Kapitel 9 Zusammenhang dichotomer Merkmale
9.1 Zusammenhang dichotomer Merkmale beschreiben
Beispiel 9.1 (Alkohol und Bildung) Vom Bundesamt für Statistik BFS werden regelmässig Daten zum
Alkoholkonsum in der Schweiz erhoben. Dabei wird ermittelt, welcher
Anteil der Bevölkerung weniger als einmal pro Woche und welcher Anteil
mehr als einmal pro Woche Alkohol konsumiert. Diese Anteile werden
anschliessen für verschiedene Untergruppen ausgewiesen, zum Beispiel für
Leute mit Tertiärbildung und anderem Bildungsabschluss. Es werden hier
also zwei dichotome Merkmale (Bildung: Tertiär/nicht Tertiär und
Alkoholkonsum: mind. 1x / Woche, weniger als 1x / Woche) und deren
Zusammenhang betrachtet. Um diese Anteile abzuschätzen werden
\(1000\) Personen befragt. Der Datensatz ist als 09-exm-alcohol-edu.sav verfügbar.
Im Datensatz wird für jede Person eine Zeile ausgewiesen, siehe Abbildung 9.1.
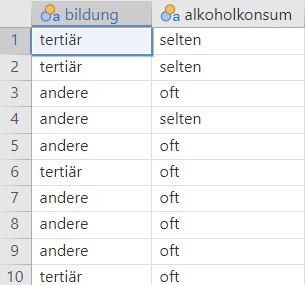
Abbildung 9.1: Daten Alkoholkonsum und Bildung.
Da der Mensch nicht besonders gut darin ist unzählige Zeilen eine Tabelle zu absorbieren, werden die Daten oft in einer Vierfeldertafel zusammengefasst. Die Vierfeldertafel ist eine Kreuztabelle bei welcher die Ausprägungen des einen Merkmals als Spalten und des anderen als Zeilen fungieren. Die Zellen werden dann mit der Anzahl Beobachtungen befüllt, für welche die Ausprägungskombination im Datensatz zutrifft, siehe Abbildung 9.1.

Abbildung 9.2: Vierfeldertafel Alkoholkonsum und Bildung..
Im psychologischen und medizinischen Kontext bezieht sich ein Merkmal oft auf einen schädlichen und einen nicht schädlichen Ausgang. Im Beispiel ist es der Alkoholkonsum. Dieses Merkmal wird Risikovariable genannt. In der Vierfeldertafel kann die Risikovariable die Zeilen oder die Spalten bestimmen. Die Risikovariable wird durch andere Merkmale sogenannte ursächliche Variablen erklärt. Im breiteren statistischen Kontext wird die Risikovariable abhängige Variable und die ursächliche Variable als unabhängige Variable bezeichnet.
Mit Risiko wird die Wahrscheinlichkeit benannt den schädlichen
Ausgang zu erleiden und wird mit dem Anteil des schädlichen Ausgangs an
der Gesamtzahl berechnet.
Das Risiko kann je nach Ausprägung der ursächlichen Variable
unterschiedlich hoch sein. Das Risiko mehr als 1x pro Woche Alkohol zu
konsumieren ist demnach
\(308/378 = 0.815 = 81.5\%\) für
Menschen mit tertiärer Ausbildung und
\(476/622 = 0.765 = 76.5\%\) für
Menschen mit anderer Ausbildung. Das Risiko kann in Jamovi unter
Zellen > Prozentsätze und dann Zeile (wenn das ursächliche Merkmal
die Zeilen bestimmt) oder Spalte (wenn das ursächliche Merkmal die
Spalte bestimmt) angezeigt werden.
Die Risiken für die tertiär und andere Ausbildungen können nun
verglichen werden. Dazu kann die Differenz der beiden Risiken
sogenannte Risikodifferenz (in Jamovi unter
Statistiken > Unterschiede in den Proportionen) betrachtet
werden. Wenn die
Risiken der beiden Gruppen mit \(p_1\) und \(p_2\) bezeichnet werden,
entspricht dies schlicht
\[p_1 - p_2 = 0.815 - 0.765=0.05.\]
Das Risiko mehr als \(1\)x pro Woche Alkohol zu konsumieren ist also
\(0.05 = 5\%\)
höher für Personen mit einem tertiären Bildungsabschluss. Da die Risiken
immer Werte zwischen \(0\) und \(1\) sind, muss dieser Formel nach die
Differenz der Risiken zwischen \(-1\) und \(1\) liegen. Wenn die Differenz
der beiden Risiken \(0\) ist, bedeutet dies, dass die Risiken in beiden
Gruppen gleich gross sind. Je weiter die Differenz der Risiken von \(0\)
weg ist, desto unterschiedlicher sind die Risiken in den zwei Gruppen.
Eine andere Art die Risiken zu vergleichen ist sie ins Verhältnis zu setzen. Dies wird relatives Risiko \[\text{RR} = \frac{p_1}{p_2} = \frac{0.815}{ 0.765}=1.065\] genannt. Das Risiko mehr als \(1\)x pro Woche Alkohol zu konsumieren ist für Personen mit tertiärer Ausbildung also \(1.065\) mal so gross wie für Personen mit anderer Ausbildung. Sind \(p_1\) und \(p_2\) gleich gross, so ist das relative Risiko bei \(1\). Ist \(p_1\) kleiner als \(p_2\), so ist das relative Risiko kleiner als \(1\). Ist \(p_1\) grösser als \(p_2\), so ist das relative Risiko grösser als \(1\). Insgesamt ist das relative Risiko immer eine Zahl zwischen \(0\) und \(+\infty\). Das Tauschen der Gruppennummerierung führt zu einer Umkehr des Wertes rund um \(1\). Wenn im Beispiel also die andere Bildung als Gruppe \(1\) bezeichnet würde, so ist das relative Risiko \[\text{RR} = \frac{p_1}{p_2} = \frac{0.765}{ 0.815}=0.939\]
Hinweis. Das hier die relativen Risiken für die Gruppenneunummerierung fast gleich weit von \(1\) entfernt liegen ist im Normalfall nicht so. Dies kann an folgendem Zahlenbeispiel gesehen werden: \(0.75 / 0.25 = 3\) und umgekehrt \(0.25/0.75 = 0.333\).
Das relative Risiko sagt im Gegensatz zu Risikodifferenz nichts mehr über das absolute Risiko aus. Wenn ein Medikament, zum Beispiel das Risiko einer Psychose von \(1\) aus \(5000\) auf \(1\) aus \(10000\) reduziert, so ist die Risikodifferenz bei \(0.0001 - 0.0002 = -0.01\%\). Das relative Risiko ist in dem Fall jedoch \(0.0001/0.0002 = 50\%\). Wird nun nur das relative Risiko berichtet, könnten Lesende von einem zu grossen Nutzen des Medikaments ausgehen. Es wird deshalb empfohlen immer die Risikodifferenz und das relative Risiko zu berichten.
Die Risikodifferenz und das relative Risiko können nur berechnet werden, wenn die gesamt Anzahl Fälle repräsentativ für die Population ist. Dies ist bei Fall-Kontroll Studien nicht der Fall, wie folgendes Beispiel zeigt. Für solche Studien können weder die Risikodifferenz noch das relative Risiko sinnvoll berechnet werden.
Beispiel 9.2 (Krebs bei Hunden) Hayes et al. (1991) haben sich für den Zusammenhang zwischen malignen Lymphomen
bei Hunden (ugs. bösartiger Lymphdrüsenkrebs) und der Anwendung des
Herbizids \(2, 4\)-Dichlorphenoxyessigsäure in Hausgärten interessiert.
Dabei haben Sie in einer Fall-Kontroll Studie (case-control study) die
Zahlen im Datensatz 09-exm-dog-cancer.sav ermittelt.
Die Daten sind hier bereits in aggregierten Fallzahlen präsentiert, siehe Abbildung 9.3.
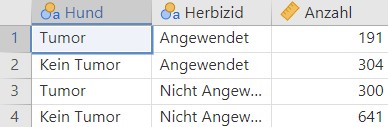
Abbildung 9.3: Daten Malignes Lymphoma bei Hunden.
Um diese Daten korrekt in Jamovi einzulesen, kann unter
Analysen > Häufigkeiten > Kreuztabellen > Unabhängige Stichproben die
Anzahl Fälle bei Anzahl (optional) eingelesen werden. Dies resultiert
in der Vierfeldertafel in Abbildung
9.4.

Abbildung 9.4: Vierfeldertafel Malignes Lymphoma bei Hunden.
Case-control bedeutet, dass Hunde mit Tumor (Fall/case) in einer Tierklinik gegeben waren. Dazu wurde eine gewisse Anzahl (normalerweise zwischen \(1\) bis \(4\) mal so viele wie kranke) gesunde Hunde (Kontroll/control) zufällig ausgewählt. Bei allen Hunden wurde anschliessend ermittelt, ob die Hunde auf einem mit dem entsprechenden Herbizid belasteten Garten Zeit verbracht haben. Da von den Studienautoren bestimmt wurde, wie viele gesunde Hunde ermittelt werden, kann der Anteil der kranken Hunde nicht als Mass für das Vorkommen der Erkrankung in der jeweiligen Gruppe dienen. Es ist hier also nicht aussagekräftig den Anteil kranker Hunde pro Gruppe oder das daraus folgende relative Risiko zu bestimmen.
Stattdessen wird in diesen Fällen das Chancenverhältnis (eng. odds
ratio)
\[OR =\frac{\frac{a}{c}}{\frac{b}{d}} = \frac{a\cdot d}{b\cdot c} = \frac{191\cdot 641}{300\cdot 304} = 1.34\]
berechnet, wobei \(a, b, c\) und \(d\) den Anzahl Fällen in der
Vierfeldertafel von oben nach unten und von links nach rechts
entsprechen. Die Chance (eng. odds) ist dabei eine Art
Wahrscheinlichkeit auszudrücken. Sie ist definiert als Wahrscheinlichkeit, dass ein Ereignis
eintrifft geteilt durch die Wahrscheinlichkeit, dass das Ereignis nicht
eintrifft. Für die Herbizid belasteten Hunde ist die Chance ein Tumor zu
haben also \(a/c=191/304=0.63\) und für die anderen Hunde
\(b/d=300/641=0.47\). Es gilt, je höher die Chance desto höher die
Eintreffwahrscheinlichkeit. Ein Chancenverhältnis von \(1.34\)
schliesslich bedeutet, dass die Chance einen Tumor zu entwickeln für
einen Herbizid belasteten Hund \(1.34\)-mal so hoch ist wie für einen
nicht Herbizid belasteten.
Hinweis.
- Es kann festgestellt werden, dass das Chancenverhältnis unabhängig von der Wahl der ursächlichen und Risikovariable ist \[ OR = \frac{a\cdot d}{b\cdot c} = \frac{a\cdot d}{c\cdot b}.\]
- Für kleine Fallzahlen (Risiko \(<10\%\)) liegt das Chancenverhältnis nahe am relativen Risiko.
- Das Chancenverhältnis lässt, wie das relative Risiko, keinen Schluss über das absolute Risiko zu.
9.2 Zusammenhang dichotomer Merkmale testen
In Jamovi > Analysen > Häufigkeiten > Kreuztabellen > Unabhängige Stichproben > Statistiken > Tests stehen verschiedene Tests zur Verfügung, um zu testen, ob ein in einer Zufallsstichprobe
gefundener Zusammenhang zwischen den Risiken \(p_1\) und \(p_2\) auf die
Risiken in der Population \(\pi_1\) und \(\pi_2\) (sprich ‘pi’) übertragen
werden darf.
9.2.1 \(z\)-Test für den Unterschied zwischen den zwei Anteilen
Wenn die Merkmale unabhängig voneinander sind, dann sollte das Risiko in beiden Gruppen ungefähr gleich gross sein. Dies impliziert auch, dass die Risikodifferenz \(0\) ist. Beim \(z\)-Test für den Unterschied zwischen den zwei Anteilen wird also \(H_0: \pi_1 - \pi_2 = 0\) und damit äquivalent \(H_0: \pi_1 = \pi_2\) getestet. Wird die Nullhypothese verworfen, wird fortan an die Alternativhypothese \(H_1: \pi_1 \neq \pi_2\) geglaubt. Aus Platzgründen werden hier nur die zweiseitigen Hypothesenstellungen erwähnt. Die einseitigen Hypothesenstellungen funktionieren aber anaolg zu den bisher gesehen Tests.
Die Teststatistik für den \(z\)-Test der Risikodifferenz ist
\[z = \frac{p_1-p_2}{\sqrt{\frac{p_1(1-p_1)}{n_1}+\frac{p_2(1-p_2)}{n_2}}} = -1.85,\]
wobei \(n_1\) und \(n_2\) der Anzahl vom Risiko betroffene bzw. nicht
betroffene Beobachtungen darstellen. Wenn die Nullhypothese wahr ist,
ist diese Teststatistik ist standardnormalverteilt. Dies entspricht der
Normalverteilung in Abbildung 4.7. Je grösser die
Differenz der beiden Risiken, desto weiter weg von \(0\) ist die
Teststatistik und desto unwahrscheinlicher ist es, dass die berechnete
Teststatistik aufgrund der Zufallsstichprobenziehung zustande kommt. Der
genaue \(p\)-Wert kann mit Jamovi unter
Tests > z-Test für den Unterschied zwischen den zwei Anteilen
ermittelt werden. Mit \(p = .0649\) kann die Nullhypothese knapp nicht
verworfen werden. Die beiden Anteile \(\pi_1\) und \(\pi_2\) könnten also
gleich sein.
Ein zweiseitiger \(z\)-Test für den Unterschied zwischen den zwei Anteilen ergibt, dass der Anteil der mehr als einmal pro Woche alkoholkonsumierenden Personen mit Tertiärbildung (\(p_1 = 81.5\%\)), nicht signifikant von ebendiesem Anteil der Personen mit anderer Bildung (\(p_2 = 76.5\%\)) unterscheidet, \(z = -1.85, p = .0649\).
9.2.2 \(\chi^2\)-Test
Der \(\chi^2\)-Test (sprich ‘chi-quadrat-test’) ist eine zweite allgemeinere Variante, um den Zusammenhang zwischen zwei dichotomen Merkmalen zu testen. Die Nullhypothese ist wiederum, dass die beiden Merkmale unabhängig voneinander sind.
Um nun die Teststatistik näher verstehen zu können, muss ein kurzer Exkurs in Wahrscheinlichkeitslehre unternommen werden. Diese besagt nämlich, dass wenn zwei Ereignisse A und B unabhängig voneinander auftreten, dann ist die Auftretenswahrscheinlichkeit genau gleich dem Produkt der Wahrscheinlichkeiten der jeweiligen Ereignisse. In Formeln ausgedrückt \[p(A \text{ und }B) \overset{\text{unabhängig}}{=} p(A) \cdot p(B).\]
Auf das Beispiel 9.1 bezogen bedeutet dies, dass wenn Alkoholkonsum und die Ausbildungsart unabhängig voneinander sind, dann entspricht die Wahrscheinlichkeit mehr als \(1\)x pro Woche Alkohol zu konsumieren und eine tertiäre Ausbildung genossen zu haben
\[ p(\text{[alkohol > 1x pro Woche] und tertiär}) = \frac{308}{1000} = 0.308 \]
genau
\[ p(\text{[alkohol > 1x pro Woche]}) \cdot p(\text{tertiär}) = \frac{ 784 }{ 1000} \cdot \frac{ 378 }{ 1000 } = 0.296 \]
entsprechen. Die Zahlen zeigen an, dass dies für diese Stichprobe nicht gegeben ist. Die beobachtete Differenz kann auf eine tatsächliche Abhängigkeit hindeuten oder sich aufgrund der Zufallsstichprobenziehung ergeben haben.
Der \(\chi^2\)-Vierfeldertest vergleicht nun in jeder Zelle \(i\) der Vierfeldertafel die tatsächlich beobachteten Beobachtungen \(o_i\) (observed) mit den erwarteten Beobachtungen \(e_i\) (expected), wenn die Unabhängigkeit gegeben wäre. Letztere berechnet sich durch \(p(A) \cdot p(B) \cdot n\), wobei \(n\) die Gesamtanzahl Beobachtungen ist. Im Beispiel
\[e_1 = p(\text{[alkohol > 1x pro Woche]}) \cdot p(\text{tertiär}) \cdot n = 0.296 \cdot 1000 = 296 \] Je weiter diese Zahl von der beobachteten Zahl abweicht, desto unwahrscheinlicher ist die Unabhängigkeit. Der \(\chi^2\) trägt dem Rechnung, indem die Teststatistik
\[\chi^2 = \sum_{i = 1}^k \frac{(o_i - e_i)^2}{e_i} = 3.41,\] wobei \(k\) hier für die Anzahl Zellen steht. Eine grosse Teststatistik spricht also gegen die Unabhängigkeit.
Wenn die Stichprobenziehung oft wiederholt wird, kann festgestellt werden, dass diese Teststatistik einer bekannten Verteilung, der \(\chi^2\)-Verteilung bei \(df = 1\) Freiheitsgraden folgt. Die \(\chi^2\)-Verteilung ist für verschiedene Freiheitsgrade in Abbildung 9.5 dargestellt. Die Teststatistik des \(\chi^2\)-Vierfeldertests \(3.41\) wird also mit der roten Verteilung in der Abbildung verglichen. Die Werte rechts auf der Abbildung sind seltener und der beobachtete Wert liegt so, dass er zu den \(p = .065\) seltensten Beobachtungen zählt, sofern die Unabhängigkeit gilt. Dies reicht hier gerade nicht, um die Nullhypothese bei Signifikanzniveau \(\alpha = 5\%\) zu verwerfen.
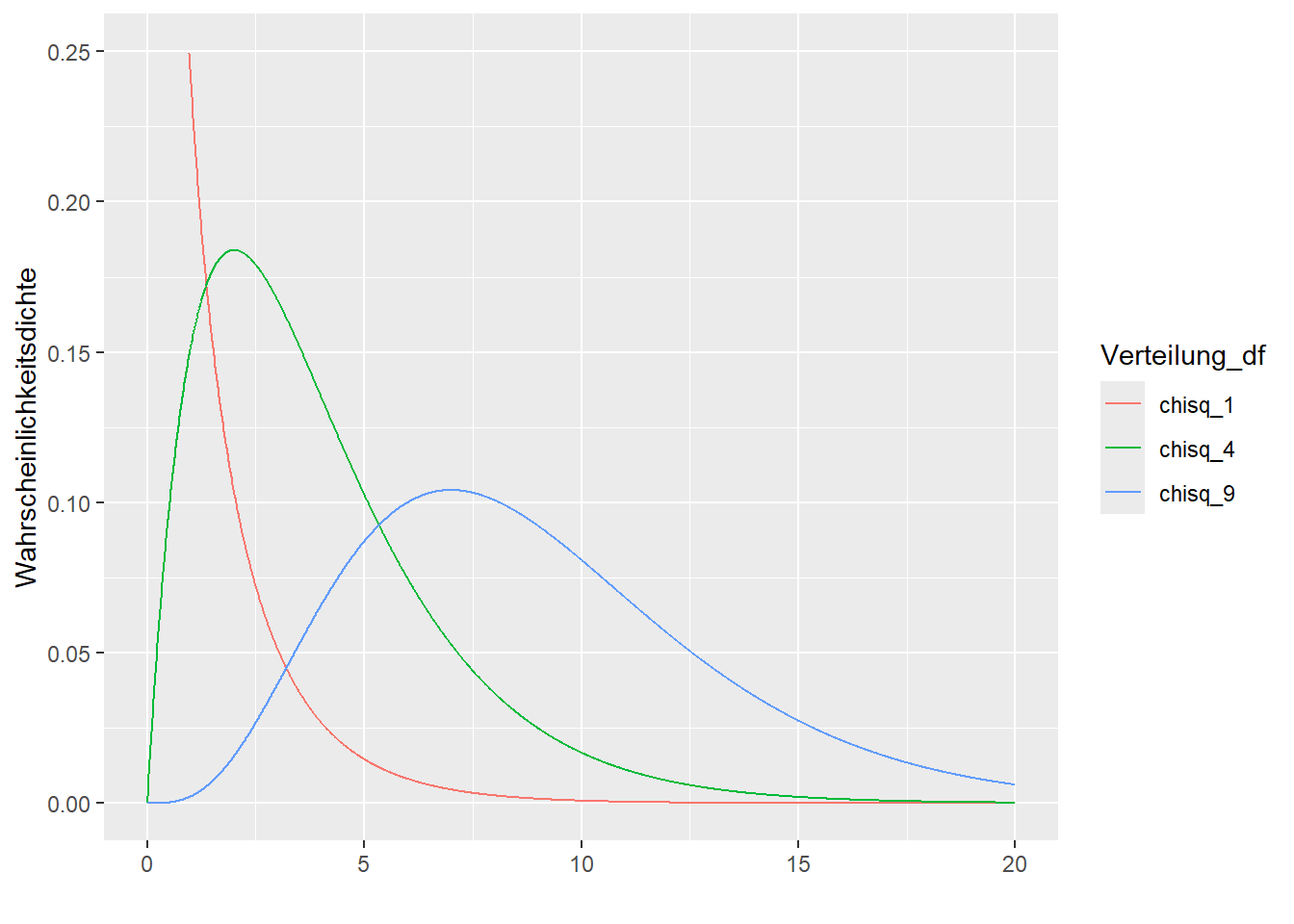
Abbildung 9.5: Chiquadrat-Verteilungen mit 1, 4 und 9 Freiheitsgraden.
Um die Effektstärke des \(\chi^2\)-Tests anzugeben kann Cramérs \(\phi\)
\[\phi = \sqrt{\frac{\chi^2}{n}} = \sqrt{\frac{3.41}{1000}} = 0.06\]
Cramérs \(\phi\) immer grösser als \(0\) und kleiner als \(1\). Je weiter \(\phi\) von \(0\) weg ist, desto stärker sind die Merkmale voneinander abhängig. Da dies auch als Zusammenhangsmass gesehen werden kann wird Cramérs \(\phi\) auch Vierfelderkorrelation genannt. Die Interpretation als Effektstärke erfolgt dabei wir für die Korrelation. Ein Wert von \(0.06\) wird demnach als schwach eingestuft.
Ein \(\chi^2\)-Test ergibt, dass der Alkoholkonsum (mehr/weniger als 1x pro Woche) und Bildung (Tertiär/andere Bildung) (\(p_1-p_2= 0.05\), \(RR = 1.06\)) nicht signifikant abhängig voneinander sind, \(\chi^2 (1) = 3.41, p = .0649, \phi = 0.06\).
Der \(\chi^2\) Test hat für die Vierfeldervariante immer den gleichen \(p\)-Wert wie der Test der Risikodifferenz auf \(0\). Beide Tests basieren auf dem zentralen Grenzwertsatz und dürfen deshalb nur angewendet werden, wenn gewisse Voraussetzungen erfüllt sind. Die Voraussetzung ist, dass insgesamt \(40\) oder mehr Beobachtungen vorliegen müssen. Ist dies nicht der Fall, aber in jeder Zelle ist die Anzahl der erwarteten Beobachtungen bei \(5\) oder grösser, so kann der \(\chi^2\)-Test mit Kontinuitätskorrektur oder Yates-Korrektur verwendet werden \[\chi^2_{Yates} = \sum_{i = 1}^k \frac{(|o_i - e_i| -0.5)^2}{e_i}.\]
In Beispiel sind mit \(n = 1000\) genügend Beobachtungen vorhanden, um ohne die Kontinuitätskorrektur auszukommen. Der Bericht des Tests ist genau gleich wie der Bericht des \(\chi^2\)-Test ausser, dass der Name des Verfahrens geändert wird:
Ein \(\chi^2\)-Test mit Kontinuitätskorrektur ergibt, dass der Alkoholkonsum …
9.2.3 Exakter Test nach Fisher und Yates
Wenn die erwarteten Beobachtungen in mindestens einer Zelle kleiner als \(5\) sind, dann ist die Approximation der Verteilung der Teststatistik durch den \(\chi^2\)-Test sogar mit Kontinuitätskorrektur zu ungenau.
Beispiel 9.3 (Wette: Unterscheiden von Rot- und Weisswein) Nina behauptet, sie kann Rotwein von Weisswein am Geschmack unterscheiden. Sie bereiten ein Experiment vor, um dies zu testen verbinden Nina die Augen. Als Statistiklernende wissen sie, dass es nicht genügt, dass Nina einmal die richtige Weinsorte wählt - dies könnte ja zufällig richtig sein. Stattdessen werden \(5\) Gläser Rotwein und \(4\) Gläser Weisswein vorbereitet und Nina in zufälliger Reihenfolge zum Probieren angeboten. Das Experiment endet mi den Zahlen in Abbildung 9.6.

Abbildung 9.6: Vierfeldertafel Wette Unterschied Rot- und Weisswein.
Da nur wenige Beobachtungen gemacht wurden, kann die Wahrscheinlichkeit eines Ausgangs des Experiments mit Hilfe der hypergeometrischen-Verteilung genau berechnet werden. Die Wahrscheinlichkeit für den Experimentausgang in Abbildung 9.6 entspricht \(p_0 = 0.159\).
Der \(p\)-Wert eines Tests ist bekannterweise die Wahrscheinlichkeit die berechnetet Teststatistik zu beobachten oder eine unwahrscheinlichere Situation im Sinne der Alternativhypothese. Nina will zeigen, dass Sie Rotwein und Weisswein richtig erkennen kann, was der Alternativhypothese entspricht. Ihr ist gedient, wenn sie Rot- und Weisswein überzufällig oft richtig erkennt, nicht aber, wenn sie den Rot- und Weisswein unterdurchschnittlich oft richtig erkennt. Die Alternativhypothese ist also hier einseitig formuliert zu verstehen.
Um dem zweiten Teil dieser Definition des \(p\)-Werts gerecht zu werden, werden nun andere, unwahrscheinlichere Experimentausgänge im Sinne der Alternativhypothese bewertet. Um dies zu erreichen, wird hier angenommen, dass in jedem Fall die Randsummen immer gleichbleiben (also \(5\) für ist Rotwein, \(4\) für ist Weisswein, \(5\) für sagt Rotwein und \(4\) für sagt Weisswein). Wenn ist und sagt unabhängig voneinander ist und Nina also die Weinfarben nicht auseinanderhalten kann, dann wäre es unwahrscheinlicher, wenn sie alle \(5\) Rotweine als solche erkannt hätte. Wenn die Randsummen gleich gehalten werden, entspricht dies der Situation in Abbildung 9.7. Die Wahrscheinlichkeit für diese Situation ist \(p_1 = 0.008\).
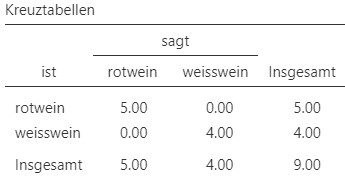
Abbildung 9.7: Vierfeldertafel Wette Unterschied Rot- und Weisswein.
Grundsätzlich können hier noch weitere Situationen aufgezählt werden. Im Beispiel sind mit der eben beschriebenen Situation und der ursprünglichen Situation jedoch die Alternativen erschöpft: Es kann nicht sein, dass Nina \(6\)-mal Rotwein richtig voraussagt, wenn sie insgesamt nur \(5\)-mal Rotwein sagt.
Nun werden die Wahrscheinlichkeiten aller Situation aufsummiert, \(p = p_0 + p_1 + \ldots = 0.159+0.008 =0.167\). Da mit diesem Vorgehen genau der Definition des \(p\)-Wertes gefolgt wurde, stellt dieses \(p\) nun auch einen \(p\)-Wert dar. Der dazugehörige Test wird exakter Test nach Fisher und Yates oder einfach Fisher-Yates-Test genannt.
Ein einseitiger exakter Test nach Fisher und Yates ergibt, dass das Ansagen der Weinsorte von Nina nicht signifikant von der tatsächlichen Weinsorte abhängt, \(p = .167\).
Hinweis.
- Der Test ist exakt, weil hier die Wahrscheinlichkeiten genau bestimmt wurden. Bei allen anderen bislang gesehenen Tests wird die Wahrscheinlichkeit über eine Verteilung angenähert. Diese Annäherung ist theoretisch nur richtig, wenn unendlich viele Beobachtungen gemacht werden, weshalb diese Art Test auch asymptotisch genannt wird. In der Praxis wird jedoch festgestellt, dass asymptotische Tests bereits für eine kleine Anzahl Beobachtungen (z. B. \(50\) für den Einstichproben-\(t\)-Test) hinreichend genau sind.
- Da für den exakten Test nach Fisher und Yates die Wahrscheinlichkeiten direkt berechnet werden, wird keine Teststatistik verwendet.
- Um eine zweiseitige Alternative testen zu können, müsste der Test Wahrschinlichkeiten von gleichen oder extremeren Situationen in die andere Richtung dazusummieren. Solche Situationen können nicht immer eindeutig bestimmt werden. Im Beispiel wäre eine Möglichkeit, dass Nina \(1\)-mal Rotwein sagt, wenn es Rotwein ist. Eine andere Möglichkeit wäre, dass Nina 1-mal Weisswein sagt, wenn es Weisswein ist. Grundsätztlich wird hier nur der einseitige extakte Test nach Fisher verlangt.
9.3 Übungen
Übung 9.1
Viscidi et al. (2013) wollten herausfinden wie sich das Alter (Kind bis \(10\)
Jahre / Jugendlich älter als \(10\) Jahre) auf das Auftreten von Epilepsie
bei Menschen mit einer Autismus-Spektrum-Störung auswirkt. Dafür wurden
zufällig 5185 Menschen mit
Autismus-Spektrum-Störung zu ihrem Alter und dem Auftreten von Epilepsie
befragt. Simulierte Daten befinden sich im Datensatz
09-exr-autism-epilepsy.sav.
- Lässt das Studiendesign das Berechnen des relativen Risikos zu?
- Berechnen Sie das Risiko an Epilepsie zu leiden in den beiden Altersgruppen und anschliessend die Risikodifferenz, das relative Risiko und das Chancenverhältnis.
- Sichern Sie die Risikodifferenz zweiseitig gegen Null ab und berichten Sie das Ergebnis.
- Testen Sie den Zusammenhang mit einem \(\chi^2\)-Test und berichten Sie das Ergebnis. Schätzen und interpretieren Sie auch die Effektstärke.
Klicke hier, um deine Lösung zu überprüfen.
Lösung. Zuerst wird der Datensatz mit Jamovi eingelesen und die
Analyseparameter werden gesetzt, siehe Abbildung
9.8.
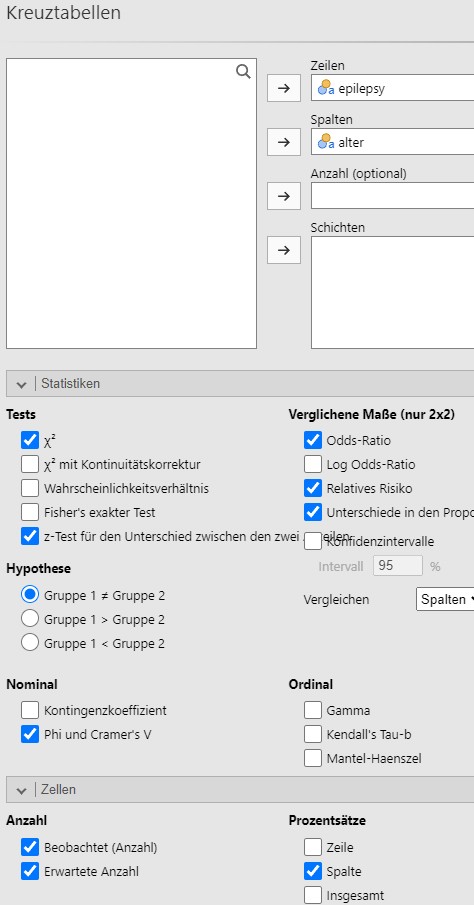
Abbildung 9.8: Jamovi Eingabe.
Dies produziert das Analyseergebnis in Abbildung 9.9.
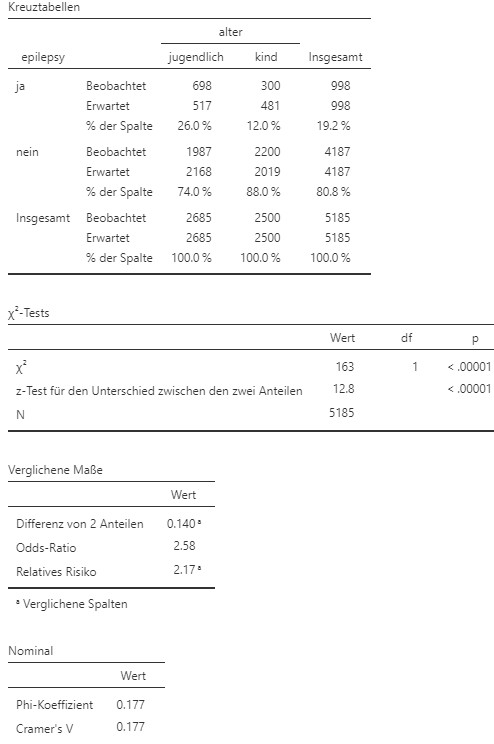
Abbildung 9.9: Jamovi Ausgabe.
Damit kann die Frage nun beantwortet werden:
- Ja die Leute wurden zufällig ausgewählt und nicht aufgrund der Präsenz oder Absenz eines Epilepsieanfalls.
- Das Risiko an Epilepsie zu leiden liegt bei \(12.0\%\) für Kinder und \(26.0\%\) für Jugendliche. Die Risikodifferenz liegt bei \(14.0\%\). Das Risiko ist für Jugendliche \(14.0\%\) höher als für Kinder. Das relative Risiko liegt bei \(2.17\). Das Risiko ist für Jugendliche also \(2.17\)-mal so hoch wie für Kinder. Das Chancenverhältnis liegt bei \(2.58\). Die Chance an Epilepsie zu leiden ist für Jugendliche also \(2.58\)-mal so hoch wie für Kinder.
Ein zweiseitiger \(z\)-Test für den Unterschied zwischen zwei Anteilen ergibt, dass sich der Anteil der autistischen Jugendlichen mit Epilepsieanfällen (\(p_1 = 26.0\%\)), signifikant vom Anteil der Kinder mit Epilepsieanfällen (\(p_2 = 12.0\%\)) unterschiedet, \(z = 12.8, p < .001\).
Ein \(\chi^2\)-Test ergibt, dass das Auftreten von Epilepsieanfällen (ja/nein) und die Alterskategorie (Jugendlich/Kind) (\(p_1-p_2= 0.14\), \(RR = 2.17\)) signifikant voneinander abhängig sind, \(\chi^2 (1) = 163.16\), \(p < 0.001\), \(\phi = 0.18.\) Der Effekt ist schwach.
Übung 9.2
Eine Psychologin hat versucht herauszufinden, wie sich das
Trainingsverhalten (oft/selten) auf depressive Stimmungen auswirkt. Dazu
hat sie in einem Experiment
\(77\) zufällige Leute befragt und die Resultate in Datensatz 09-exr-depression-training.sav erhalten.
- Welches ist die Risikovariable?
- Wie gross sind die Risiken in den beiden Gruppen? Wie gross ist die Risikodifferenz, das relative Risiko und das Chancenverhältnis? Welche Wirkung hat das Trainingsverhalten auf das Risiko eine Depression zu erleiden?
- Sind die Variablen Depression und Trainingsverhalten voneinander abhängig, wenn bei \(\alpha = 5\%\) mit einem \(\chi^2\)-Test getestet wird?
- Ist die Kontinuitätskorrektur angebracht? Wie gross ist der Unterschied zwischen der Teststatistik mit und ohne Yates-Korrektur hier?
- Wie gross ist die Vierfelderkorrelation zwischen den beiden Variablen? Interpretieren Sie den Zusammenhang.
Klicke hier, um deine Lösung zu überprüfen.
Lösung. Zuerst wird der Datensatz mit Jamovi eingelesen und die
Analyseparameter werden gesetzt, siehe Abbildung
9.10.
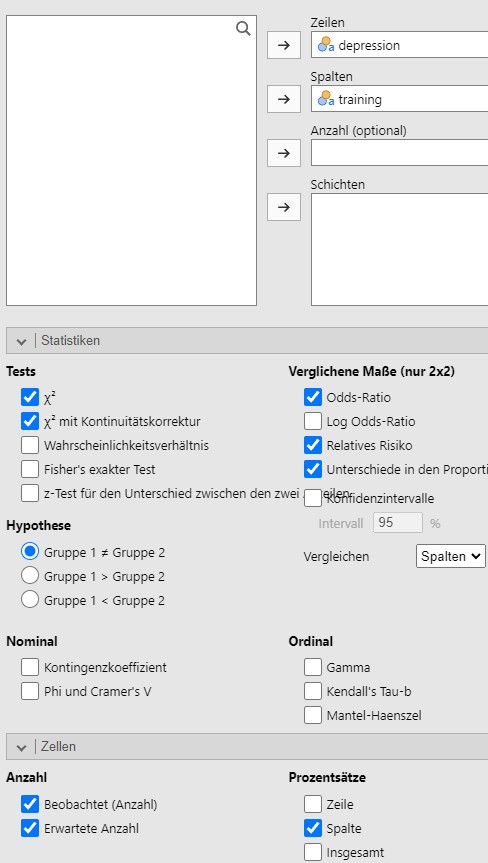
Abbildung 9.10: Jamovi Eingabe.
Dies produziert das Analyseergebnis in Abbildung 9.11.
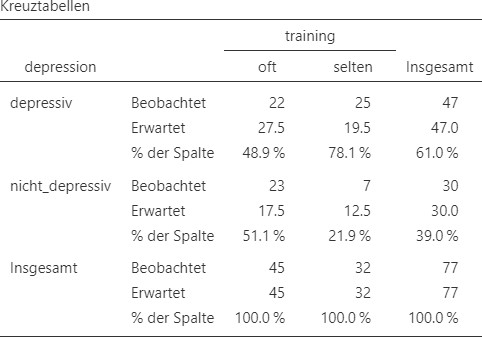
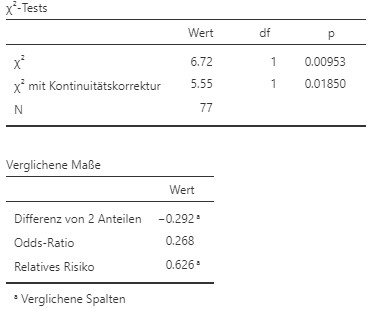
Abbildung 9.11: Jamovi Ausgabe.
Damit kann die Frage nun beantwortet werden:
- Die Risikovariable ist hier eine Depression zu haben oder nicht.
- Das Risiko beträgt \(p_1 = 48.9\%\) in der oft trainierenden Gruppe. In der anderen Gruppe liegt das Risiko bei \(p_2 =78.1 \%\). Die Risikodifferenz liegt bei \(-29.2\%\), das relative Risiko bei \(0.626\) und das Chancenverhältnis bei \(0.268\). Oft zu trainineren hat einen protektive Wirkung auf das Risiko an einer Depression zu erkranken.
Ein \(\chi^2\)-Test ergibt, dass das Auftreten von Depression (ja/nein) und die Trainingsfrequenz (oft/selten) (\(p_1-p_2= -0.29\), \(RR = 0.63\)) signifikant voneinander abhängig sind, \(\chi^2 (1) = 6.72\), \(p = .01\), \(\phi = 0.3.\) Der Effekt ist mittel.
- Die Kontinuitätskorrektur ist nicht nötig da mit \(77\) Beobachtungen mehr als \(40\) Beobachtungen vorliegen. Die Teststatistik ohne Kontinuitätskorrektur ist \(\chi(1)^2 = 6.72\) und mit Kontinuitätskorrektur \(\chi(1)^2 = 5.55\). Beide Testverfahren deuten auf eine signifikante Abhängigkeit hin.
- Die Vierfelderkorrelation entspricht der Effektstärke \(\phi = 0.3.\) Die Korrelation ist mittel. Die Richtung des Zusammenhangs muss aus den Anteilen abgelesen werden. Je eher jemand unter Depression leidet, desto eher trainiert jemand selten.
Übung 9.3
Um den Zusammenhang zwischen Rauchen und Lungenkrebs zu analysieren
haben Forschende in einer Studie \(200\) an Lungenkrebs erkrankte und
\(397\) nicht an Lungenkrebs erkrankte Menschen zu ihrem Rauchverhalten
(rauchen ja oder nein) befragt. Die Forschenden haben die Daten im
Datensatz 09-exr-cancer-smoking.sav aggregiert zur
Verfügung gestellt. Lose nach Matos et al. (1998).
- Handelt es sich um eine Fall-Kontroll (case-control) Studie.
- Identifizieren Sie abhängige und unabhängige Variable. Wie gross ist das Risiko an Lungenkrebs zu erkranken für rauchende und nicht rauchende Menschen? Können hier die Risikodifferenz, das RR und der OR verwendet werden, um den Zusammenhang zu beschreiben?
- Wie gross ist das Chancenverhältnis und was heisst das für die rauchenden Menschen?
- Ist das Lungenkrebsrisiko vom Rauchverhalten abhängig? Führen Sie einen \(\chi^2\)-Test durch.
Klicke hier, um deine Lösung zu überprüfen.
Lösung. Zuerst wird der Datensatz mit Jamovi eingelesen und die
Analyseparameter werden gesetzt, siehe Abbildung
9.12.
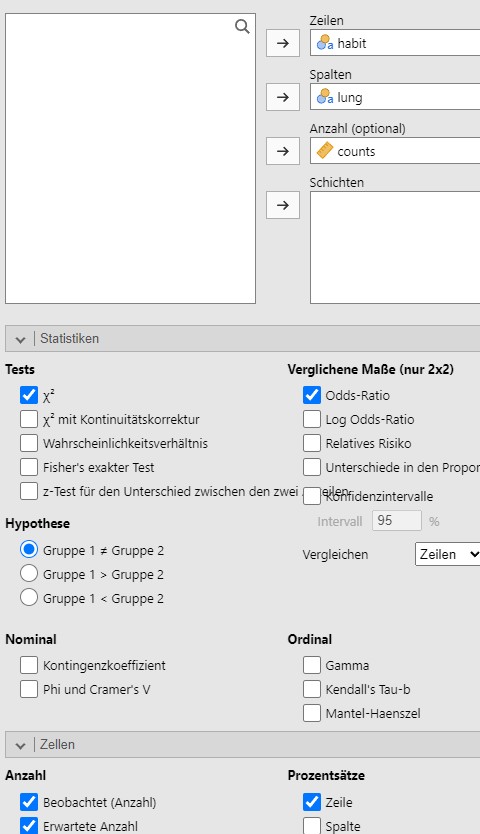
Abbildung 9.12: Jamovi Eingabe.
Dies produziert das Analyseergebnis in Abbildung 9.13.
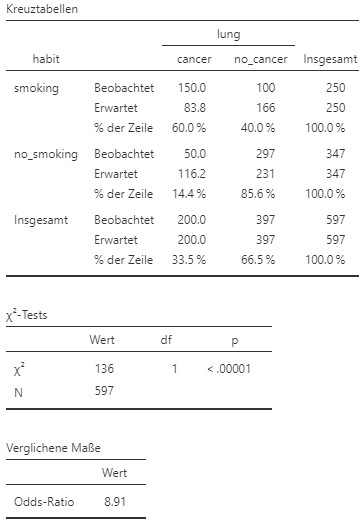
Abbildung 9.13: Jamovi Ausgabe.
Damit kann die Frage nun beantwortet werden:
- Ja. Die Forschenden haben bestimmt wie viele erkrankte und gesunde Personen sie für die Studie anschreiben.
- Die abhängige Variable oder Risikovariable ist hier die Erkrankung an Lungenkrebs. Die ursächliche oder unabhängige Variable ist das Rauchverhalten. Da in der Studie der Anteil gesunder und erkrankter Menschen im Vorherein festgelegt wurde, ist eine Berechnung des Risikos nicht sinnvoll. Daraus folgend ist auch die Risikodifferenz oder das relative Risiko nicht sinnvoll. Der OR kann immer verwendet werden, um den Zusammenhang zu beschreiben.
- Das Chancenverhältnis liegt bei \(8.91\). Das bedeutet für die rauchenden Leute ist die Chance an Lungenkrebs zu erkanken \(8.91\)-mal so hoch wie für nicht rauchende.
Ein \(\chi^2\)-Test ergibt, dass das Auftreten von Lungenkrebs (ja/nein) und das Rauchverhalten (ja/nein) (\(OR = 8.91\)) signifikant voneinander abhängig sind, \(\chi^2 (1) = 135.57\), \(p < 0.001\), \(\phi = 0.48.\) Der Effekt ist stark.
Übung 9.4
Eine Freundin von Ihnen behauptet, dass Sie Bio-Milch und nicht
Bio-Milch am Geschmack unterscheiden kann. Sie geben ihr \(9\)-mal
Bio-Milch zu trinken und \(6\)-mal nicht Bio-Milch zu trinken bei einem
doppel-blind Test. Es entstehen die Daten in
09-exr-bio-milch.sav.
- Wie hoch ist der Anteil der richtig erkannten Bio-Milch und nicht Bio-Milch Proben?
- Welcher Test ist bei dieser Datenlage angebracht, um zu testen, ob die Freundin tatsächlich Bio und nicht Bio-Milch am Geschmack unterschieden kann?
- Konnte die Freundin ihre Behauptung im Experiment nachweisen? Führen Sie den angebrachten Test durch und berichten Sie das Resultat inklusive Effektstärke.
- Skizzieren Sie eines der im Test implizit verwendeten Alternativszenarien.
Klicke hier, um deine Lösung zu überprüfen.
Lösung. Zuerst wird der Datensatz mit Jamovi eingelesen und die
Analyseparameter werden gesetzt, siehe Abbildung
9.14.
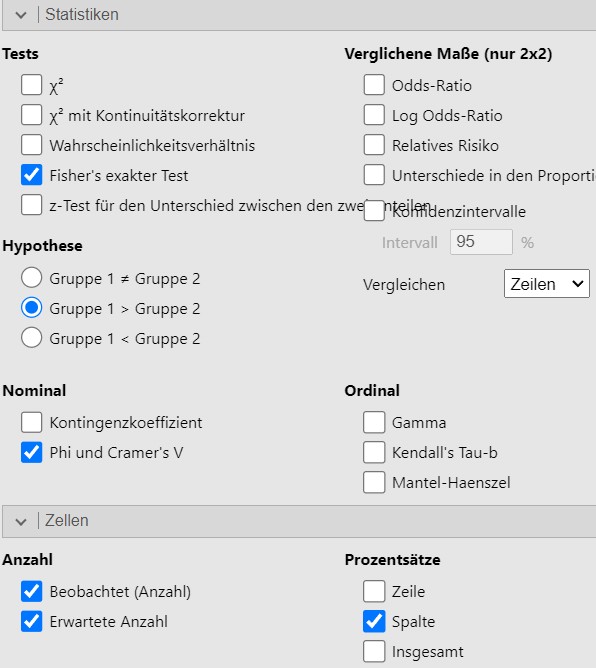
Abbildung 9.14: Jamovi Eingabe.
Dies produziert das Analyseergebnis in Abbildung 9.13.
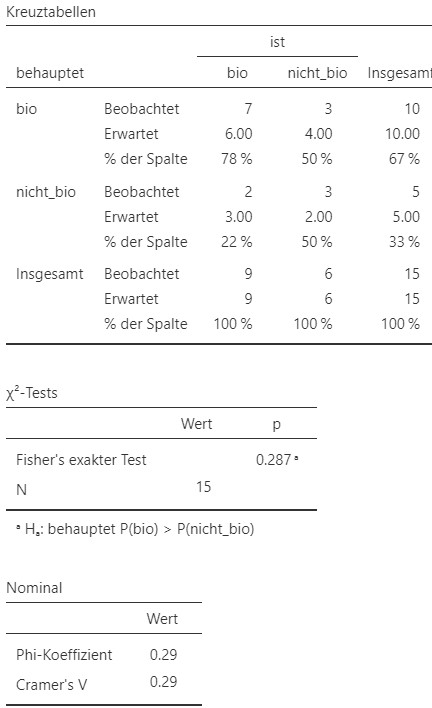
Abbildung 9.15: Jamovi Ausgabe.
Damit kann die Frage nun beantwortet werden:
- Der Anteil der richtig erkannten Bio-Milch Proben ist \(p_1 = 78\%\). Der Anteil der richtig erkannten nicht Bio-Milch Proben ist \(p_2 = 50\%\).
- Insgesamt werden \(n = 15\) Proben beurteilt. Da dies kleiner ist als \(40\) kommt der \(\chi^2\)-Test nicht in Frage. Die erwarteten Beobachtungen sind zum Teil unter \(5\). Dies bedeutet, dass die Kontinuitätskorrektur auch nicht verwendet werden darf. Es bleibt der exakte Test nach Fisher und Yates als einzige mögliche Option.
- Achtung der exakte Test nach Fisher und Yates wird einseitig durchgeführt, da es nicht interessiert, ob die Freundin die Bio-Milch unterdurchschnittlich gut erkennen kann.
Ein einseitiger exakter Test nach Fisher und Yates ergibt, dass das Ansagen der Milchsorte der Freundin nicht signifikant von der tatsächlichen Milchsorte abhängt, \(p = .287\), \(\phi = 0.29\). Der Effekt ist mittel.
- Der Test belässt die Randsummen fixiert. Dies bedeutet, dass insgesamt immer gleich viele Proben jeder Milchsorte vorausgesagt werden und immer insgesamt gleich viele Porben von jeder Milchsorte gegeben werden. Der Test verwendet Alternativszenarien, welche extremer sind im Sinne der Alternativhypothese. Die Alternativhypothese ist, dass die Freundin Bio- von nicht Bio-Milch unterscheiden kann. Extremer bedeutet also hier, dass die Freundin mehr Proben richtig erkennt, zum Beispiel, \(8\) statt der \(7\) Bio-Milch Proben. Da die Randsummen gleichbleiben, bedeutet dies, dass die Freundin demnach \(2\) statt \(3\) nicht Bio-Milch Proben als Bio-Milch einstuft und \(1\) statt \(2\) Bio-Milch Porben als nicht Bio-Milch einstuft. Demnach ergibt sich, dass sie auch \(4\) statt \(3\) nicht Bio-Milch Proben als nicht Bio-Milch erkennt. Andere Szenarien, bei welchen \(9\) respektive \(10\) Bio-Milch Proben richtig erkannt werden.
Übung 9.5
K. Cohen et al. (2022) haben bei über \(65\)-jährigen den Zusammenhang zwischen Atemnot und einer SARS-CoV-2-Historie analysiert. Fiktive Daten dazu sind unter
09-exr-covid-atemnot.sav abgelegt.
- Wie gross ist das Risiko unter Atemnot zu leiden mit und ohne einer SARS-CoV-2 Historie? Identifizieren Sie zuerst ursächliche und Risikovariable.
- Wie gross ist die Risikodifferenz, das relative Risiko und das Chancenverhältnis?
- Welche Menschen stellen die Population dar?
- Lässt sich der Zusammenhang auf die Population ausweiten? Führen Sie einen Test durch und interpretieren Sie die Effektstärke.
Klicke hier, um deine Lösung zu überprüfen.
Lösung. Zuerst wird der Datensatz mit Jamovi eingelesen und die
Analyseparameter werden gesetzt, siehe Abbildung
9.14.
Abbildung 9.16: Jamovi Eingabe.
Dies produziert das Analyseergebnis in Abbildung 9.17.
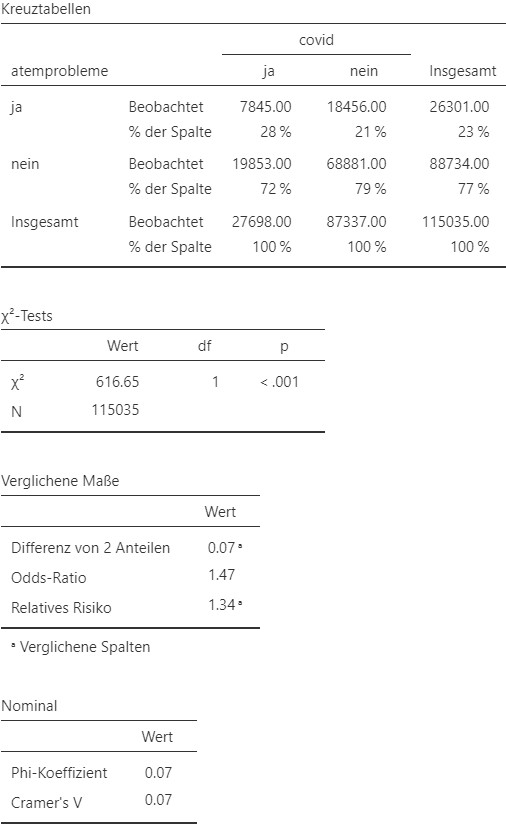
Abbildung 9.17: Jamovi Ausgabe.
Damit kann die Frage nun beantwortet werden:
- Das untersuchte schädliche Ereignis ist hier die Atemnot. Als ursache wird die vorhergehende SARS-CoV-2-Infektion betrachtet. Das Risiko nach einer SARS-CoV-2-Infektion an Atemnot zu leiden, liegt bei \(28.3 \%\). Das Risiko ohne vorhergehende SARS-CoV-2-Infektion an Atemnot zu leiden, liegt bei \(21.1 \%.\)
- Die Risikodifferenz liegt demnach bei \(7.2\%\), das relative Risiko bei \(1.34\) und das Chancenverhältnis bei \(1.47\). Eine vorhergehende SarsCov2 Infektion ist also mit einem erhöhten Risiko der Atemnot assoziiert.
- Da für die Studie nur über \(65\)-jährige beobachtet wurden, sind alle über \(65\)-jährigen die Population. Im besten Fall sind die Studienergebnisse aussagekräftig für diese Gruppe. Im schlimmsten Fall sind sie nur aussagekräftig für die gezogene Stichprobe an über \(65\)-jährigen.
Ein \(\chi^2\)-Test ergibt, dass das Auftreten von Atemnot (ja/nein) und die SARS-CoV-2-Historie (vorhanden/nicht vorhanden) (\(OR = 1.47\)) signifikant voneinander abhängig sind, \(\chi^2 (1) = 616.65\), \(p < 0.001\), \(\phi = 0.07.\) Der Effekt ist schwach.