbaren Hypothese ist
\(H:\) Das durchschnittliche Vermögen einer in der Schweiz lebenden Person beträgt \(100'000\) CHF.
Wenn die Population alle in der Schweiz lebenden Personen sind, dann entspricht dies also der Nullhypothese
\(H_0:\mu = 100'000\).
Abstrahiert, soll bei dieser Problemstellung herausgefunden werden, ob der Erwartungswert einer Population einem gewissen Wert entspricht. Das Gegenteil dieser Nullhypothese ist die Alternativhypothese
\(H_1: \mu \neq 100'000\).
Dies bedeutet, dass das durchschnittliche Vermögen der Population nicht bei \(100'000\) CHF liegt. Weil die Alternativhypothese hier zwei Ausgänge zulässt, nämlich kleiner oder grösser als \(100'000\) CHF wird diese Art der Hypothesenstellung als zweiseitige Hypothese bezeichnet.
Eine weitere Form der Hypothese wäre
\(H:\) Das durchschnittliche Vermögen einer in der Schweiz lebenden Person beträgt weniger als oder genau \(100'000\) CHF.
In Formelsprache übersetzt entspricht dies
\(H_0: \mu \leq 100'000\).
Das Gegenteil davon ist, wenn das durchschnittliche Vermögen grösser und ungleich 100’000 CHF ist, also
\(H_1: \mu > 100'000\).
Weil die Alternativhypothese hier nur einen Ausgang zulässt, nämlich grösser als \(100'000\) CHF wird dies als einseitige Hypothese bezeichnet. Eine einseitige Hypothese kann auf beide Seiten formuliert sein: \(H_0:\mu \leq 100'000\) und \(H_1: \mu > 100'000\), wie eben erwähnt oder auch \(H_0:\mu \geq 100'000\) und \(H_1: \mu < 100'000\).
Hinweis. Die verwendeten Zeichen in den Formeln sind
- \(=\): Gleichheit, sprich “gleich”. Beispiele:
- \(3 = 3\) (\(3\) gleich \(3\)) ist eine wahre Aussage.
- \(3 = 4\) (\(3\) gleich \(4\)) ist eine falsche Aussage.
- \(\neq\): Ungleichheit, sprich “ungleich” oder “nicht gleich”. Beispiele:
- \(3 \neq 3\) (\(3\) ist nicht gleich \(3\)) ist eine falsche Aussage.
- \(3 \neq 4\) (\(3\) ist nicht gleich \(4\)) ist eine wahre Aussage.
- \(<\): Kleiner, sprich “kleiner”. Beispiele:
- \(4 < 3\) (\(4\) ist kleiner als \(3\)) ist eine falsche Aussage.
- \(3 < 3\) (\(3\) ist kleiner als \(3\)) ist eine falsche Aussage.
- \(3 < 4\) (\(3\) ist kleiner als \(4\)) ist eine wahre Aussage.
- \(\leq\): Kleiner gleich, sprich “kleiner gleich”. Beispiele:
- \(4 \leq 3\) (\(4\) ist kleiner oder gleich wie \(3\)) ist eine falsche Aussage.
- \(3 \leq 3\) (\(3\) ist kleiner oder gleich wie \(3\)) ist eine wahre Aussage.
- \(3 \leq 4\) (\(3\) ist kleiner oder gleich wie \(4\)) ist eine wahre Aussage.
- \(>\): Grösser, sprich “grösser”. Beispiele:
- \(4 > 3\) (\(4\) ist grösser als \(3\)) ist eine wahre Aussage.
- \(3 > 3\) (\(3\) ist grösser als \(3\)) ist eine falsche Aussage.
- \(3 > 4\) (\(3\) ist grösser als \(4\)) ist eine falsche Aussage.
- \(\geq\): Grösser gleich, sprich “grösser gleich”. Beispiele:
- \(4 \geq 3\) (\(4\) ist grösser oder gleich wie \(3\)) ist eine wahre Aussage.
- \(3 \geq 3\) (\(3\) ist grösser oder gleich wie \(3\)) ist eine wahre Aussage.
- \(3 \geq 4\) (\(3\) ist grösser oder gleich wie \(4\)) ist eine falsche Aussage.
Beispiel 5.1 (Vermögen)
Eine Sozialpolitikberatungsfirma will herausfinden, ob das durchschnittliche Vermögen der in der Schweiz lebenden Personen im letzten Jahr gestiegen ist. Sie stellen dazu basierend auf dem aktuellen Wissensstand die Nullhypothese auf, dass das durchschnittliche Vermögen nicht gestiegen ist, und die Alternativhypothese, dass das durchschnittliche Vermögen gestiegen ist:
\(H_0: \mu \leq 100'000\) CHF
\(H_1: \mu > 100'000\) CHF
Um die Hypothesen auf einer Datengrundlage zu evaluieren, erfragt es das Vermögen von \(n=20\) zufällig ausgewählten Personen und findet ein durchschnittliches Vermögen von \(M=119853\) CHF.
Es kann nun schnell gesagt werden, dass das durchschnittliche Vermögen in der Population gestiegen ist, weil \(119853\) CHF grösser ist als \(100'000\) CHF. Dies so zu behaupten wäre jedoch falsch, weil nicht alle Personen in der Population befragt wurden, sondern lediglich eine Zufallsstichprobe. Wie in Kapitel 3 muss hier für eine Generalisierung der Stichprobe auf die Population der Effekt der zufälligen Stichprobenziehung miteinbezogen werden.
Aufgrund der Zufallsstichprobe ist es unmöglich zu sagen, ob unsere Stichprobe eine eher seltene Stichprobenziehung aus einer Population mit unverändertem durchschnittlichen Vermögen von \(100'000\) CHF ist (Abbildung 5.1 links) oder ob es eine eher häufig vorkommende Stichprobenziehung aus einer Population mit höherem durchschnittlichen Vermögen ist (Abbildung 5.1 rechts).
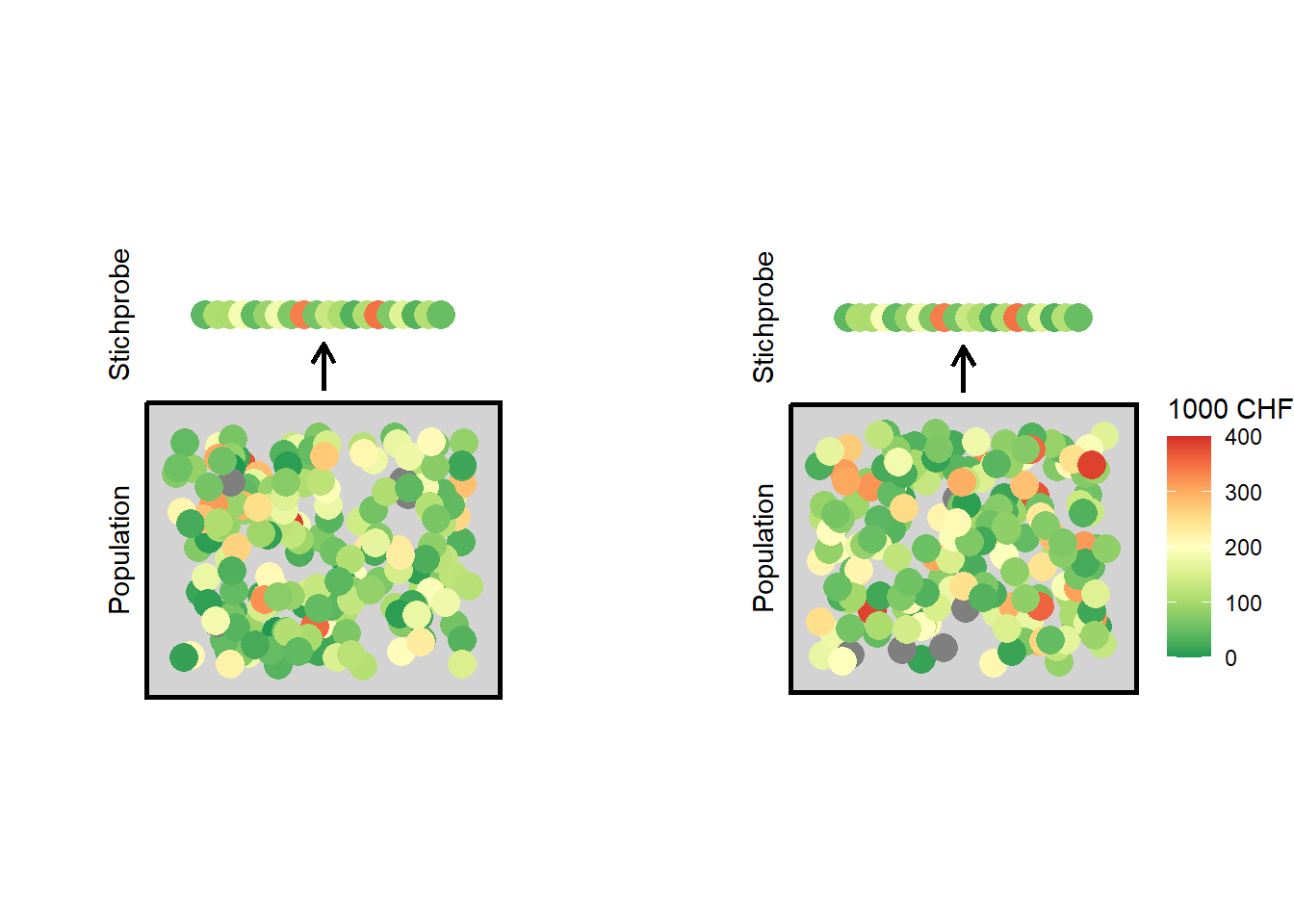
Abbildung 5.1: Vorgestellte Zufallsstichprobenziehung. Links: Nullhypothese ist wahr. Rechts: Nullhypothese ist falsch. Die grauen Punkte entsprechen Vermögen über 400’000 CHF.
Es kann jedoch ausgesagt werden, mit welcher Wahrscheinlichkeit der gefundene Stichprobenmittelwert realisiert wird, gegeben dass die Nullhypothese wahr ist. Hier wird also angenommen, dass eine Population mit Erwartungswert \(\mu = 100'000\) CHF vorliegt und dass anschliessend zum Beispiel \(3000\) Stichproben an je \(20\) Beobachtungen pro Stichprobe gezogen werden. Von jeder dieser Stichproben wird das arithmetische Mittel berechnet. In der Verteilung dieser Mittelwerte, siehe Abbildung 5.2, wird nun der tatsächliche Mittelwert der Stichprobe \(\bar{x} = 119853\) verortet.
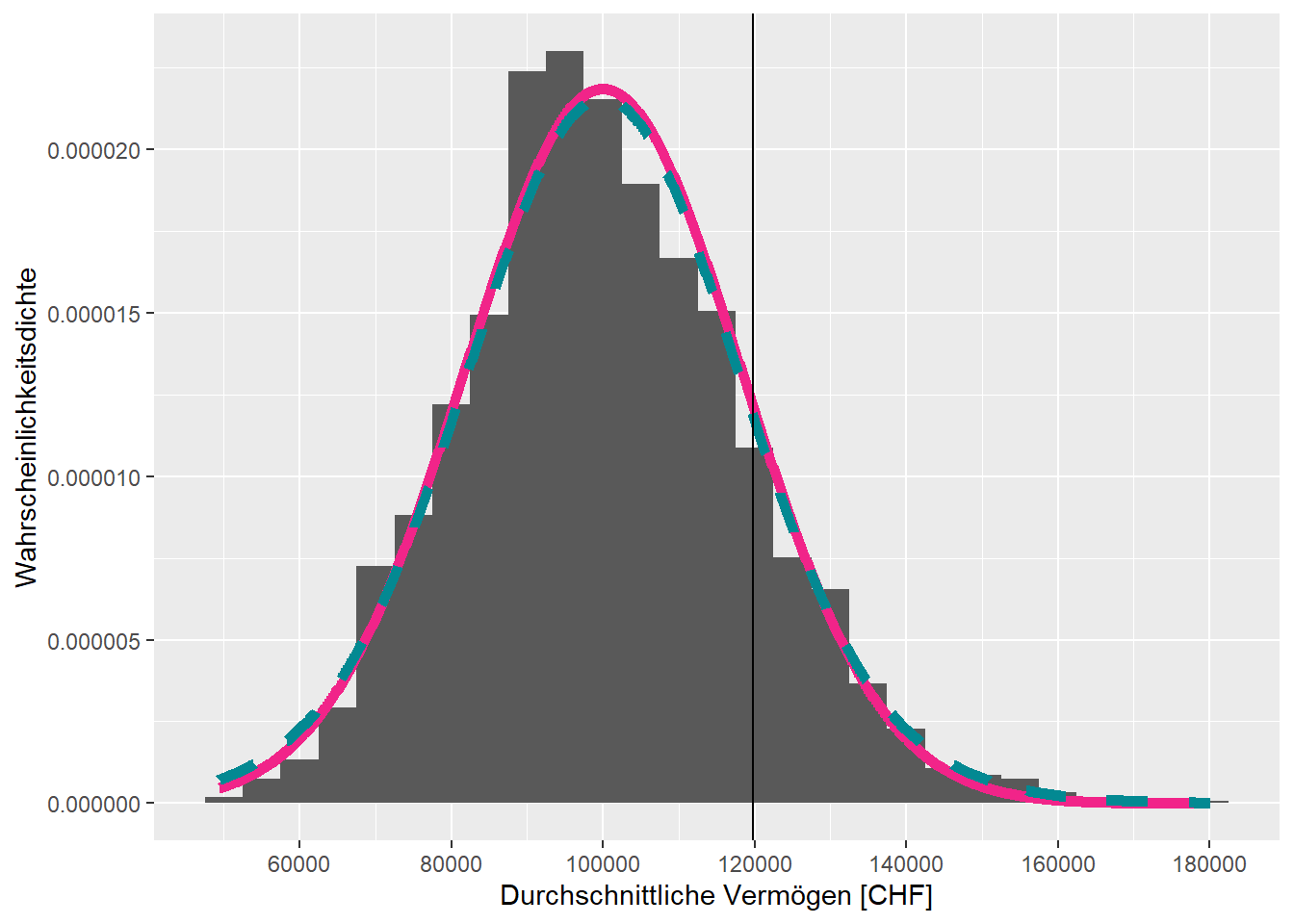
Abbildung 5.2: Verteilung der durchschnittlichen Vermögen unter der Annahme, dass die Nullhypothese wahr ist.
Der beobachtete Mittelwert ist zwar nicht genau bei \(100'000\) CHF, aber trotzdem noch einigermassen plausibel, wenn die Nullhypothese stimmt. Um diesen Gedanken zu formalisieren, gibt es zwei Denkweisen, welche nun vorgestellt werden.
Die eine Denkweise wurde von Ronald Fisher propagierte. Sie stellt die Frage nach der Wahrscheinlichkeit, dass zufällig der beobachtete Wert oder ein noch extremerer Wert in Richtung der Alternativhypothese resultiert, gegeben die Nullhypothese ist wahr. Im Beispiel entspricht dies der Wahrscheinlichkeit den Wert \(119853\) oder einen grösseren Wert zu beobachten, wenn der Erwartungswert tatsächlich bei \(100'000\) CHF liegt. Um diese Wahrscheinlichkeit zu bestimmen, kann einfach gezählt werden, welcher Anteil der Stichprobenmittelwerte grösser oder gleich \(119853\) CHF ist. Im Beispiel sind dies \(0.143 = 14.3\%\). Dieser Wert wird, abgeleitet vom englischen probability, \(p\)-Wert (Symbol: \(p\)) genannt. Beim Berichten des \(p\)-Werts wird normalerweise die führende \(0\) nicht geschrieben, also \(p = .143\).
Bei der anderen von Neyman und Pearson propagierten Denkweise muss noch vor der Datenerhebung ein sogenanntes Signifikanzniveau (Symbol \(\alpha\), sprich ‘alpha’) bestimmt werden. Dieser Wert entspricht der Wahrscheinlichkeit, dass der statistische Test die Nullhypothese verwirft, obwohl diese wahr gewesen wäre. Normalerweise wird \(\alpha = 5\%\) gesetzt. Es wird also akzeptiert, dass ein statistischer Test in \(5\%\) der Fälle gegen die Nullhypothese entscheidet, obwohl diese wahr wäre. In einem zweiten Schritt wird bestimmt, welches die \(5\%\) unwahrscheinlichsten Werte sind, wenn die Nullhypothese wahr ist. Diese Werte werden Ablehnungsbereich genannt. Im Beispiel sind dies die \(5\%\) höchsten Werte, nämlich Vermögen von \(131511\) CHF und grössere Vermögen. Nun wird bestimmt, ob der tatsächliche beobachtete Wert im Ablehnungsbereich liegt oder nicht. Im Beispiel liegt der Stichprobenmittelwert \(119853\) CHF nicht im Ablehnungsbereich. In diesem Fall wird die Nullhypothese nicht verworfen und das Testresultat erhält das Prädikat nicht signifikant. Läge der Stichprobenmittelwert im Ablehnungsbereich, so wäre das Testresultat als signifikant einzustufen.
Hinweis. Ein signifikanter Unterschied bedeutet im allgemeinen Sprachgebrauch ein bedeutsamer, substanzieller Unterschied. Im statistischen Kontext bedeutet ein signifikanter Unterschied, wie oben beschrieben, dass ein Unterschied bis auf eine gewisse Irrtumswahrscheinlichkeit (angegeben durch das Signifikanzniveau) nicht zufällig zustande gekommen ist. Ein nicht signifikanter Unterschied bedeutet dagegen, dass die Beobachtung zufällig zustande gekommen sein könnte. Für letzteres gibt es zwei Erklärungen: (1) \(H_0\) ist tatsächlich wahr. (2) \(H_0\) ist zwar falsch, aber die Stichprobenziehung hat zufällig zu einem ähnlichen Resultat geführt, wie wenn \(H_0\) wahr wäre. Ist ein Testresultat nicht signifikant, so kann also nicht genau gesagt werden, ob \(H_0\) wahr ist oder nicht. Ist das Testresultat signifikant, so ist \(H_0\) eher unwahrscheinlich.
In manchen Texten werden allgemeine und auch statistische Fragen bearbeitet. Hier empfiehlt sich für den allgemeinen Sprachgebrauch substanziell und für die statischen Aussagen statistisch signifikant zu verwenden.
Es wird ausserdem empfohlen, das Wort signifikant immer nur als Prädikat für eine Qualifizierung der Nullhypothese zu verwenden. Im Beispiel war \(H_0: \mu \leq 100'000\)CHF. Korrekte Aussage sind: - Das durchschnittliche Vermögen ist im letzten Jahr nicht signifikant gewachsen. - Das durchschnittliche Vermögen ist in diesem Jahr nicht signifikant grösser als \(100'000\) CHF.
Die beiden Denkarten entsprechen sich insofern, als ein \(p\)-Wert kleiner als \(5\%\) ein signifikantes Resultat bei Signifikanzniveau \(\alpha = 5\%\) bedeutet. In der Praxis werden beide Methoden verwendet. Im Beispiel liegt der \(p\)-Wert bei \(p = .143\). Dies bedeutet, dass die Wahrscheinlichkeit zufällig den realisierten Stichprobenmittelwert zu erhalten, gegeben, dass die Nullhypothese stimmt, grösser als \(5\%\) ist und demnach auch der Unterschied nicht signifikant ist.
Ein noch zu lösendes Problem ist, dass normalerweise Geld, Zeit und Nerven fehlen, um eine Stichprobenziehung \(3000\)-mal zu wiederholen. Hier hilft es wieder zu beobachten, dass die Verteilung der Werte des Histogramms in Abbildung 5.2 wieder mit zunehmender Stichprobengrösse immer genauer einer Normalverteilung folgen. Tatsächlich trifft es aufgrund des zentralen Grenzwertsatzes immer zu, dass wenn ein Merkmal mit \(N\) Beobachtungen, Erwartungswert \(\mu\) und Standardabweichung \(\sigma\) hat, der Wert
\[z = \frac{\bar{x}-\mu}{\frac{\sigma}{\sqrt{n}}}\]
normalverteilt ist, wobei \(\mu\) hier dem Wert der Nullhypothese entspricht, also \(100'000\) CHF. Dies entspricht der roten Linie in Abbildung 5.2. Ist die Standardabweichung des Merkmals \(\sigma\) in der Population unbekannt, so wird diese mit der Standardabweichung in der Stichprobe \(s\) geschätzt. Diese zusätzliche Unsicherheit führt dazu, dass
\[\begin{equation}
t = \frac{\bar{x}-\mu}{\frac{s}{\sqrt{n}}}
\tag{5.1}
\end{equation}\]
nicht mehr normal-, sondern \(t\)-verteilt ist bei \(n-1\) Freiheitsgraden (grüne Linie, Abbildung 5.2). Die \(t\)-Verteilung mit allen Freiheitsgraden ist in Jamovi hinterlegt und es kann der Software überlassen werden den \(p\)-Wert und den Ablehnungsbereich genau zu bestimmen. In Abbildung 5.3 wurde nochmal illustriert, dass es bei vielen Beobachtungen der theoretische \(p\)-Wert (Kurve) mit dem empirischen \(p\)-Wert der Simulationen (Histogramm) übereinstimmt respektive der Ablehnungsbereich der \(t\)-Verteilung (Kurve) gleich ist, wie der simulierte Ablehnungsbereich (Histogramm).
## Warning: Removed 2 rows containing non-finite outside the scale range
## (`stat_bin()`).## Warning: Removed 8 rows containing missing values or values outside the scale range
## (`geom_bar()`).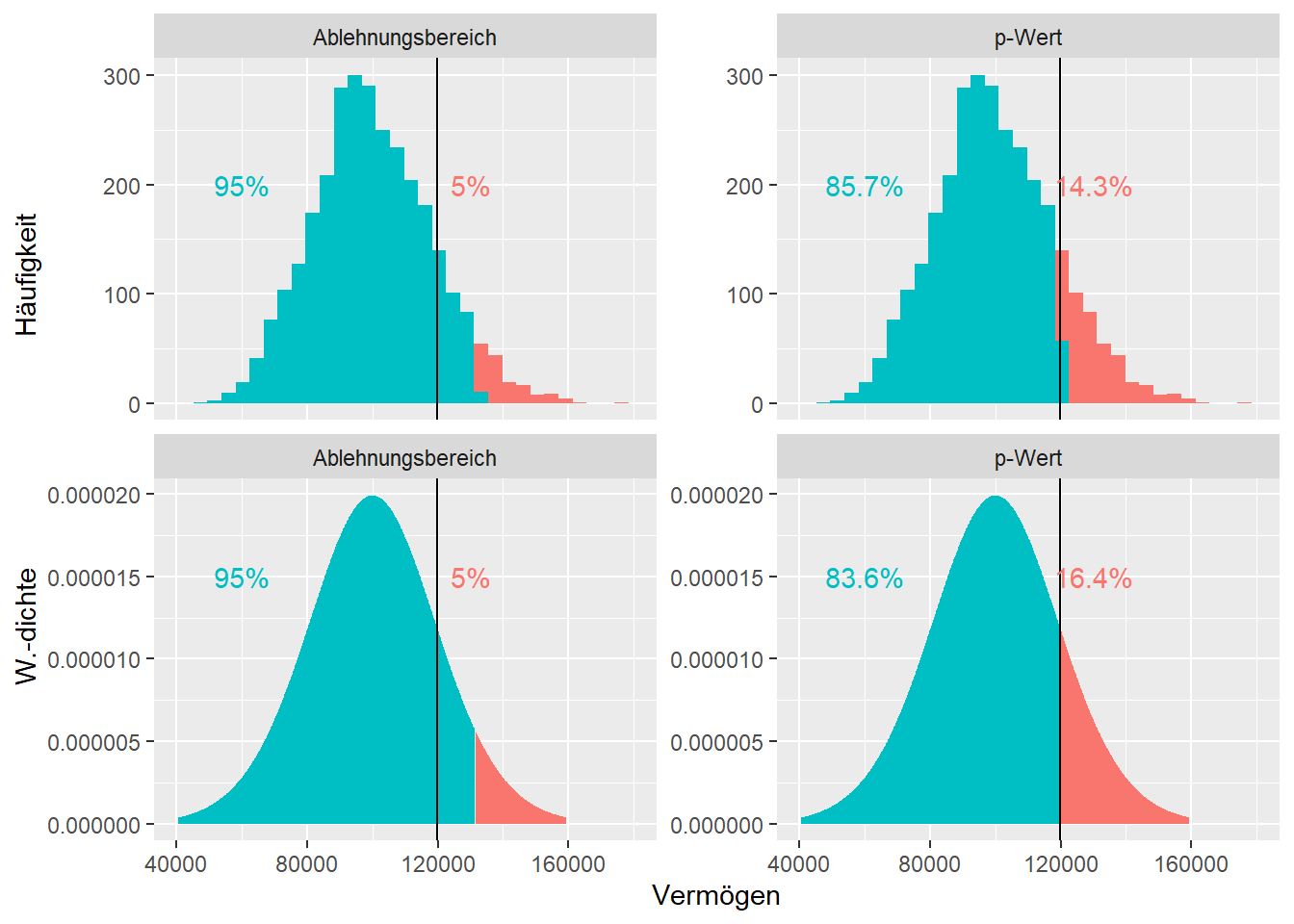
Abbildung 5.3: Oben: Histogramm der simulierten Verteilung; unten: theoretische t-Verteilung; links: Illustration p-Wert; rechts: Illustration Ablehnungsbereich. Die Linie entspricht dem beobachteten Stichprobenmittelwert. Alle Verteilungen basieren auf der Annahme, dass die Nullhypothese wahr ist.
Die Berechnung des für den Test relevanten Wertes, hier des \(t\)-Wertes wird Teststatistik (oder auch Prüfgrösse oder nur Statistik) genannt. Eine Teststatistik hat normalerweise eine bekannte theoretische Verteilung, welcher die Teststatistik folgt, wenn die Nullhypothese wahr ist. Aufgrund der theoretischen \(t\)-Verteilung der vorliegenden Statistik und der einen Stichprobe (vgl. nächstes Kapitel) wird dieser Test Einstichproben-\(t\)-Test genannt.
Das oben gefundene Resultat wird in der folgenden Form berichtet:
Ein Einstichproben-\(t\)-Test ergibt, dass das durchschnittliche Vermögen (\(M = 119853\) CHF, \(SD = 88528\), \(N = 20\)) in diesem Jahr nicht signifikant grösser als \(100'000\) CHF ist, \(t(19) = 1.003\), \(p = .164\).
Hinweis. Folgende Begriffe und Zahlen werden dabei verwendet:
- Das durchschnittliche Vermögen (fehlt durchschnittlich ist die Aussage falsch).
- \(M\), \(SD\), \(N\) entsprechen dem arithmetischen Mittel, der geschätzten Standardabweichung und der Anzahl Beobachtungen in der Stichprobe. Die Einheit muss nicht wiederholt werden.
- Signifikanz (siehe letzter Hinweis)
- grösser als \(100'000\) CHF ist die Referenz zur Alternativhypothese
- \(t(19)\) bedeutet, dass die Teststatistik \(t\)-verteilt ist mit \(19\) Freiheitsgraden.
- \(1.003\) ist der Wert der Teststatistik berechnet mit Formel (5.1) aus der Stichprobe. Dieser Wert ist skaliert und muss im Kontext der standardisierten \(t\)-Verteilung wie in Abbildung 4.7 interpretiert werden.
- \(p = .164\) entspricht dem \(p\)-Wert. Es wird normalerweise die führende \(0\) weggelassen (also nicht \(0.164)\), da es sich um eine Zahl handelt, welche nie kleiner als \(0\) oder grösser als \(1\) sein kann.
Beispiel 5.2 (Alexithymie) Mit Gefühlsblindheit oder Alexithymie (griechisch: a = ohne, lexis= lesen, sprechen, thymie = Gefühle) werden Einschränkungen bei der Fähigkeit Emotionen wahrzunehmen, zu erkennen und zu beschreiben bezeichnet. Es gibt ein online Messinstrument, welches die Alexithymie auf einer Skala von \(37\) Punkten (kleine Gefühlsblindheit) bis \(185\) (grosse Gefühlsblindheit) misst. Die Skala wurde so gewählt, dass die durchschnittliche Alexithymie aller Menschen bei \(100\) liegt. Eine Psychologin interessiert sich nun dafür, ob junge Menschen unter \(25\) durchschnittlich andere Alexithymie-Werte aufweisen als die Gesamtbevölkerung. Um dies zu testen, befragt sie \(N = 391\) unter \(25\)-jährige mit besagtem Messinstrument. In dieser Gruppe wurde eine durchschnittliche Alexithymie von \(M = 96.7\) Punkten festgestellt.
Der erste Schritt ist auch hier die Null- und Alternativhypothesen aufzustellen. Die Psychologin stellt die Frage, ob sich die durchschnittliche Alexithymie in der Grundgesamtheit, in der Folge mit \(\mu\) bezeichnet, von \(100\) unterscheidet oder nicht. Es ist zu beobachten, dass sie keine Annahme über die Richtung der Abweichung trifft (eine höhere oder eine tiefere Alexithymie wären denkbar) und es sich deshalb um eine zweiseitige Hypothesenstellung handelt.
Die Nullhypothese beschreibt den bisherigen Informationsstand, also dass die durchschnittliche Alexithymie der Population bei \(100\) Punkten liegt, oder kurz
\(H_0:\mu = 100\) Punkte.
Die Alternativhypothese besagt das Gegenteil davon, also hier, dass die durchschnittliche Alexithymie nicht mehr bei \(100\) Punkten liegt, oder kurz
\(H_1: \mu \neq 100\) Punkte.
Um die Wahrscheinlichkeit des beobachteten arithmetischen Mittels der Stichprobe von \(M = 96.7\) Punkten zu ermitteln, gegeben, dass die Nullhypothese wahr ist, kann erneut auf den Gedanken der wiederholten Stichprobenziehung zurückgegriffen werden. Bei diesem Gedankenexperiment wird angenommen, dass Nullhypothese wahr ist und dass das die Untersuchung \(4000\)-mal wiederholt wurde mit jeweils \(391\) Beobachtungen. Von jeder dieser Stichproben kann wiederum das arithmetische Mittel berechnet werden. Die Verteilung dieser arithmetischen Mittel ist in Abbildung 5.4 oben dargestellt.
## Warning: Removed 2 rows containing non-finite outside the scale range
## (`stat_bin()`).## Warning: Removed 8 rows containing missing values or values outside the scale range
## (`geom_bar()`).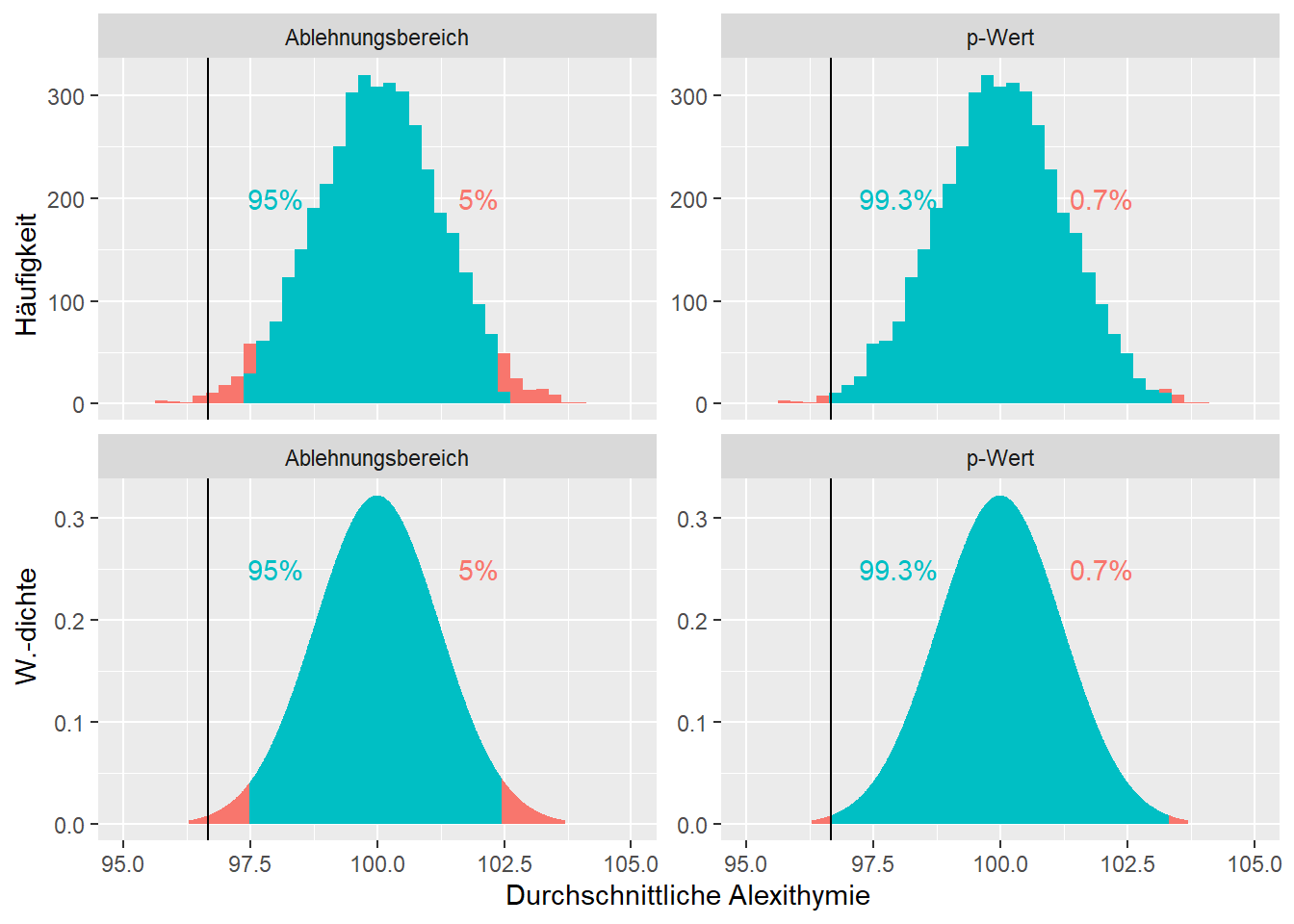
Abbildung 5.4: Oben: Histogramm der simulierten Verteilung der Alexithymie-Mittelwerte; unten: theoretische t-Verteilung; links: Illustration p-Wert; rechts: Illustration Ablehnungsbereich. Die Linie entspricht dem beobachteten Stichprobenmittelwert. Alle Verteilungen basieren auf der Annahme, dass die Nullhypothese wahr ist.
Der \(p\)-Wert, also die Wahrscheinlichkeit, dass der beobachtete Wert oder ein noch extremerer Wert in Richtung der Alternativhypothese resultiert, wird hier aufgrund der zweiseitigen Hypothesenstellung auch zweiseitig ausgelegt. Extremer in Richtung der Alternativhypothese meint hier alle Werte, die weiter weg als der beobachtete Durchschnittswert \(96.7\) vom hypothetischen Erwartungswert \(\mu = 100\) sind. Konkret sind dies alle Werte, welche kleiner als \(96.7\), und alle Werte, welche grösser als \(103.3\) sind (roter Bereich in Abbildung 5.4 oben rechts). Der Anteil der Werte, welche diese Bedingung erfüllen liegt bei \(p = 0.7\%\). Es ist demnach recht unwahrscheinlich, dass die Nullhypothese stimmt und zufällig ein Stichprobendurchschnittswert von \(96.7\) Alexithymie-Punkten herauskommt.
Aufgrund der zweiseitigen Hypothesenstellung beinhaltet auch der Ablehnungsbereich sowohl die tiefsten \(2.5\%\) und höchsten \(2.5\%\), also insgesamt die \(5\%\) extremen Durchschnittswerte. Dies sind alle Werte tiefer als \(97.48\) und alle Werte höher als \(102.45\) (roter Bereich in Abbildung 5.4 oben links). Da das arithmetische Mittel der Stichprobe \(96.7\) im Ablehnungsbereich liegt, liegt hier ein signifikantes Resultat vor bei Signifikanzniveau \(5\%\).
Auch in diesem Fall kann die Verteilung der Stichprobenmittelwerte mit dem zentralen Grenzwertsatz angenähert werden. Es ergeben sich annähernd dieselben Resultate für den \(p\)-Wert (roter Bereich in Abbildung 5.4 unten rechts) und für den Ablehnungsbereich (roter Bereich in Abbildung 5.4 unten links).
Die Psychologin kann nun wie folgt berichten:
Ein Einstichproben-\(t\)-Test ergibt, dass die durchschnittliche Alexithymie (\(M = 96.7\) Punkte, \(SD = 24.4\), \(N = 391\)) sich bei den unter 25-jährigen signifikant vom Populationsdurchschnitt von \(100\) Punkten unterscheidet, \(t(390) = -2.698\), \(p = .007\).
5.2 Weicht der gefundene Durchschnitt stark vom hypothetischen Wert ab?
In einem so berichteten Testresultat sind essenziell zwei Informationen enthalten: (1) was sind die getesteten Hypothesen und (2) wie wahrscheinlich es ist, dass das gefundene Resultat eine Folge der Zufallsstichprobenziehung ist. Was hier noch fehlt ist eine Angabe darüber, wie gross die praktische Relevanz dieses Testresultates ist.
Um eine solche Relevanz zu messen wurde der Begriff der Effektstärke eingeführt. Eine Effektstärke ist eine Zahl ohne Einheit (Meter, Franken, …), welche unabhängig von der Stichprobengrösse ist und nahe bei null liegt, wenn die Nullhypothese nicht abgelehnt wurde.
Wird im Vermögensbeispiel 5.1 die Differenz zwischen geschätztem Erwartungswert und hypothetischem Erwartungswert \[\bar{x} - \mu = 119853 \text{CHF} - 100000 \text{CHF} = 19853\] betrachtet, so fällt auf, dass dieser Wert bereits zwei der oben genannten Eigenschaften aufweist. Tatsächlich ist dieser Wert unabhängig von der Stichprobengrösse und er liegt nahe bei \(0\), wenn das Testresultat nicht signifikant war. Letzteres kann beobachtet werde indem in der Formel (5.1) verschiedene Differenzen eingesetzt werden und mit der Abbildung 4.7 verglichen werden.
Wenn jetzt ein anderer Sozialpsychologe die Auswertung wiederholen würde, aber statt in CHF in Rappen Rp rechnet, dann erhält er den Wert \[\bar{x} - \mu = 11985300 \text{Rp} - 10000000 \text{Rp} = 1985300.\] Dass mit den gleichen Zahlen je nach Einheit eine andere Effektstärke gefunden wird, ist unpraktisch für den Vergleich der Testresultate. Die Lösung in diesem Fall ist diese Differenz durch die geschätzte Standardabweichung zu rechnen. Dies ergibt
- in CHF: \(d = \frac{\bar{x} - \mu}{s} = \frac{119853 \text{CHF} - 100000 \text{CHF}}{88528\text{CHF}} = 0.22\)
- in Rp: \(d = \frac{\bar{x} - \mu}{s} = \frac{11985300 \text{Rp} - 10000000 \text{Rp}}{8852800\text{Rp}} = 0.22 .\)
Mit dieser Formel werden für beide Einheiten derselbe Wert berechnet. Effektiv dient jetzt als Einheit die Standardabweichung: Eine grosse Differenz bei einer grossen Standardabweichung des Merkmals führt zur selben Effektstärke wie eine kleine Differenz bei kleiner Standardabweichung eines Merkmals. Da Menschen sich nicht gewohnt sind Zahlen als Standardabweichungen zu interpretieren hat (J. Cohen 1988) folgende Richtwerte entwickelt:
- \(|d| \approx 0.2\): schwacher Effekt
- \(|d| \approx 0.5\): mittlerer Effekt
- \(|d| \approx 0.8\): starker Effekt
Cohen selbst hat davor gewarnt diese Werte als absolut darzustellen. Vielmehr sollte die Interpretation der Effektstärke vom Forschungsgebiet und dem Messinstrument abhängen. Um im Unterricht eine beurteilbare Praxis zu etablieren, sollen folgende Regeln gelten:
- \(0 < |d| \leq 0.35\): schwacher Effekt
- \(0.35 < |d| \leq 0.65\): mittlerer Effekt
- \(0.65 < |d|\): starker Effekt
Das Berichten der Testresultate wird mit der Effektstärke ergänzt:
Ein Einstichproben-\(t\)-Test ergibt, dass das durchschnittliche Vermögen (\(M = 119853\) CHF, \(SD = 88528\), \(N = 20\)) in diesem Jahr nicht signifikant grösser als \(100'000\) CHF ist, \(t(19) = 1.003\), \(p = .164, d = 0.22\).
Ein Einstichproben-\(t\)-Test ergibt, dass die durchschnittliche Alexithymie (\(M = 96.7\) Punkte, \(SD = 24.4\), \(N = 391\)) sich bei den unter 25-jährigen signifikant vom Populationsdurchschnitt von \(100\) Punkten unterscheidet, \(t(390) = -2.698\), \(p = .007, d = -0.14\).
In beiden Fällen liegt ein schwacher Effekt vor. Der Effekt bei der Alexithymie ist schwächer als der Effekt bei der Vermögensstudie. Der \(p\)-Wert sagt aber aus, dass der Effekt beim Vermögen durch die Zufallsstichprobe zustande gekommen ist, während es bei der Alexithymie unwahrscheinlich ist, dass der Effekt durch die Zufallsstichprobe zustande gekommen ist.
5.3 Testvoraussetzungen
Damit der Einstichproben-\(t\)-Test durchgeführt werden dürfen, müssen einige Voraussetzungen eingehalten werden.
- Das Merkmal muss intervallskaliert sein.
- Die Beobachtungen müssen einer Zufallsstichprobe der Population entsprechen.
- Die Beobachtungen müssen einer Normalverteilung entstammen oder die Anzahl der Beobachtungen muss gross genug sein. Häufig wird die Faustregel mehr als \(30\) Beobachtungen verwendet.
5.4 Übungen
Übung 5.1
Reproduziere das Beispiel Vermögen 5.1 mit Jamovi indem folgende Teilschritte durchgeführt werden:
- Datensatz
05-exm-vermoegen.savinJamovieinladen. - Wähle
Analysen > t-Tests > t-Test mit einer Stichprobe. - Definiere die Hypothese wie im Beispiel und wähle die Testoptionen so, dass du alle Zahlen des Testberichts wiederfindest.
Klicke hier, um deine Lösung zu überprüfen.
Lösung.
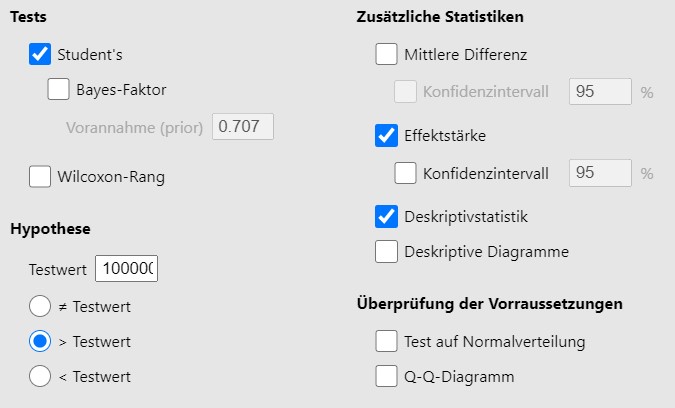
Abbildung 5.5: Jamovi Eingabe.

Abbildung 5.6: Testresultat Einstichproben-t-Test und deskriptive Statistiken.
Übung 5.2
Reproduziere das Beispiel Alexithymie 5.2 mit Jamovi indem folgende Teilschritte durchgeführt werden:
- Datensatz
05-exm-alexithymie.savinJamovieinladen. - Wähle
Analysen > t-Tests > t-Test mit einer Stichprobe. - Definiere die Hypothese wie im Beispiel und wähle die Testoptionen so, dass du alle Zahlen des Testberichts wiederfindest.
Klicke hier, um deine Lösung zu überprüfen.
Lösung.
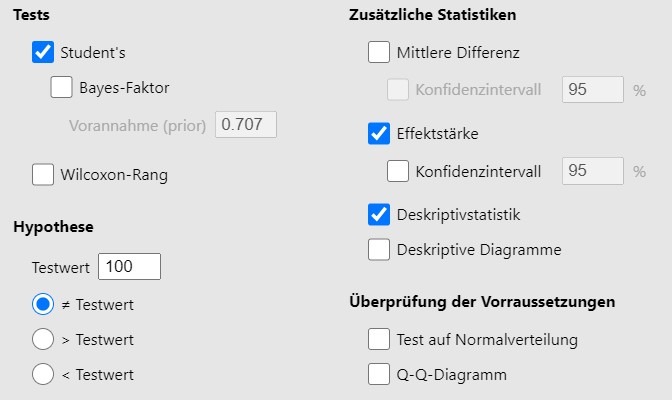
Abbildung 5.7: Jamovi Eingabe.
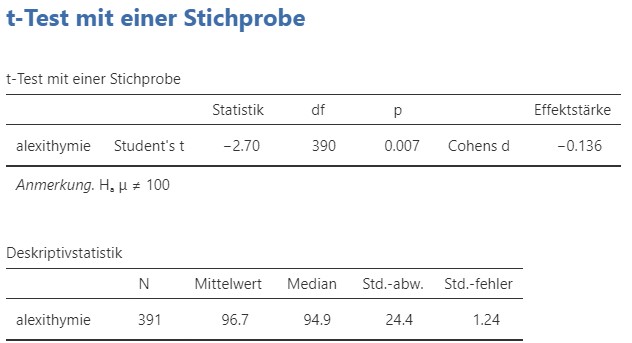
Abbildung 5.8: Testresultat Einstichproben-t-Test und deskriptive Statistiken.
Übung 5.3
Es soll überprüft werden, ob der 24-stündige Tagesrhythmus, auch zirkadianer Rhythmus genannt, des Menschen auch ohne Tageslicht aufrechterhalten wird. Eine solche Untersuchung wird von Czeisler et al. (1999) berichtet. Wir gehen von folgendem fiktiven Versuch aus: Freiwillige werden für vier Tage in einer Kellerwohnung ohne jedes Tageslicht einquartiert. Jede Versuchsperson ist während der vier Tage allein, darf die Wohnung nicht verlassen und erhält keinerlei Hinweise auf die aktuelle Tageszeit. Die Person muss unmittelbar vor dem Zu-Bett-Gehen, einen Knopf betätigen, wodurch die Uhrzeit festgehalten wird. Als Variable wird die Dauer der tageslaenge (in Stunden) zwischen dem Zu-Bett-Gehen am dritten Versuchstag und dem Zu-Bett-Gehen am vierten Versuchstag verwendet. Die erhobenen Daten sind in 05-exr-circadian.sav abgelegt.
- Ohne einen Test durchzuführen, haben die Proband:innen einen anderen zirkadianen Rhythmus als Menschen die nicht am Experiment teilnehmen? Weshalb es hier sinnvoll ist einen statistischen Test zu verwenden?
- Stellen Sie mit einem Einstichproben-t-Test fest, ob der zirkadiane Rhythmus durch das Tageslicht beeinflusst wird. Stellen Sie insbesondere die Hypothesen auf und berichten Sie das Testresultat adäquat.
- Erklären Sie alle Zahlen und Symbole im Testbericht.
Klicke hier, um deine Lösung zu überprüfen.
Lösung. Für diese Übung werden die Daten in Jamovi wie in Abbildung 5.9 analysiert. Das Resultat der Analyse ist in Abbildung 5.10 festgehalten.
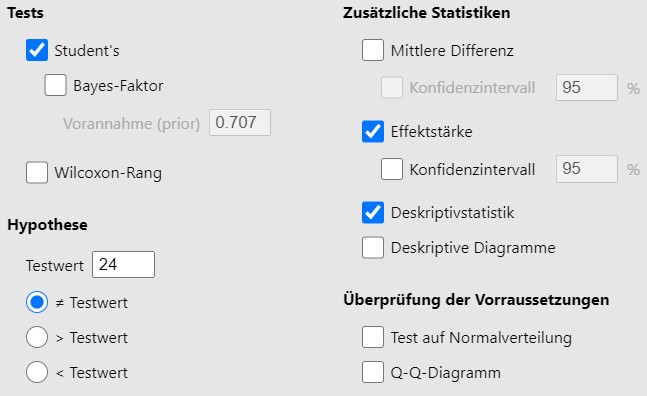
Abbildung 5.9: Jamovi Eingabe.
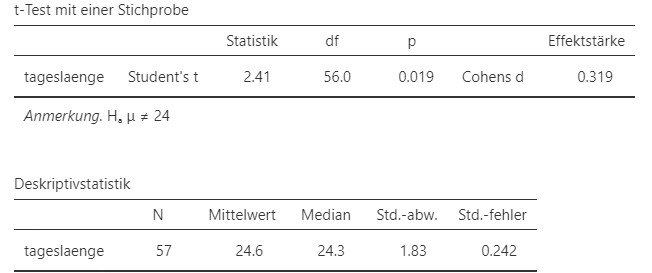
Abbildung 5.10: Jamovi Ausgabe.
- Die Versuchpersonen haben einen durchschnittlichen zirkadianen Rhythmus von \(M = 24.6\) Stunden. Dies ist länger als die regulären \(24\) Stunden. Es ist unklar, ob hier gerade zufällig Personen beobachtet wurden bei welche sich der zirkadiane Rhytmus verlängert. Um die Wahrscheinlichkeit dieses Zufalls zu quantifizieren wird ein statistischer Test durchgeführt.
- Die Nullhypothese geht vom aktuell bekannten aus, also in diesem Fall, dass sich der durchschnittliche zirkadiane Rhythmus unter den Versuchsbedinungen nicht verändert. Der normale zirkadiane Rhythmus ist Sonnenbedingt \(24\) Stunden lang, also wird die Nullhypothese \(H_0: \mu = 24\) Stunden aufgestellt. \(\mu\) ist hier die durchschnittiche Dauer des zirkadianen Rhythmus in der Population. Im Versuch geht es darum festzustellen, ob der normale zirkadiane Rhythmus gehalten wird oder nicht. Ein nicht gehaltener zirkadianer Rhythmus würde bedeuten, dass sich die Tagesdauer verkürzt oder verlängert gegenüber der Nullhypothese. Es ist hier also eine zweiseitige Hypothesenstellung und die Alternativhypothese lautet \(H_1: \mu \neq 24\) Stunden.
Ein Einstichproben-\(t\)-Test ergibt, dass die durchschnittliche Tageslänge (\(M = 24.6\) Stunden, \(SD = 1.8\), \(N = 57\)) unter Experimentalbedingungen sich signifikant von \(24\) Stunden unterscheidet, \(t(56) = 2.41\), \(p = .019, d = 0.319\).
- \(M, SD,\) und \(N\) sind das arithmetische Mittel, die geschätzte Standardabweichung und die Anzahl Beobachtungen der Stichprobe. \(p\) ist die Wahrscheinlichkeit, zufällig den Stichprobenmittelwert oder einen noch extremeren Wert im Sinne der Alternativehypothese zu beobachten, falls die Nullhypothese stimmt. Dieser Wert ist kleiner als \(5\%\). Deswegen wird von einem signifikanten Unterschied der durchschnittlichen Tageslänge zum Erwartungswert gesprochen. \(24\) Stunden ist der Vergleichswert der Nullhypothese. \(t(56)\) bedeutet, dass die Teststatistik \(t\)-verteilt ist mit 56 Freiheitsgraden, sofern die Nullhypothese wahr ist. Mit der aktuellen Stichprobenziehung wurde ein Wert von \(2.41\) realisiert. Dieser Wert ist mit der \(t\)-Verteilung in Abbildung 4.7 zu vergleichen. Der Wert entspricht einer eher unwahrscheinlichen Beobachtung dieser Verteilung. \(d = 0.319\), schliesslich, bezieht sich auf die Effektstärke. Das Testresultat entspricht einem schwachen Effekt.
Übung 5.4
Im Schwimmclub Neustadt erreichen neue Schwimmer nach einem Jahr Training eine Kraul-Schwimmzeit von durchschnittlich \(1.58\) Minuten für \(100\) Meter. Eine Sportstudentin will eine neue Trainingsmethode ausprobieren und herausfinden, ob die Methode bessere Ergebnisse erzielt. Dazu trainiert neue Schwimmer ein Jahr lang mit dieser Methode und misst anschliessend deren Kraul-Schwimmzeit über \(100\) Meter. Die Daten sind in 05-exr-schwimmen.sav abgelegt.
- Wie viele Schwimmer hat die Sportstudentin trainiert?
- Ist die neue Trainingsmethode besser als die bisherige? Erklären Sie die Signifikanz und Relevanz des Experimentresultats.
Klicke hier, um deine Lösung zu überprüfen.
Lösung. Für diese Übung werden die Daten in Jamovi wie in Abbildung 5.11 analysiert. Das Resultat der Analyse ist in Abbildung 5.12 festgehalten.
Abbildung 5.11: Jamovi Eingabe.
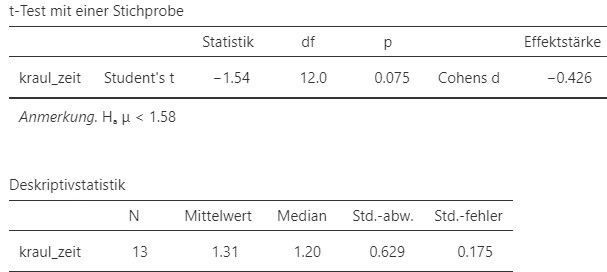
Abbildung 5.12: Jamovi Ausgabe.
- Die Sportstudentin hat \(N = 13\) Schwimmer trainiert.
- Die Forschungsfrage ist hier, ob die neue Trainingsmethode besser ist. Besser meint hier, dass die mit dieser Trainingsmethode trianierten Schwimmer nach dem Training durchschnittlich schneller schwimmen als die anderen. Die Alternativhypothese ist also \(H_1: \mu < 1.58\). Die Nullhypothese sagt genau das Gegenteil davon aus, nämlich, dass die durchschnittliche Schimmzeit mit der neuen Methode gleich bleibt oder sogar noch länger wird \(H_0: \mu \geq 1.58\). Das Testresultat lässt sich wie folgt berichten:
Ein Einstichproben-\(t\)-Test ergibt, dass die durchschnittliche Schwimmzeit (\(M = 1.31\) Minuten, \(SD = 0.63\), \(N = 13\)) mit der neuen Trainingsmethode nicht signifikant tiefer als \(1.58\) Minuten ist, \(t(12) = -1.54\), \(p = .075, d = -0.426\).
Das Testresultat ist nicht signifikant, da der \(p\)-Wert grösser als \(5\%\) ist. Tatsächlich bedeutet \(p = .075\), dass, wenn die Nullhypothese wahr ist, das gefundene Testresultat oder dass die Schwimmer noch schneller sind in \(7.5\%\) zufällig durch die Zufallsstichprobenziehung zustande kommt. Kurz gesagt, das Resulat könnt auch Zufall sein.
Die gefundene Effektstärke ist mittel. Wenn das Resultat nicht zufällig wäre, dann würde die Trainingsmethode immerhin einen mittleren Effekt erzielen. Wenn es tatsächlich einen mittleren Effekt gibt, dann könnte die Sportstudentin das Experiment nochmal mit mehr Probanden wiederholen, um den Effekt auch als statistisch signifikan nachweisen zu können. Falls der gefundene Effekt nur zufällig zustande gekommen ist und er nicht exisitiert, wird auch eine Experimentwiederholung mit mehr Probandinnen immernoch kein signifikantes Testergebnis liefern.
Übung 5.5
Die Firma Pear bringt ein neues Smartphone das F42 der Reihe Supernova X auf den Markt. Das Smartphone ist für Jugendliche im Alter von \(15-20\) Jahre konzipiert. Das Vorgängermodell F41 wurde für durchschnittlich \(300\) CHF verkauft. Um herauszufinden, ob sich die durchschnittliche Zahlbereitschaft des neuen Modells von der Zahlbereitschaft für das alte Modell abweicht, erfragt Pear bei \(70\) Jugendlichen die Zahlbereitschaft. Die Daten stehen unter 04-exr-marktpreisanalyse.sav zur Verfügung.
- Stellen Sie die oben formulierte Hypothese mit mathematischer Schreibweise dar.
- Testen Sie die Hypothese.
- Berichten Sie die Testergebnisse.
- Was bedeuten die Werte Statistik, \(df\), \(p\) und Effektstärke.
- Der Stichprobenmittelwert liegt tiefer als \(300\) CHF. Hätte man bereits hier feststellen können, dass sich die durchschnittliche Zahlungsbereitschaft verändert hat?
Klicke hier, um deine Lösung zu überprüfen.
Lösung. Für diese Übung werden die Daten in Jamovi wie in Abbildung 5.13 analysiert. Das Resultat der Analyse ist in Abbildung 5.14 festgehalten.
Abbildung 5.13: Jamovi Eingabe.
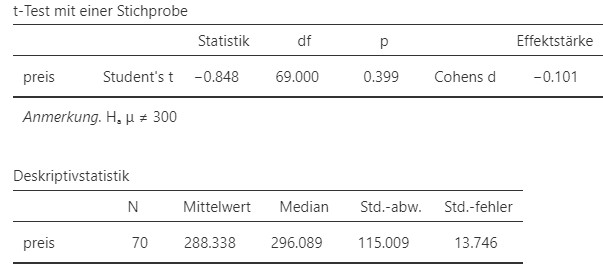
Abbildung 5.14: Jamovi Ausgabe.
- Es gibt zunächst keinen Anhaltspunkt, weshalb sich die Zahlbereitschaft geändert haben sollte. Deshalb ist die Nullhypothese \(H_0: \mu = 300\) CHF, wobei \(\mu\) für den Erwartungswert des Merkmals Preis ist. Pear fragt sich, ob der \(\mu\) von \(300\) abweicht, gibt aber keine Richtung vor. Deshalb wurde \(H_0\) zweiseitig formuliert. Das Gegenteil der Nullhypothese ist die Alternativhypothese \(H_1: \mu \neq 300\) CHF.
- Das Testen erfolgt wie oben in den Bildschirmaufnahmen von
Jamovidargestellt. - Ein Einstichproben-\(t\)-Test ergibt, dass sich die durchschnittliche Zahlbereitschaft (\(M=288.34\) CHF, \(SD = 115.01\), \(N = 70\)) nicht signifikant von \(300\) CHF unterscheidet, \(t(69)= -0.848, p = .399, d = -0.101\).
- Statistik entspricht der beobachteten Teststatistik in der Stichprobe. Der Wert kann im Vergleich zur \(t\)-Verteilung in Abbildung 4.7 gelesen werden. \(-0.848\) ist bei allen dargestellten Verteilungen kein seltener Wert, wenn die Nullhypothese stimmt. Dieser Wert der Statistik deutet also nicht darauf hin, dass die Nullhypothese falsch ist. Die Freiheitsgrade \(df\) bestimmen die genaue Form der t-Verteilung. In Abbildung 4.7 sind die genauen Formen für \(df = 1\), \(df = 4\) und \(df = 9\) dargestellt. Die \(t\)-Verteilung, welche die Verteilung der Mittelwerte am besten abbildet ist die mit \(df = n-1\), wobei \(n\) die Anzahl Beobachtungen ist. Es sind \(70\) Beobachtungen gemacht worden, also ist \(df = 69\). Die \(t\)-Verteilung sieht in diesem Fall ungefähr aus wie die Normalverteilung in Abbildung 4.7. Der \(p\)-Wert von \(0.399\) bedeutet, dass die Wahrscheinlichkeit diesen Stichprobenmittelwert oder einen extremeren im Sinne der Alternativhypothese bei \(39.9\%\) liegt und damit ziemlich wahrscheinlich ist, gegeben dass die Nullhypohthese wahr ist. Auch dies reflektiert also, dass aufgrund der Stichprobe nicht geschlossen werden kann, dass der Erwartungswert von \(300\) CHF abweicht. Die Effektstärke \(d= -0.101\) ist gemäss Cohen als schwach einzustufen.
- Der Stichprobenmittelwert sagt aus, dass in dieser Stichprobe die Zahlungsbereitschaft nicht gleich war wie für das Modell F41. Diese Aussage ist jedoch limitiert auf die Stichprobe und kann nur auf die Population ausgeweitet werden, wenn ein statistischer Test durchgeführt wurde. Es könnte ja sein, dass es einen Unterschied im Populationsmittelwert gibt, dieser aber aufgrund einer seltenen Zufallsstichprobenziehung nicht offenbar wird.
Übung 5.6
TODO
Klicke hier, um deine Lösung zu überprüfen.
Lösung. TODO
5.5 Test
Übung 5.7 Welche der folgenden Aussagen zum Einstichproben-\(t\)-Test sind wahr, welche falsch?
- Der Einstichproben-\(t\)-Test überprüft, ob der Stichprobenmittelwert einer bestimmten Zahl entspricht.
- Beim Einstichproben-\(t\)-Test ist die Teststatistik \(t\)-verteilt mit \(n-1\) Freiheitsgraden.
- Der \(p\)-Wert ist immer kleiner als das Signifikanzniveau.
- \(H_1: \mu > 50\) ist eine mögliche Formulierung für die Alternativhypothese des Einstichproben-\(t\)-Test.
Klicke hier, um deine Lösung zu überprüfen.
Lösung.
- Falsch
- Richtig
- Falsch
- Richtig
Übung 5.8 In der Schweiz wird empfohlen \(3\) Liter Flüssigkeit pro Tag zu sich zu nehmen. Auf einer Reise in die USA fragt Karin zufällige Leute nach ihrer Flüssigkeitsaufnahme. Die Daten notiert sie im Datensatz 05-exr-drink-usa. Sie will nun testen, ob alle Leute in den USA durchschnittlich mehr Flüssigkeit pro Tag zu sich nehmen, als es in der Schweiz empfohlen ist. Testen Sie die Hypothese einem Einstichproben-\(t\)-Test, stellen Sie dabei Jamovi auf \(3\) Nachkommastellenrundung ein. Welche der folgenden Aussagen sind wahr, welche falsch.
- Die durchschnittliche Flüssigkeitsaufnahme ist in den USA signifikant grösser als in der Schweiz empfohlen.
- Der gefundene Effekt ist gemäss Cohen als gross einzustufen.
- Karin hat \(14\) Personen befragt.
- Die Nullhypothese lautet \(H_0: \mu \leq 3\) Liter.
Klicke hier, um deine Lösung zu überprüfen.
Lösung.
- Richtig
- Falsch
- Falsch
- Richtig
Übung 5.9
TODO
Klicke hier, um deine Lösung zu überprüfen.
Lösung. TODO