Kapitel 2 Intervallskalierte Merkmale
2.1 Was ist ein intervallskaliertes Merkmal?
Ein Merkmal ist dann intervallskaliert, wenn die einzelnen Beobachtungen in eine natürliche Reihenfolge gebracht werden können und zwischen dem tiefsten und höchsten möglichen Wert, alle erdenklichen Zwischenwerte möglich sind.
Beispiel 2.1 (Körpertemperatur) Ein Beispiel für ein intervallskaliertes Merkmal ist die Körpertemperatur. Beobachtungen der Körpertemperatur einer lebenden Person sind Werte zwischen ungefähr 10°C und 42°C. Es ist möglich zu sagen, dass eine Person mit 40°C Körpertemperatur eine höhere Temperatur hat als eine mit 38°C Körpertemperatur. Ausserdem sind alle erdenklichen Zwischenwerte möglich, so auch dass bei einer Person eine Körpertemperatur von 37.821239°C gemessen wird.
Beispiel 2.2 (Intelligenzquotient) Ein weiteres Beispiel für ein intervallskaliertes Merkmal ist der Intelligenzquotient IQ. Der IQ bewegt sich normalerweise zwischen 50 und 150, eine Person mit einem IQ von 105 hat einen höheren IQ als eine Person mit einem IQ von 103. Ausserdem sind IQ-Werte von 103.12 oder 118.9182 durchaus möglich.
Klicke hier, falls dir verhältnisskalierte Merkmale bekannt sind
Die folgende Diskussion ist auch auf verhältnisskalierte Merkmale anwendbar. Letztere sind intervallskalierte Merkmale, welche einen absoluten Nullpunkt aufweisen.2.2 Wie kann ein intervallskaliertes Merkmal beschrieben werden?
Beispiel 2.3 (Körpertemperatur Enten) Eine Veterinärin möchte herausfinden, welche Körpertemperatur Enten aufweisen. Dazu untersucht sie 40 Enten und misst die Körpertemperaturen 42.01, 41.72, 41.51, 41.52, 41.5, 41.6, 41.46, 41.81, 42.14, 41.82, 42.06, 41.53, 41.66, 41.65, 41.46, 41.48, 41.92, 41.58, 41.32, 41.58, 41.81, 41.7, 41.62, 41.52, 41.89, 41.53, 41.67, 41.43, 42.18, 41.52, 41.82, 41.96, 41.8, 41.54, 41.88, 41.69, 41.92, 41.35, 41.07 und 41.67.
Für einen Menschen ist es schwierig direkt aus der Sichtung dieser Zahlen zu begreifen, welche Körpertemperatur Enten haben. Ein Mensch kann sich jedoch helfen, indem er die Zahlen zusammenfasst.
2.2.1 Verteilung
Um die Zahlen zusammenzufassen, kann die Veterinärin zum Beispiel Temperaturabschnitte von \(0.2\)°C betrachten und zählen wie viele Beobachtungen sie in den jeweiligen Abschnitten gemacht hat. Diese Zähldaten können tabellarisch oder grafisch mit einem Balkendiagramm dargestellt werden. Letzteres wird ein Histogramm genannt.
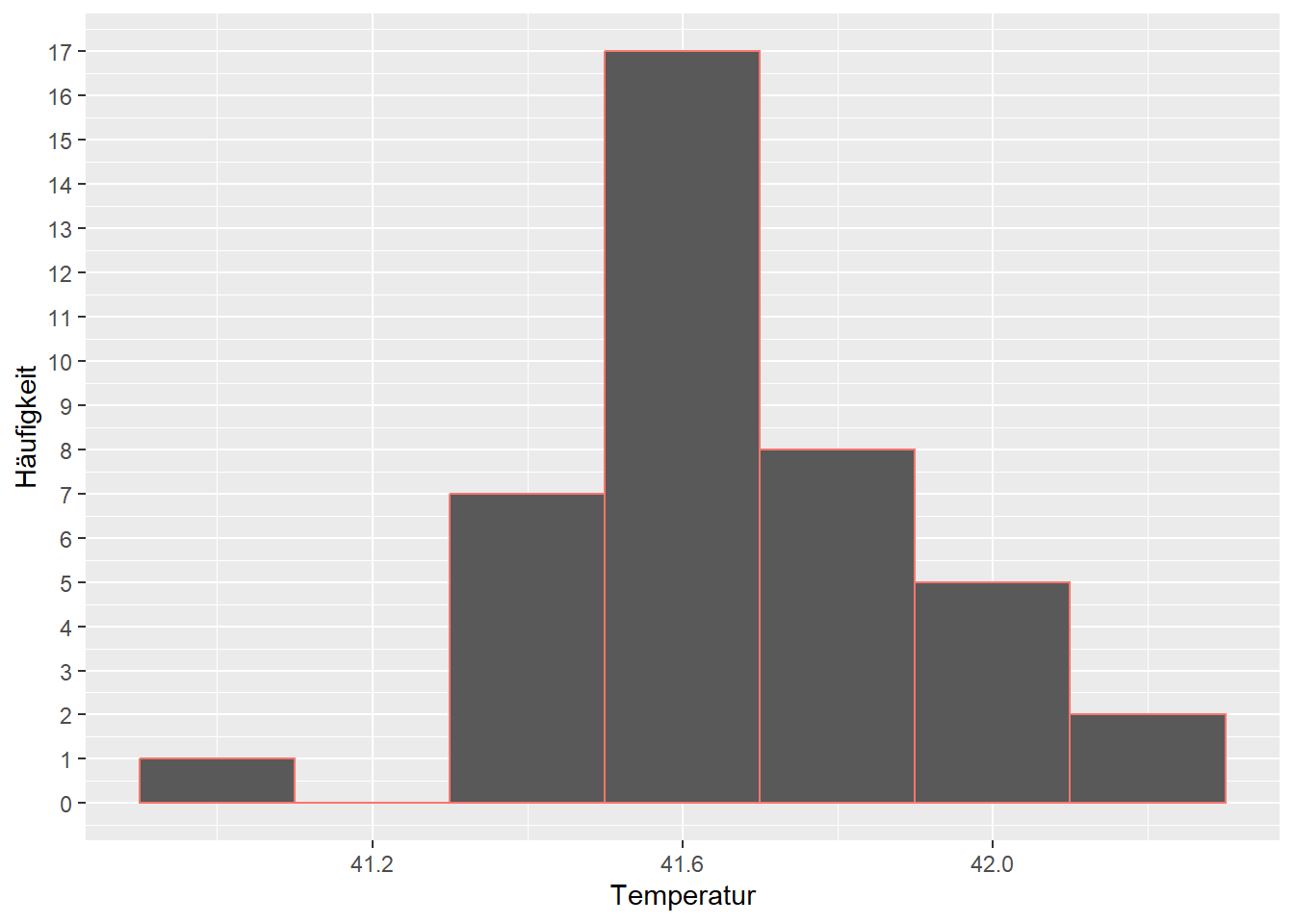
Abbildung 2.1: Histogramm Körpertemperatur Enten.
Aufgrund dieser Darstellung kann die Veterinärin nun sehen, wie häufig welche Körpertemperaturen sind. Dies wird die Verteilung des Merkmals genannt. Sie bemerkt zum Beispiel, dass Beobachtungen der Körpertemperatur rund um 41.6°C am häufigsten sind und tiefere und höhere Temperaturen seltener vorkommen. Auf einen Blick sieht sie auch, dass die Temperatur aller Enten zwischen 41°C und 42.2°C war.
Die Verteilung eines Merkmals zu kennen ist hilfreich, jedoch in vielen Situationen (z. B. in der Kommunikation) noch zu komplex. Einfacher ist es die Komplexität einer Verteilung auf zwei Faktoren herunterzubrechen: Die Zentralität und die Variabilität eines Merkmals.
2.2.2 Zentralität
Mit der Zentralität ist ein Wert gemeint, welcher die zentrale Tendenz des Merkmals abbildet. Um die Zentralität zu messen, gibt es drei Möglichkeiten:
- Der Modus ist der am häufigsten vorkommende Wert. Im Beispiel ist das der Wert 41.52, welcher 3 mal und damit am häufigsten vorkommt. In Jamovi wird der Modus mit
Modalwertbezeichnet. - Wenn die Werte des Merkmals aufsteigend sortiert werden und der Wert betrachtet wird, welcher die Beobachtungen in eine tiefere und eine höhere Hälfte teilt, dann wird dieser Wert als Median (abgekürzt Mdn, Symbol \(\tilde{x}\)) bezeichnet. Bei einer geraden Anzahl Beobachtungen, wird in der Regel der Durchschnittswert der beiden mittigsten Beobachtungen verwendet. Im Beispiel haben wir 40 Beobachtungen. Der Median entspricht also dem Durchschnittswert zwischen dem 20. und dem 21. der aufsteigend sortierten Werte 41.07, 41.32, 41.35, 41.43, 41.46, 41.46, 41.48, 41.5, 41.51, 41.52, 41.52, 41.52, 41.53, 41.53, 41.54, 41.58, 41.58, 41.6, 41.62, 41.65, 41.66, 41.67, 41.67, 41.69, 41.7, 41.72, 41.8, 41.81, 41.81, 41.82, 41.82, 41.88, 41.89, 41.92, 41.92, 41.96, 42.01, 42.06, 42.14 und 42.18, also 41.655. In Jamovi wird der Median mit
Medianbezeichnet. - Das arithmetische Mittel (abgekürzt M, Symbol \(\bar{x}\)) bezeichnet, was gemeinhin mit Durchschnitt gemeint ist. Wenn wir die erste von insgesamt \(n\) Beobachtung mit \(x_1\) und die letzte Beobachtung mit \(x_n\) bezeichnen, so ist das arithmetische Mittel
\[\begin{equation}
\bar{x} = \frac{1}{n}\sum^n_{i=1} x_i
\tag{2.1}
\end{equation}\]
Im Beispiel ist das arithmetische Mittel der Körpertemperaturen 41.6725. In Jamovi wird das arithmetische Mittel als
Mittelwertbezeichnet.
Hinweis. Erklärung der Formel: Hier wird zum ersten Mal eine Formel verwendet. \(\sum\) steht für die Summe von allen Beobachtungen \(x_i\), wenn der Index \(i\) in \(1\)-Schritten von der Zahl unter dem Summenzeichen \(i=1\) bis zu der Zahl oben am Summenzeichen \(i=n\) läuft. In unserem Beispiel ist \(n=40\), also ist \(i = 1, 2, 3, 4, \ldots, 39, 40\). Der Teil \(\sum^n_{i=1} x_i\) bedeutet also nichts anderes als \(x_1 + x_2 + \ldots + x_{39} + x_{40}\), also die Summe aller Beobachtungen. \(\frac{1}{n}\) bedeutet, dass wir diese Summe jetzt noch durch die Anzahl Beobachtungen teilen.
Welchen Einfluss haben die verschiedenen Einflussgrössen: Dies wird in Übung 2.3 erklärt.
Jedes dieser Masse für die Zentralität hat Vor- und Nachteile und sie werden dementsprechend in unterschiedlichen Situationen eingesetzt, siehe Übungen.
2.2.3 Variabilität
- Die Spannweite (abgekürzt \(R\) aus dem englisch range) ist der höchste beobachtete Wert minus der kleinste beobachtete Wert. Im Beispiel ist der höchste beobachtet Wert \(42.18° C\) und der kleinste Beobachtete Wert \(41.07° C\). Also ist die Spannweite \(42.18 - 41.07 = 1.11° C\). Die Spannweite wird in Jamovi mit
Wertebereichbezeichnet. - Wenn die Werte des Merkmals aufsteigend sortiert werden und der Wert betrachtet wird, welcher die Beobachtungen in eine \(P\%\) tiefere und \((100\% - P\%)\) höhere Hälfte teilt, dann wird dieser Wert als Perzentil bezeichnet. Das \(5\%\)-Perzentil zum Beispiel teilt die beobachteten Werte in \(5\%\) kleinere und \(95\%\) grössere Werte. Im Beispiel haben wir 40 Beobachtungen. \(5\%\) davon sind demnach \(2\) Beobachtungen die tiefer sind als das \(5\%\) Perzentil und \(95\%\) also \(38\) Beobachtungen die höher sind als das \(5\%\) Perzentil. Das \(5\%\) Perzentil liegt also zwischen \(41.32° C\) und \(41.35° C\). In diesem Fall wird ein Mittelwert der beiden nächsten Werte verwendet, hier \((41.32 + 41.35)/2=41.34° C\). Das \(P\%\)-Perzentil kann in Jamovi bei
Perzentilgefolgt von der ZahlPermittelt werden. Ein Perzentil alleine gibt jedoch noch keinen Hinweis auf die Streuung der Werte. Werden aber zwei Perzentile zusammen betrachtet, z. B. das \(5\%\) und das \(95\%\) Perzentil, dann geben diese Werte und der Abstand dazwischen einen Hinweis auf die Streuung der Beobachtungen. Im Beispiel ist das \(5\%\) Perzentil bei \(41.34° C\) und das \(95\%\)-Perzentil bei \(42.1° C\). Hier befinden sich also \(90\%\) aller Beobachtungen zwischen diesen Werten. Mehrere Perzentile können in Jamovi gleichzeitig angezeigt werden indem die Perzentil-Werte mit Komma getrennt werden, für die Perzentile hier im Beispiel0.05, 0.95. Weitere beliebte Werte sind das \(25\%\) und das \(75\%\)-Perzentil (auch Quartile genannt, da sie die beobachteten Werte vierteln), im Beispiel bei \(41.52° C\) und \(41.82° C\) respektive. Die Differenz dieser Perzentile wird als Interquartilabstand (abkürzung IQR von interquartile range) bezeichnet und ist im Beispiel \(0.3° C\).. Der Interquartilabstand wird in Jamovi mitIQRbezeichnet. - Die Standardabweichung (abgekürzt SD, Symbol \(s\)) ist die durchschnittliche Abweichung jeder Beobachtung vom arithmetischen Mittel. Wenn wir die erste von insgesamt \(n\) Beobachtung mit \(x_1\) und die letzte Beobachtung mit \(x_n\) bezeichnen, so ist die Standardabweichung
\[\begin{equation}
s = \sqrt{\frac{1}{n-1}\sum^n_{i=1} (x_i-\bar{x})^2}
\tag{2.2}
\end{equation}\]
Im Beispiel ist die Standardabweichung der Körpertemperaturen \(0.233° C\). In Jamovi wird die Standardabweichung mit
Std.-abweichungbezeichnet.
Hinweis. Erklärung der Formel: \((x_i-\bar{x})\) bezeichnet den Abstand von jeder Beobachtung zum arithmetischen Mittel. Dieser Abstand kann positiv (wenn \(x_i\) grösser ist als \(\bar{x}\)) oder negativ (wenn \(x_i\) kleiner ist als \(\bar{x}\)) ausfallen. Damit diese positiven und negativen Abstände sich in der Summe nicht ausgleichen und eine Standardabweichung von 0 entsteht, werden diese Abstände quadriert \((x_i-\bar{x})^2\) bevor sie summiert werden. Anschliessend wird diese Summe durch \(n-1\) geteilt, um den durchschnittlichen Abstand pro Beobachtung zu ermitteln. Intuitiv würde man hier durch \(n\) teilen. Statistiker:innen haben jedoch herausgefunden, dass es einige Vorteile hat, wenn durch \(n-1\) statt \(n\) geteilt wird. Das Quadrat wird nach der Aufsummierung wieder aufgehoben indem die Quadratwurzel gezogen wird.
2.3 Übungen
Übung 2.1
Mit den Daten 02-exm-ducktemp.sav aus Beispiel 2.3:
- Erstellen Sie selbst ein Histogramm mit Jamovi und begründen Sie, weshalb es nicht gleich aussieht wie das Histogramm in Abbildung 2.1.
- Berechnen Sie Modus, Median und arithmetisches Mittel der Körpertemperaturen der Enten mit
Jamoviund berichten Sie diese mit der angemessenen Symbolik. - (\(\star\)) Reproduzieren Sie das Histogramm in Abbildung 2.1 genau mithilfe der Histogramm-Funktion des
Jamovi-ModulsJJStatsPlot(Balci 2025). - Berechnen Sie IQR, \(25\%\)- und \(75\%\)-Perzentil, sowie \(2.5\%\)- und \(97.5\%\)-Perzentil, sowie die Spannweite und die Standardabweichung der Körpertemperaturen der Enten mit
Jamoviund berichten Sie diese mit der angemessenen Symbolik.
Klicke hier, um deine Lösung zu überprüfen.
Lösung.
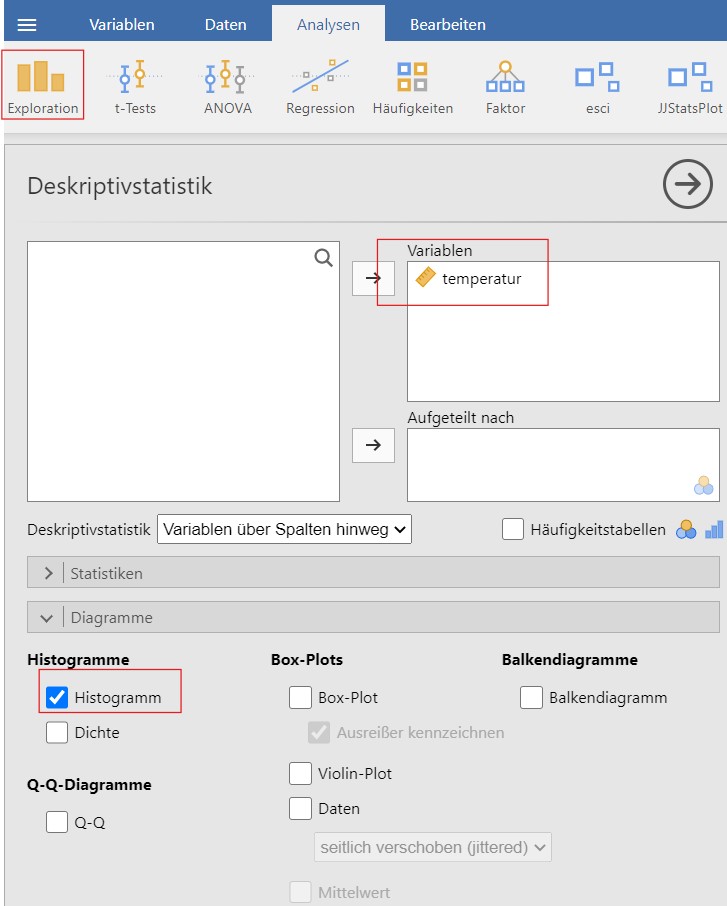
Abbildung 2.2: Links: Jamovi-Anleitung zur Erstellung des Histogramms; rechts: Histogramm der Temperatur.
- Das Histogramm, siehe Abbildung 2.2 sieht nicht gleich aus, da Jamovi die Temperaturabschnitte mit Korbbreite \(0.125\)°C kürzer gewählt hat als die in Abbildung Abbildung 2.1 dargestellte Korbbreite von \(0.2\)°C. Ein Histogramm sieht immer anders aus je nach ausgewählter Abschnittsweite.
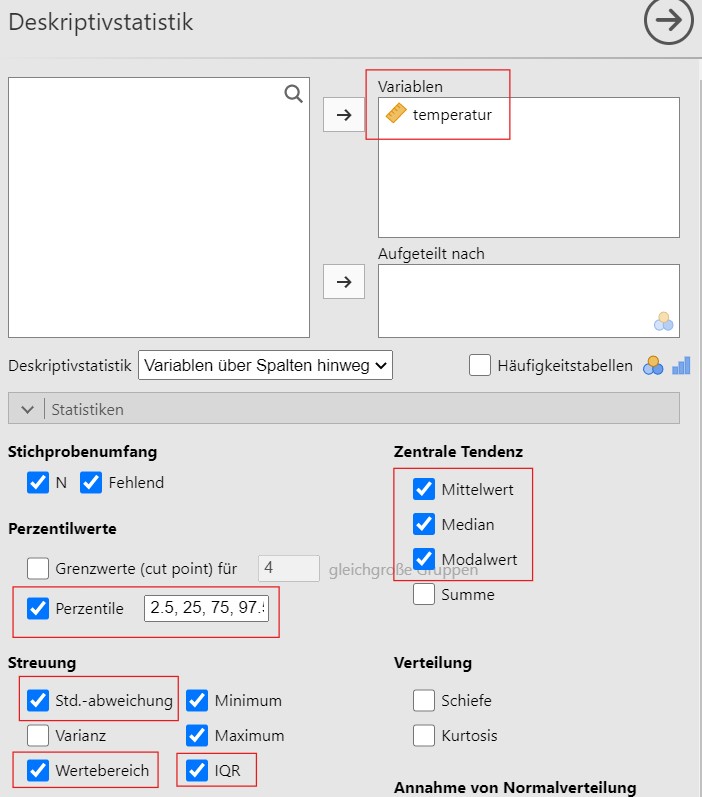
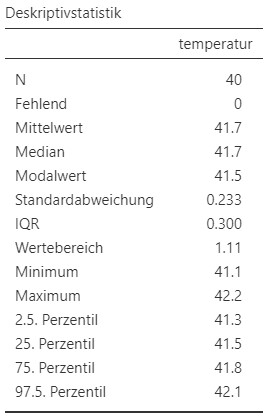
Abbildung 2.3: Links: Jamovi-Anleitung zur Berechnung der gewünschten Parameter; rechts: Parameterwerte.
- Eine Anleitung zur Berechnung in
Jamovisowie die berechneten Werte können in Abbildung 2.3 abgelesen und sind Modus \(= 41.5\)°C, Median \(Mdn = 41.7\) und arithmetisches Mittel \(M=41.7\). - Im Modul
JJStatsPlotkann die Korbgrösse mitChange Bin Widthangepasst werden. In Abbildung Abbildung 2.1 kann beobachtet werden, dass die Balken und also auch die Körbe \(0.2\) Einheiten breit sind. Dies wird so eingestellt, siehe Abbildung 2.4.
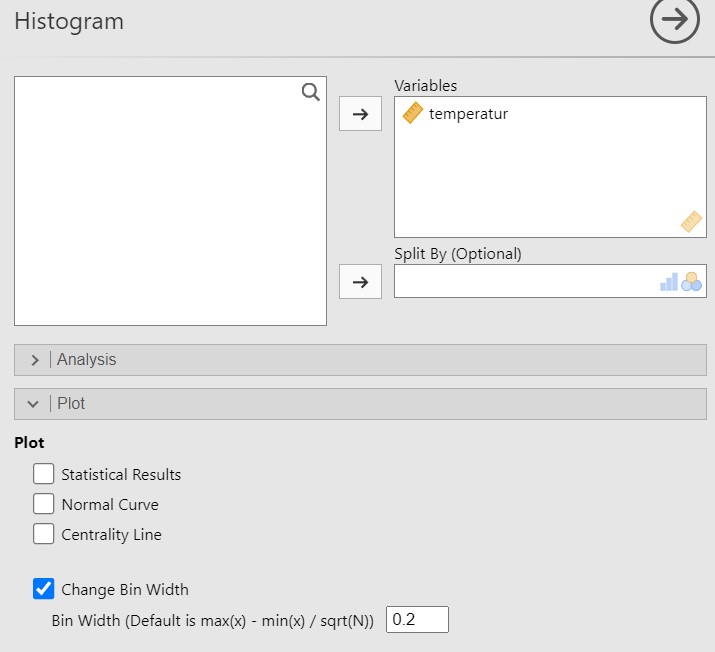
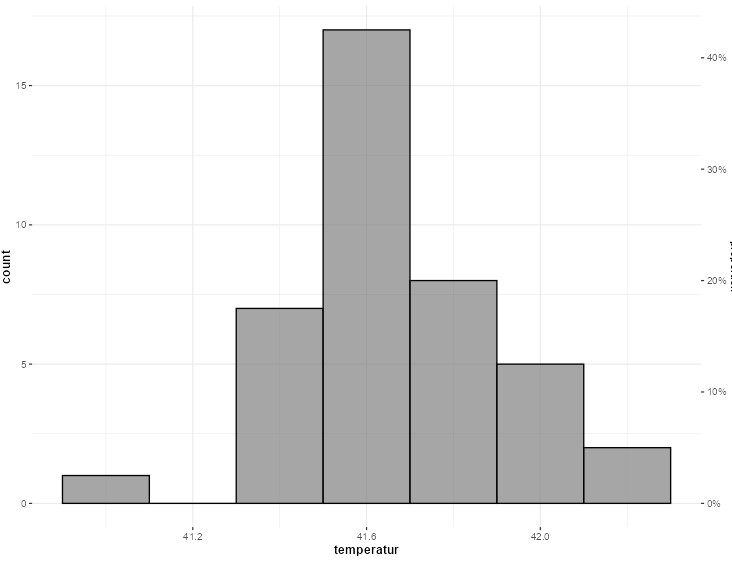
Abbildung 2.4: Links: Jamovi-Anleitung zur Berechnung des gewünschten Histogramms; rechts: Jamovi-Ausgabe.
Es entsteht dabei glücklicherweise genau die gewünschte Darstellung. Es wäre auch möglich gewesen, dass die Körbe auf der \(x\)-Achse verschoben sind, zum Beispiel ein Korb \(41.2\) bis \(41.4\). Diese Verschiebung könnte nicht mit JJStatsPlot behoben werden und müsste mit einer anderen Statistiksoftware bearbeitet werden.
(d) Eine Anleitung zur Berechnung in Jamovi sowie die berechneten Werte können in Abbildung 2.3 abgelesen und sind Interquartilabstand \(IQR= 0.3\)°C, \(25\%\)-Perzentil \(=41.5\), \(75\%\)-Perzentil \(=41.8\), \(2.5\%\)-Perzentil \(=41.3\), \(97.5\%\)-Perzentil \(= 42.1\), Spannweite \(R=1.11\) und die Standardabweichung \(SD = 0.233\).
Übung 2.2
Mit einer Studie soll herausgefunden werden, ob es bei der unabsichtlichen Erinnerung von Informationen einen Altersunterschied (Age) gibt. Dabei werden alte (Old 55-65 Jahre) und junge Menschen (Young 18-30 Jahre) Wörter gezeigt und verglichen, wie viele davon 10 Minuten später noch wiedergegeben werden können Recall. Die Daten sind im Datensatz 02-exr-unintentional-learning.sav festgehalten.
- Stellen Sie die Anzahl erinnerter Wörter in einem Histogramm mit dem
JamoviBasis-Modul dar. - Berechnen Sie alle bekannten Zentralitäts- und Variabilitätsmasse und berichten Sie mit dem korrekten Symbol mit \(2\) Nachkommastellen und mit \(3\) Nachkommastellen.
- Stellen Sie die Anzahl erinnerter Wörter in einem Histogramm mit dem
JJStatsPlot-Modul und einer Korbbreite von \(3\) erinnerten Wörtern dar. Wie viel Prozent der Menschen erinnerten sich an \(8\) bis \(10\) Wörter? Wie viele Menschen erinnerten sich an \(8\) bis \(10\) Wörter? Wieso stimmt hier die relative Häufigkeitproportionmit der absoluten Häufigkeitcountüberein? - Wiederholen Sie Teilaufgabe (b) aber teilen Sie die Daten nach Alter auf. Beschränken Sie sich dabei auf \(2\) Nachkommastellen. Was fällt beim Altersvergleich auf?
Klicke hier, um deine Lösung zu überprüfen.
Lösung. Der Datensatz wird bei Jamovi eingelesen. Für a und b werden die Analyseparameter wie in Abbildung 2.5 gesetzt.
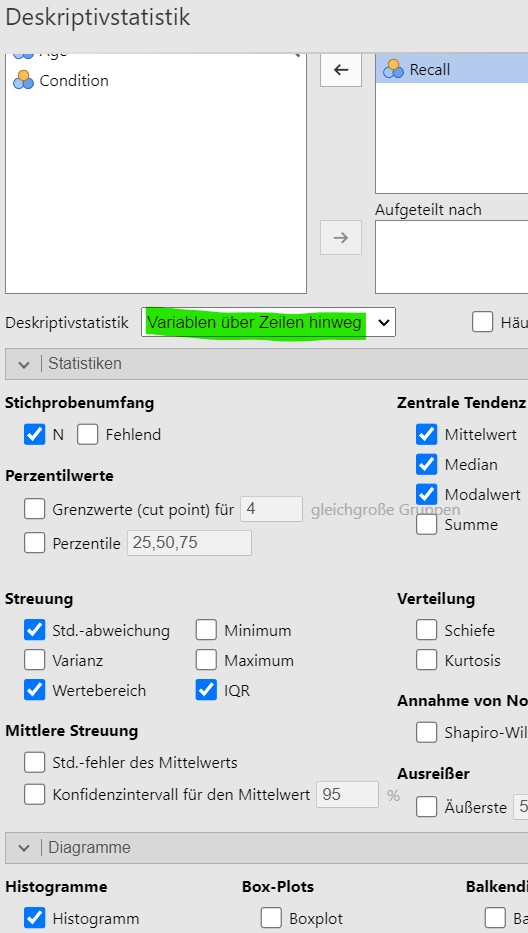
Abbildung 2.5: Jamovi setzen der Analyseparameter.
Dies produziert das Analyseergebnis in Abbildung 2.6, welches zugleich die Lösung für (a) darstellt.
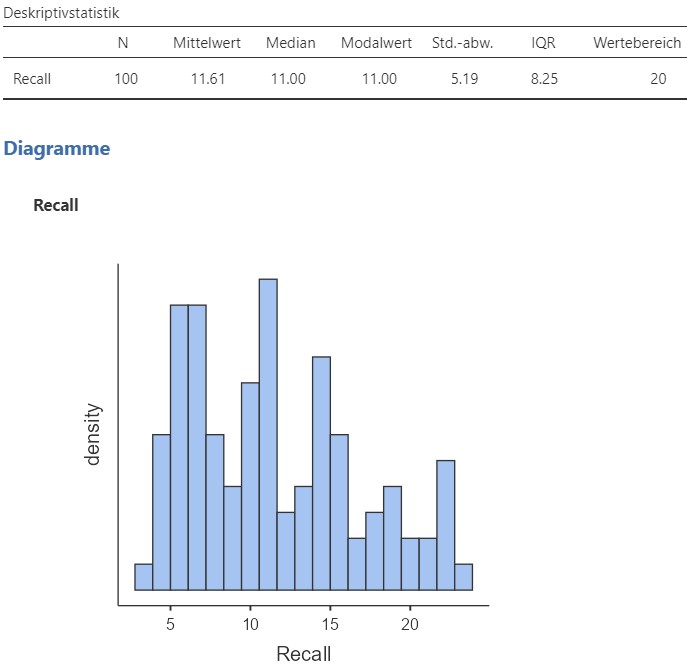
Abbildung 2.6: Jamovi Ausgabe.
- Einmal mit
Jamoviberechnet, können die Parameter in derDeskriptivstatistikabgelesen werden. Die Nachkommastellen werden bei den 3 Punkten in der Ecke oben rechts unterZahlenformateingestellt, siehe Abbildung 2.7.
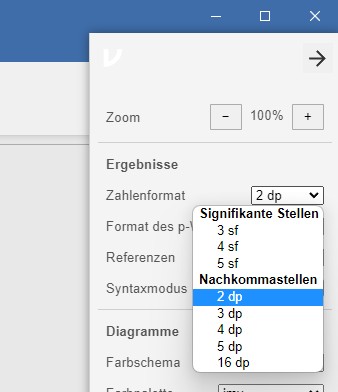
Abbildung 2.7: Jamovi Einstellung Nachkommastellen.
Die durchschnittliche Anzahl erinnerter Wörter liegt bei \(M = 11.61, \text{Mdn} = 11.00, \text{Modus}=11.00\), die Variabilität bei \(\text{SD}=5.19, \text{IQR} = 8.25, R= 20.00\). (\(2\) Nachkommastellen)
Die durchschnittliche Anzahl erinnerter Wörter liegt bei \(M = 11.610, \text{Mdn} = 11.000, \text{Modus}=11.000\), die Variabilität bei \(\text{SD}=5.191, \text{IQR} = 8.250, R= 20.000\). (\(3\) Nachkommastellen)
- Für c werden die Analyseparameter wie in Abbildung 2.8 gesetzt.
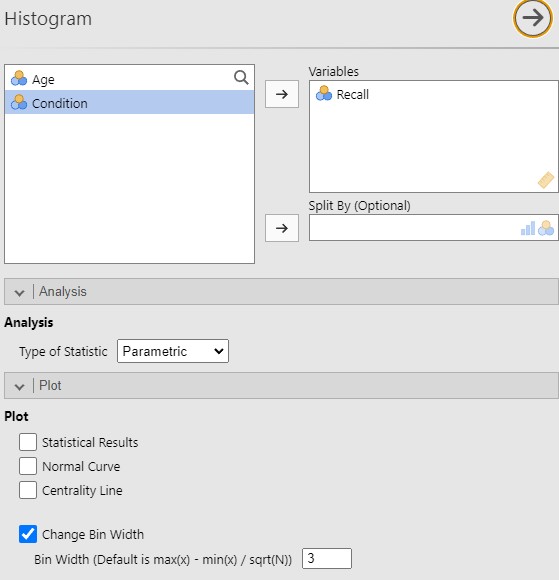
Abbildung 2.8: Jamovi setzen der Analyseparameter.
Dies produziert das Analyseergebnis in Abbildung 2.9.
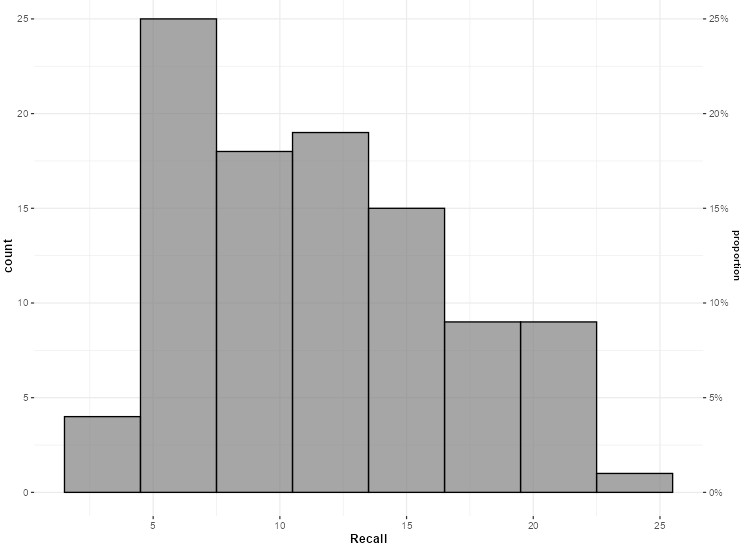
Abbildung 2.9: Jamovi Ausgabe.
Aus dem Histogramm kann am 3. Balken auf der count-Achse (links) respektive der proportion-Achse abgelesen werden, dass sich \(18\) Menschen respektive \(18\%\) der Beobachtungen an zwischen \(8\) bis \(10\) Wörter erinnern. Hier entsprechen die relative und die absolute Häufigkeit einander genau, weil genau \(N=100\) Beobachtungen vorliegen. \(18\) Beobachtungen entsprechen also \(18\%\) der Beobachtungen.
- Für d werden die Analyseparameter wie in Abbildung 2.10 gesetzt.
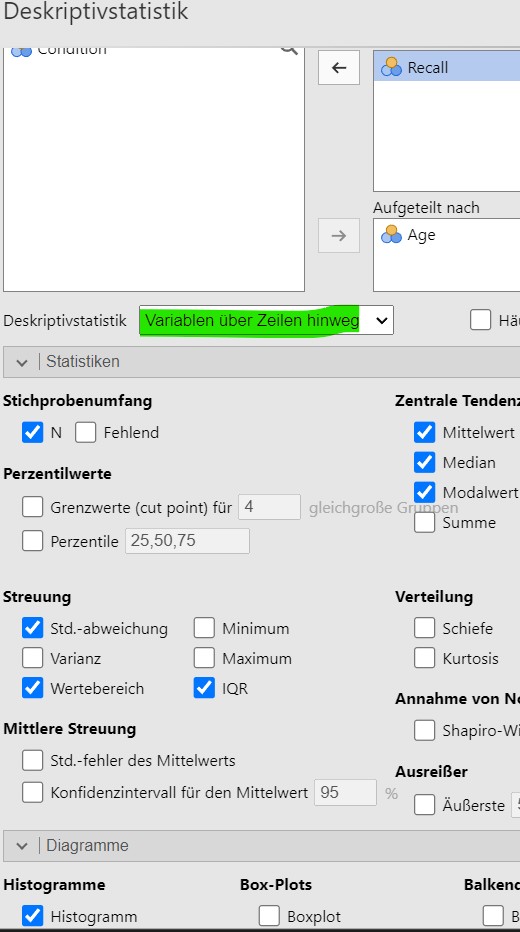
Abbildung 2.10: Jamovi setzen der Analyseparameter.
Dies produziert das Analyseergebnis in Abbildung 2.11.
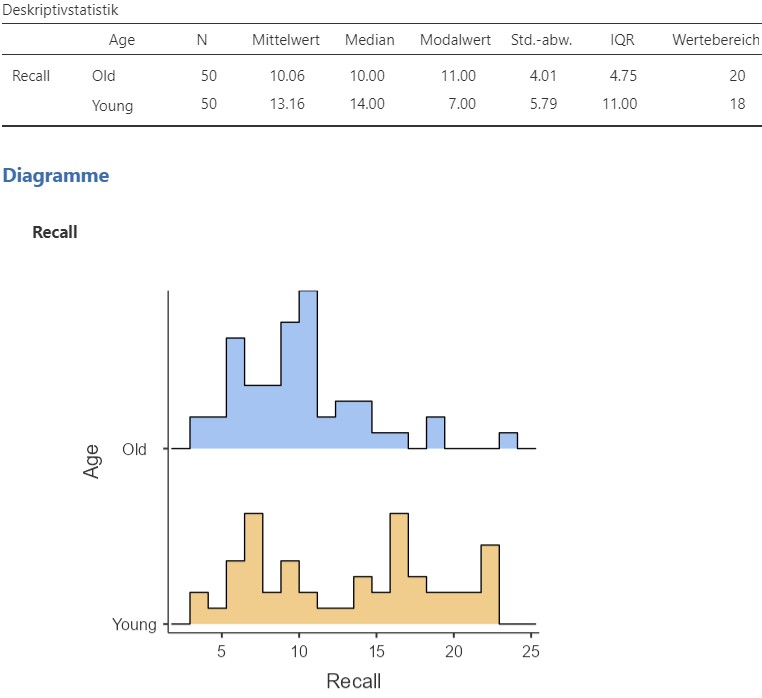
Abbildung 2.11: Jamovi Ausgabe.
Für die ältere Gruppe ist die durchschnittliche Anzahl erinnerter Wörter bei \(M = 10.06, \text{Mdn} = 10.00, \text{Modus}=11.00\), die Variabilität davon liegt bei \(\text{SD}=4.01, \text{IQR} = 4.75, R= 20.00\). Für die jüngere Gruppe ist die durchschnittliche Anzahl erinnerter Wörter bei \(M = 13.16, \text{Mdn} = 14.00, \text{Modus}=7.00\), die Variabilität davon liegt bei \(\text{SD}=5.79, \text{IQR} = 11.00, R= 18.00\).
Es fällt auf, dass sich die jüngere Gruppe durchschnittlich mehr Wörter merken kann (Vergleich arithmetisches Mittel oder Median). Die jüngere Gruppe weist ebenfalls eine grössere Streuung der Anzahl erinnerter Wörter auf als die ältere Gruppe (Vergleich Standardabweichung und IQR). Auf dem Histogramm lässt sich erkennen, dass es insbesondere wenige Leute in der älteren Gruppe gibt mit mehr als \(15\) erinnerten Worten.
Übung 2.3
In einem psychologischen Test machen \(5\) Probandinnen die Werte \(18, 21, 20, 19, 22\). Um mit einer Zahl zu sagen, wo die Testresultate liegen, wird ein zentraler Wert berechnet.
- Wie gross ist das arithmetische Mittel und der Median dieser Werte? Rechnen Sie im Kopf oder mit einem Taschenrechner.
- Nehme an, der Testleiter hat den Wert der ersten Probandin falsch in seine Tabelle übertragen - statt \(18\) hat er \(81\) geschrieben. Wie gross ist das arithmetische Mittel und der Median dieser Werte in diesem Fall?
- Gleich wie (a), aber führen Sie die Berechnungen aus indem die Zahlen manuell bei
Jamovieingegeben. Tipp: Die Messskala muss manuell auf kontinuierlich gestellt werden. - Gleich wie (b), aber führen Sie die Berechnungen aus indem die Zahlen manuell bei
Jamovieingegeben. - Was sagt dies über den Median und das arithmetische Mittel aus?
Klicke hier, um deine Lösung zu überprüfen.
Lösung.
- Wir haben hier \(n=5\) Beobachtungen, nämlich \(x_1 = 18, x_2 = 21, x_3 = 20, x_4 = 19, x_5=22\). Wird dies in die Formel (2.1) eingesetzt, so gibt dies das arithmetische Mittel \[\bar{x} = \frac{1}{n}\sum^n_{i=1} x_i = \frac{1}{n}(x_1 + x_2 + x_3 + x_4 + x_5) = \frac{1}{5}(18+ 21+ 20+ 19+ 22) = 20.\] Um den Median zu berechnen, werden die Werte zuerst aufsteigend sortiert \(18, 19, 20, 21, 22\). Der Wert, welcher die Werte in eine grössere und eine kleinere Hälfte teilt, ist hier \(20\), was dem Median entspricht.
- Die Beobachtungen sind jetzt \(x_1 = 81, x_2 = 21, x_3 = 20, x_4 = 19, x_5=22\). Analog wie in (a) kann demnach das arithmetische Mittel als \(\bar{x} = 32.6\) bestimmt werden. Die aufsteigend sortierten Beobachtungen sind nun \(19, 20, 21, 22, 81\). Der Median ist also \(21\).
Für c und d wird der Datensatz bei Jamovi eingegeben, siehe Abbildung 2.12, und die Analyseparameter werden gesetzt, siehe Abbildung 2.13.
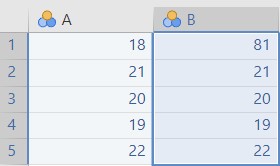
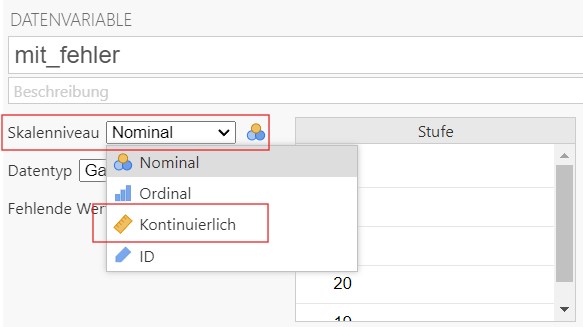

Abbildung 2.12: Jamovi Dateneingabe.
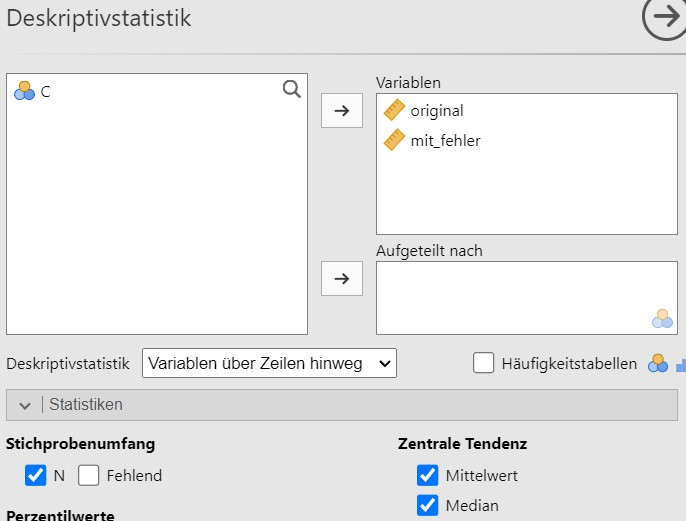
Abbildung 2.13: Jamovi setzen der Analyseparameter.
Dies produziert das Analyseergebnis in Abbildung 2.14.
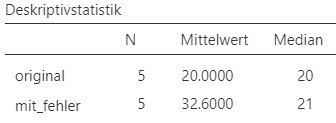
Abbildung 2.14: Jamovi Ausgabe.
Damit können die beiden nächsten Teilfragen beantwortet werden.
- Das Resultat in
Jamoviist genau gleich wie das händisch berechnete. - Das Resultat in
Jamoviist genau gleich wie das händisch berechnete. - Durch die fälschliche Übertragung eines Wertes, ist das arithmetische Mittel sehr stark und der Median fast gar nicht beeinflusst werden. Wenn die Daten wenige fehlerhafte Beobachtungen enthalten, ist der Median das bessere Mass für den zentralen Wert als das arithmetische Mittel. Wenn die Daten keine Fehler enthalten, ist das arithmetische Mittel gleich gut geeignet wie der Median.
Übung 2.4
In einem psychologischen Test machen \(5\) Probandinnen die Werte \(18, 21, 20, 19, 22\). Um mit einer Zahl zu sagen, wie stark die Testresultate streuen, wird die Variabilität berechnet.
- Wie gross ist die Spannweite und die Standardabweichung dieser Werte? Rechnen Sie im Kopf oder mit einem Taschenrechner.
- Nehme an, der Testleiter hat den Wert der ersten Probandin falsch in seine Tabelle übertragen - statt \(18\) hat er \(81\) geschrieben. Wie gross ist die Spannweite und die Standardabweichung dieser Werte jetzt? Rechnen Sie im Kopf oder mit einem Taschenrechner.
- Gleich wie (a), aber führen Sie die Berechnungen aus indem die Zahlen manuell bei
Jamovieingegeben. Tipp: Die Messskala muss manuell auf kontinuierlich gestellt werden. - Gleich wie (b), aber führen Sie die Berechnungen aus indem die Zahlen manuell bei
Jamovieingegeben. - Vergewissern Sie sich, dass der Interquartilabstand in jedem Fall dem Abstand zwischen dem \(25\%\) und dem \(75\%\)-Perzentil entspricht. Vergewissern Sie sich zusätzlich, dass in jedem Fall der Median dem \(50\%\)-Perzentil entspricht.
- Schliessen Sie aus dieser Übung auf das Verhalten der verschiedenen Variabilitätsmasse bei fehlerhaften Daten?
Klicke hier, um deine Lösung zu überprüfen.
Lösung.
- Die Spannweite entspricht dem höchsten minus dem kleinsten beobachteten Wert, also \(R = 22- 18 = 4\). Wir haben hier \(n=5\) Beobachtungen, nämlich \(x_1 = 18, x_2 = 21, x_3 = 20, x_4 = 19, x_5=22\). Wird dies in die Formel (2.2) eingesetzt, so gibt dies die Standardabweichung \[\begin{align} s &= \sqrt{\frac{1}{n-1}\sum^n_{i=1} (x_i-\bar{x})^2} \\ &= \sqrt{\frac{1}{n-1} \left( (x_1-\bar{x})^2+(x_2-\bar{x})^2+(x_3-\bar{x})^2+(x_4-\bar{x})^2+(x_5-\bar{x})^2\right)} \\ &= \sqrt{\frac{1}{5-1} \left( (18-20)^2+(21-20)^2+(20-20)^2+(19-20)^2+(22-20)^2\right)} \\ &= \sqrt{\frac{1}{4} \left( 4+1+0+1+4\right)}\\ &=1.58. \end{align}\]
- Wir haben hier \(n=5\) neue Beobachtungen, nämlich \(x_1 = 81, x_2 = 21, x_3 = 20, x_4 = 19, x_5=22\). Die Spannweite entspricht dem höchsten minus dem kleinsten beobachteten Wert, also \(R = 81 - 19 = 62\). Wird dies in die Formel (2.2) eingesetzt, so gibt dies die Standardabweichung \[\begin{align} s &= \sqrt{\frac{1}{n-1}\sum^n_{i=1} (x_i-\bar{x})^2} \\ &= \sqrt{\frac{1}{n-1} \left( (x_1-\bar{x})^2+(x_2-\bar{x})^2+(x_3-\bar{x})^2+(x_4-\bar{x})^2+(x_5-\bar{x})^2\right)} \\ &= \sqrt{\frac{1}{5-1} \left( (81-32.6)^2+(21-32.6)^2+(20-32.6)^2+(19-32.6)^2+(22-32.6)^2\right)} \\ &= \sqrt{\frac{1}{4} \left( 2342.56+134.56+158.76+184.96+112.36\right)}\\ &=27.08. \end{align}\] Je nach Rundungsverfahren können hier kleinere Werteunterschiede im Nachkommabereich resultieren.
Für c und d wird der Datensatz bei Jamovi eingegeben. Die Variablen werden bearbeitet wie in 2.3 beschrieben. Die Analyseparameter werden gesetzt, siehe Abbildung 2.15.
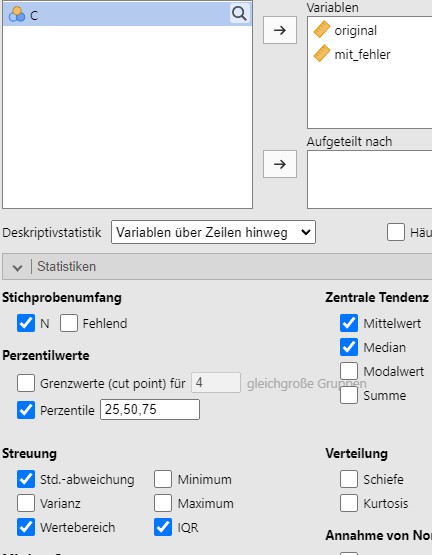
Abbildung 2.15: Jamovi setzen der Analyseparameter.
Dies produziert das Analyseergebnis in Abbildung 2.16.

Abbildung 2.16: Jamovi Ausgabe.
Damit können die beiden nächsten Teilfragen beantwortet werden.
- Tatsächlich ist die Spannweite gemäss Jamovi auch \(R=4\) (siehe
Wertebereich) und die Standardabweichung ist \(SD=1.58\). - Tatsächlich ist die Spannweite gemäss Jamovi auch \(R=62\) (siehe
Wertebereich) und die Standardabweichung ist \(SD=27.08\). - Tatsächlich ist der \(IQR = 2\) in beiden Beispielen. Dies entspricht genau den Perzentildifferenzen \(21-19\) für den original und \(22-20\) für den fehlerhaften Datensatz. Dass zweimal genau derselbe Wert resultiert ist Zufall. In beiden Fällen entspricht der Median dem \(50\%\)-Perzentil. Dies sollte immer der Fall sein, da sowohl der Median, wie auch das \(50\%\)-Perzentil die Beobachtungen in eine höhere und eine tiefere Hälfte teilen.
- Diese Übung zeigt, dass die Standardabweichung und die Spannweite durch fehlerhafte Beobachtungen stark beeinflusst werden. Der Interquartilabstand ist hingegen relativ stabil, solange nicht viele Beobachtungen fehlerhaft sind.
Übung 2.5
Bei einer Befragung wurden die Körpergrösse und das Geschlecht im Datensatz 02-exr-koerpergroesse-sex.sav festgehalten.
- Stellen Sie die Körpergrösse in einem Histogramm dar und berechnen sie alle bekannten Zentralitäts- und Variabilitätsmasse und berichten Sie mit dem korrekten Symbol.
- Wiederholen Sie die Übung aber teilen Sie die Daten nach Geschlecht auf. Was fällt auf?
- Was bedeutet der Kommentar Es gibt mehr als einen Modalwert, nur der erste wird berichtet und welche Bedeutung hat er für die Interpretation des Modus?
Klicke hier, um deine Lösung zu überprüfen.
Lösung.
- Der Datensatz wird bei
Jamovieingelesen und die Analyseparameter wie in Abbildung 2.17 gesetzt.
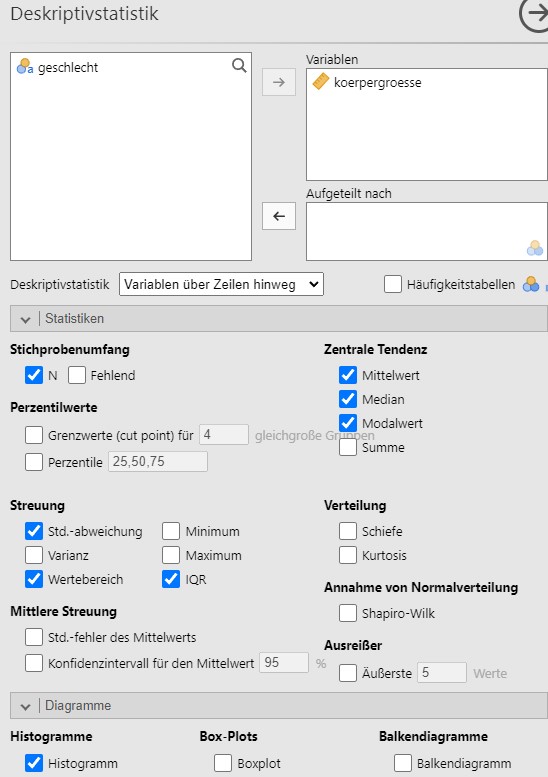
Abbildung 2.17: Jamovi setzen der Analyseparameter.
Dies produziert das Analyseergebnis in Abbildung 2.18.
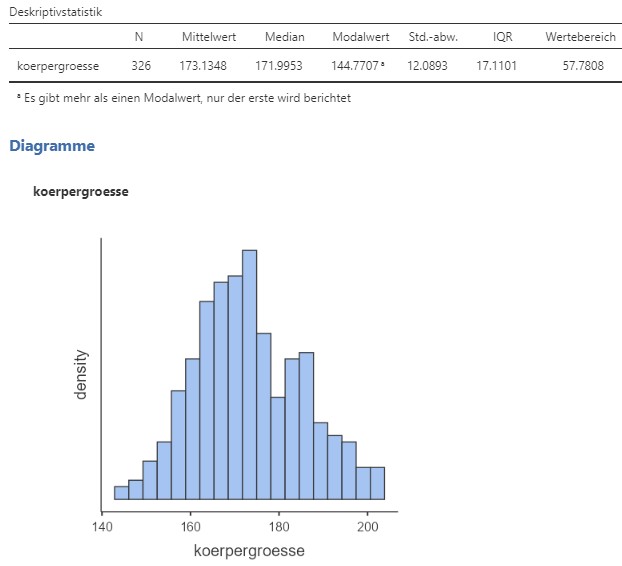
Abbildung 2.18: Jamovi Ausgabe.
Die Körpergrösse ist demnach \(N=326\) mal beobachtet worden. Die Zentralitätmasse sind \(M=173.13\) cm, \(Mdn=172\) (Rundung nach 2 Kommastellen), Modus \(144.77\). Die Variabilitätsmasse sind \(SD=12.09\) cm, \(IQR=17.11\) und \(R=57.78\). Auf dem Histogramm ist ausserdem ersichtlich, dass die meisten Leute zwischen \(160\) und \(180\) cm gross sind und dass nur weniger unter \(155\) oder über \(200\) cm gross sind.
- Die Analyse wird mit Gruppierungsvariable Geschlecht wiederholt wie in Abbildung 2.19
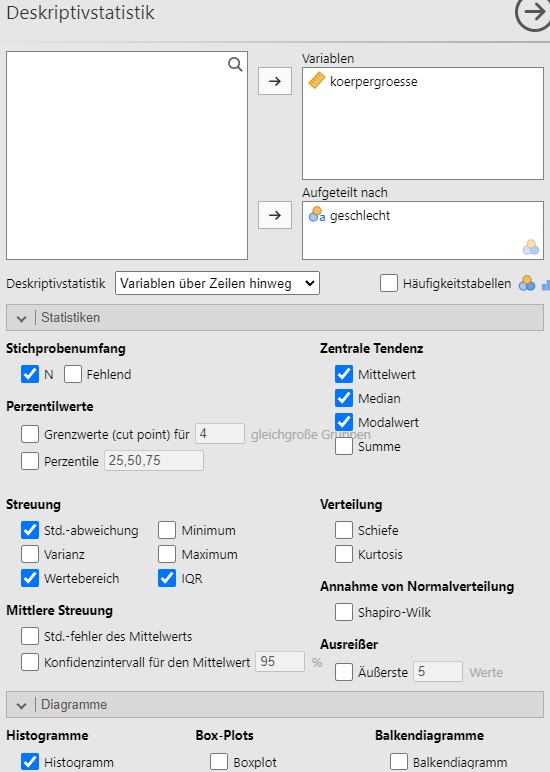
Abbildung 2.19: Jamovi setzen der Analyseparameter.
Dies produziert das Analyseergebnis in Abbildung 2.20.
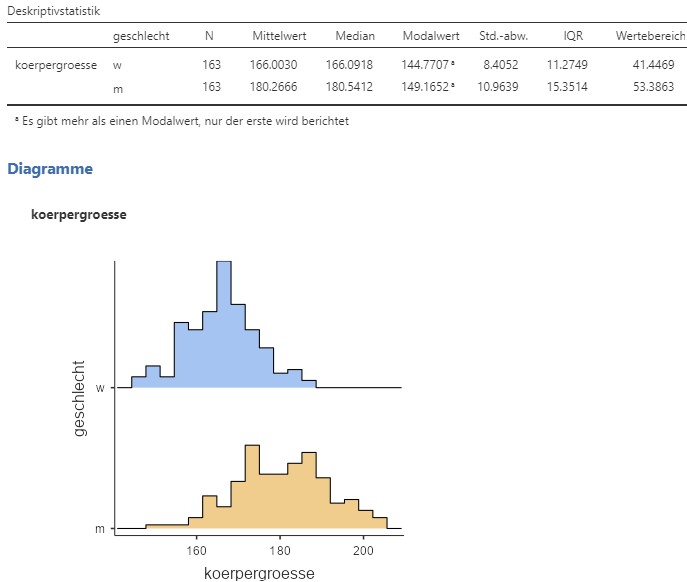
Abbildung 2.20: Jamovi Ausgabe.
Die Körpergrösse ist demnach bei den Frauen \(N=163\) mal beobachtet worden. Die Zentralitätmasse sind \(M=166.00\) cm, \(Mdn=166.09\), Modus \(144.77\). Die Variabilitätsmasse sind \(SD=8.41\) cm, \(IQR=11.27\) und \(R=41.45\). Die Körpergrösse ist bei den Männern auch \(N=163\) mal beobachtet worden. Die Zentralitätmasse sind \(M=180.27\) cm, \(Mdn=180.54\), Modus \(149.17\). Die Variabilitätsmasse sind \(SD=10.96\) cm, \(IQR=15.35\) und \(R=53.39\). Auf dem Histogramm ist ausserdem ersichtlich, dass die beiden Gruppen eine Spitze rund um den Mittelwert bei der Häufigkeit aufweisen. Beobachtungen, welche von der Spitze weiter weg sind werden seltener. Diese zwei Spitzen und somit unterschiedliche Körpergrössenverteilungen nach Geschlecht war aus (a) nicht ersichtlich. Es ist immer möglich, dass bei nicht-Experimenten ein zusätzliches Merkmal (hier das Geschlecht) ganz neue Erkenntnisse bringen kann.
(c) In den Daten der Körpergrösse ist ersichtlich, dass aufgrund der detaillierten Aufzeichnung der Körpergrössen im hundertstel Millimeterbereich keine Beobachtung zweimal vorkommt. Jede Beobachtung ist somit die häufigste Beobachtung. Der Modus ist hier also bedeutungslos. Um einen sinnvolleren Wert für den Modus zu erhalten könnten die Körpergrössen vorab auf Zentimeter gerundet werden. In Jamovi kann dies mit der Funktion ROUND gemacht werden. Der Modus ist dann \(165\) cm für die Frauen und \(172\) für die Männer, was sich mit den Erwartungen aus dem Histogramm deckt.
Übung 2.6
Für eine Studie werden Studierende gebeten eine Aufgabe zu lösen, bei welcher Sie eine gewisse Anzahl Punkte erzielen. Über jede Proband:in sind ausserdem folgende Eigenschaften bekannt:
IQ: IntelligenzquotientAufgeschlossenheit: Likert von 1-7Wartezeit_min: Wartezeit vor beginn des Experiments in MinutenWartezeit_std: Wartezeit vor beginn des Experiments in StundenGeburtzeit_std_ab_mitternacht: Geburtszeit in Stunden ab Mitternacht. Wenn jemand um 13h30 auf die Welt kam, ist dieser Wert 13.5.Geburtzeit_std_ab_mittag: Geburtszeit in Stunden ab Mittag. Wenn jemand um 13h30 auf die Welt kam, ist dieser Wert 1.5.
Die Daten sind in Jamovi unter 02-exr-diverse-distrib.sav verfügbar.
Analysieren Sie alle erhobenen Merkmale indem Sie ein Histogramm erstellen und die zentralen Tendenzen sowie die Variabilität analysieren.
- Wie viele Personen nahmen an der Studie teil?
- Vergleichen Sie Ihre Ergebnisse für die Merkmale IQ und Aufgeschlossenheit. Was für Zusammenhänge fallen auf?
- Vergleichen Sie Ihre Ergebnisse für die Wartezeiten Merkmale. Was für Zusammenhänge fallen auf?
- Vergleichen Sie Ihre Ergebnisse für die Merkmale Punkte und Wartezeiten. Was für Zusammenhänge fallen auf?
- Geburtszeit. TODO.
Klicke hier, um deine Lösung zu überprüfen.
Lösung.
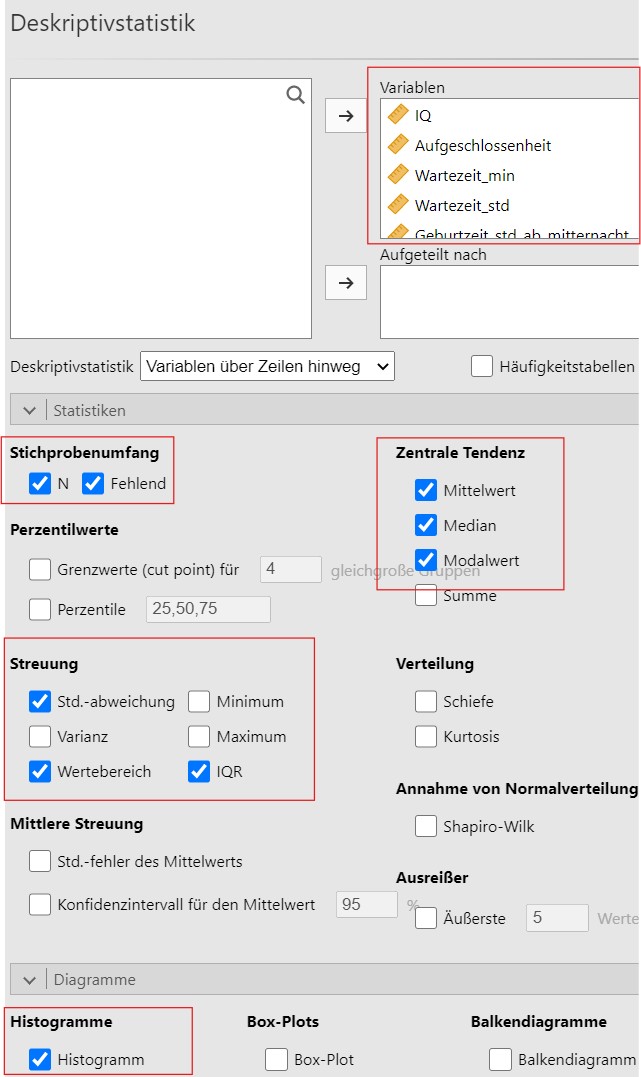
Abbildung 2.21: Jamovi Eingabe.
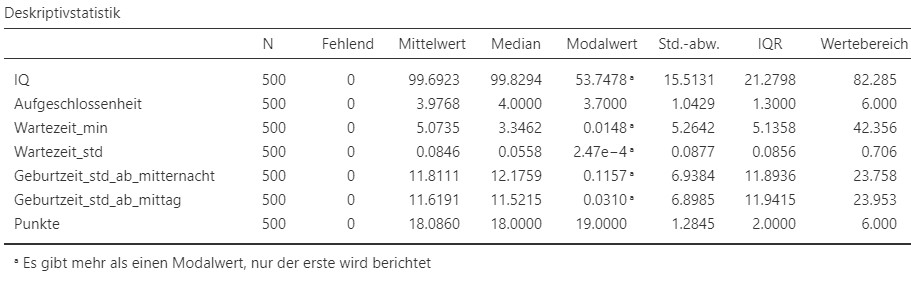
Abbildung 2.22: Deskriptive Statistiken.
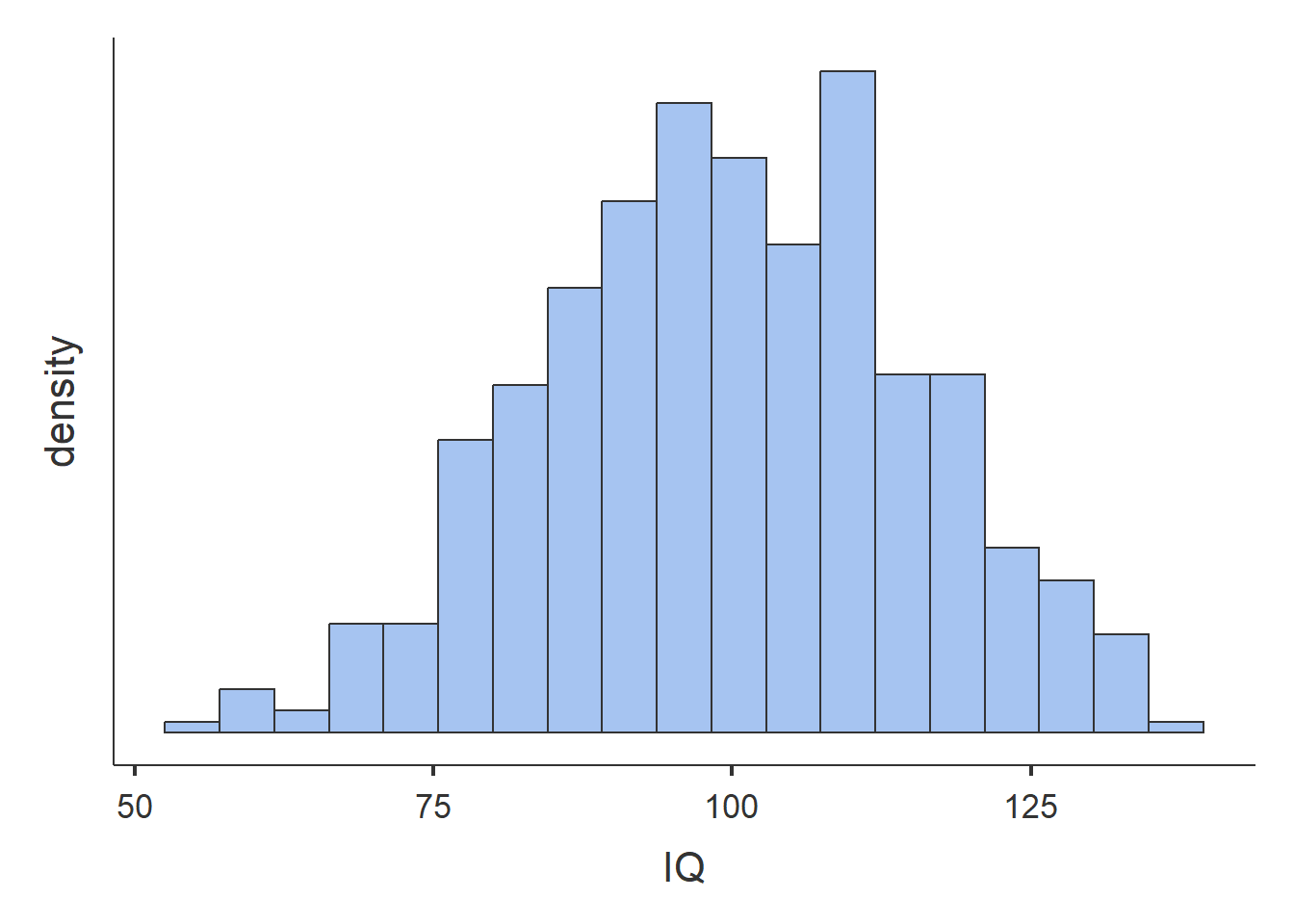
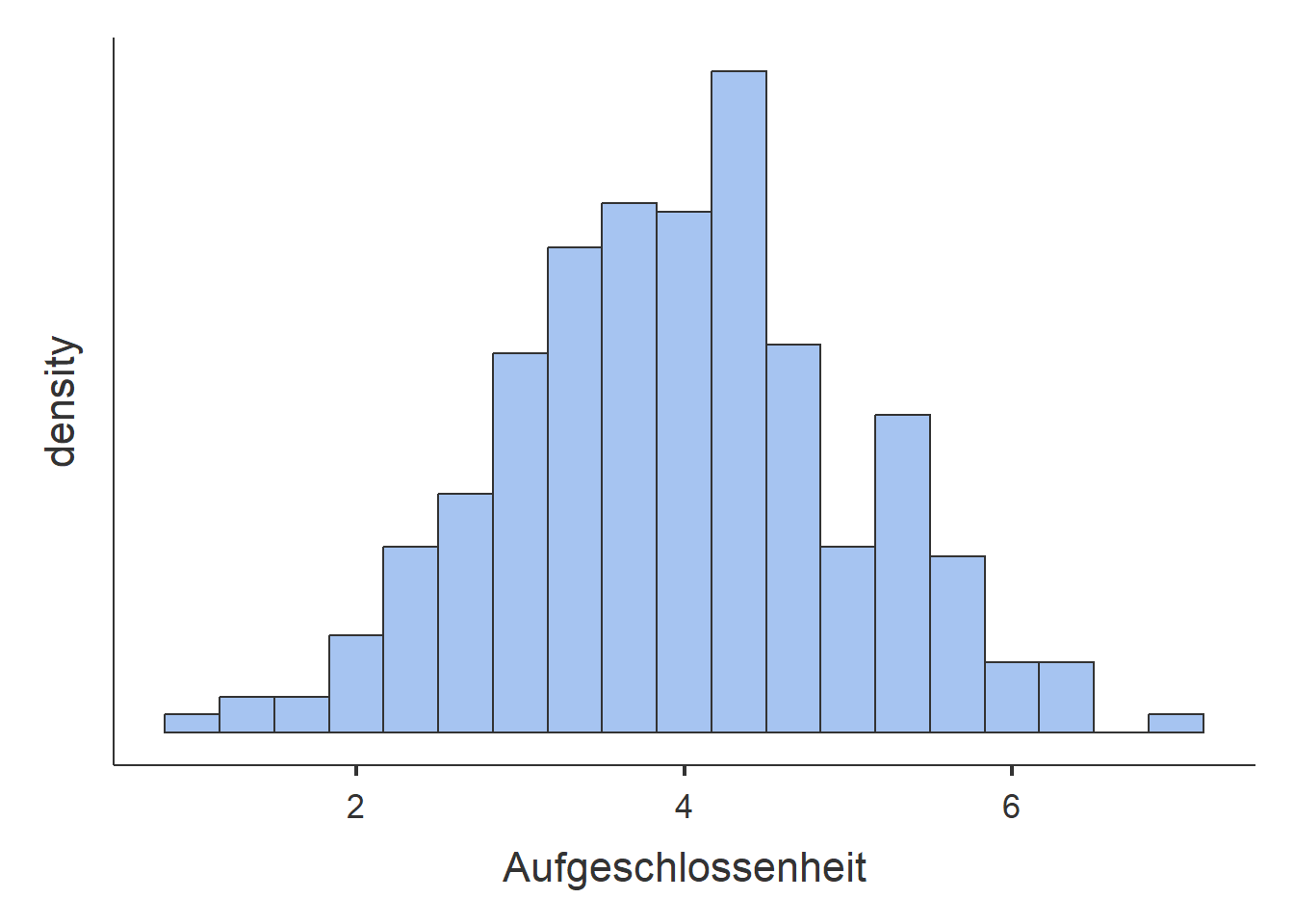
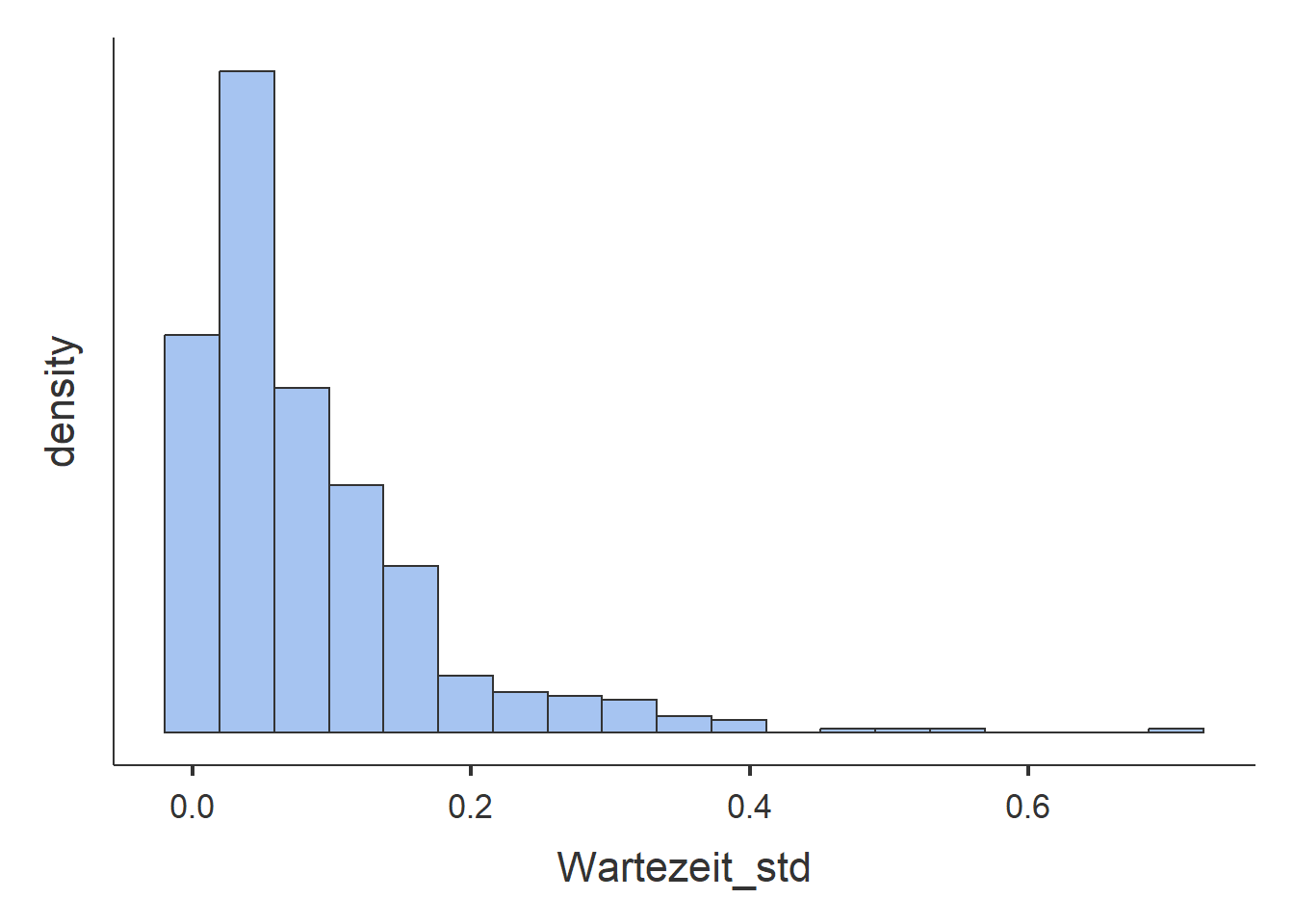
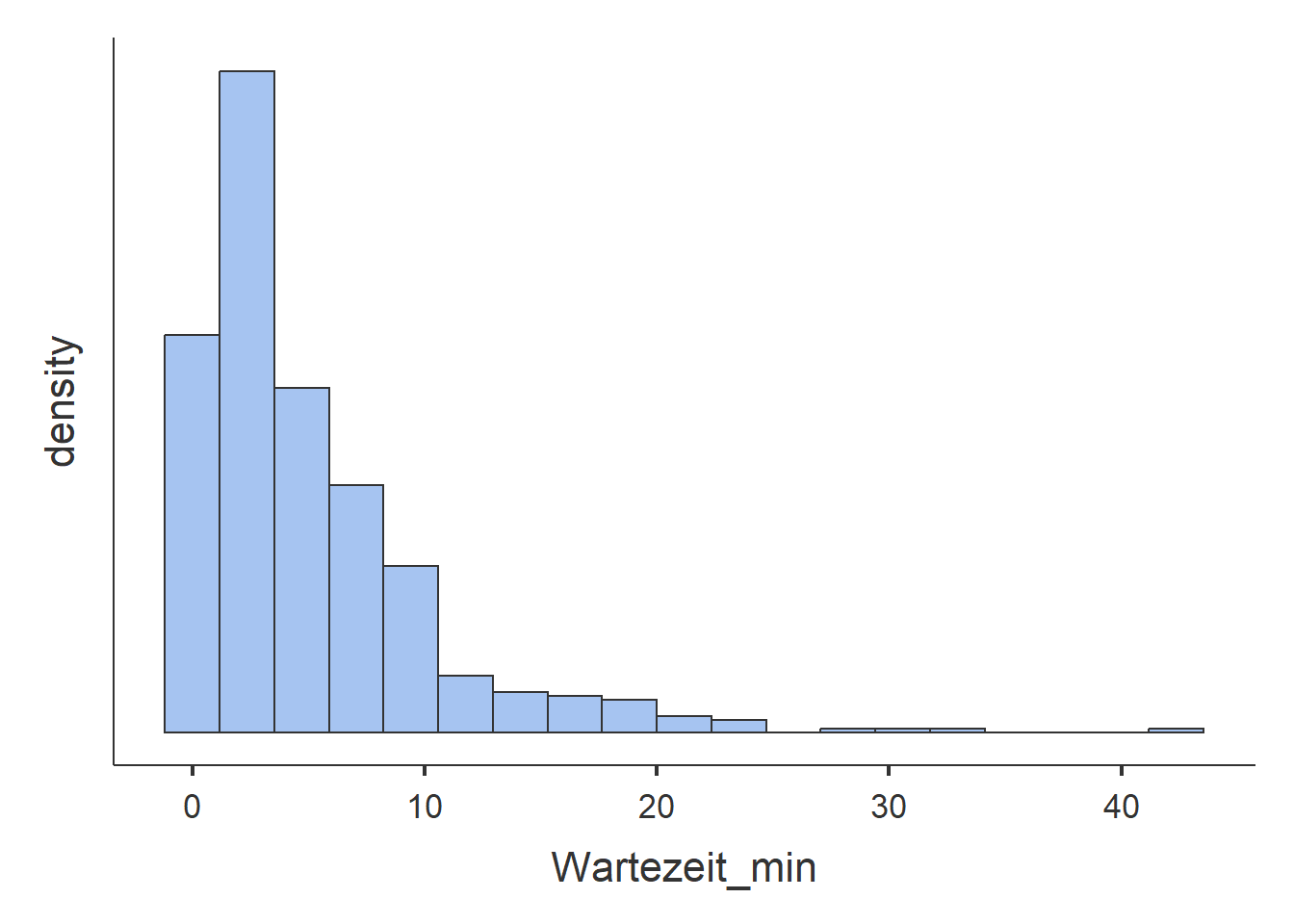
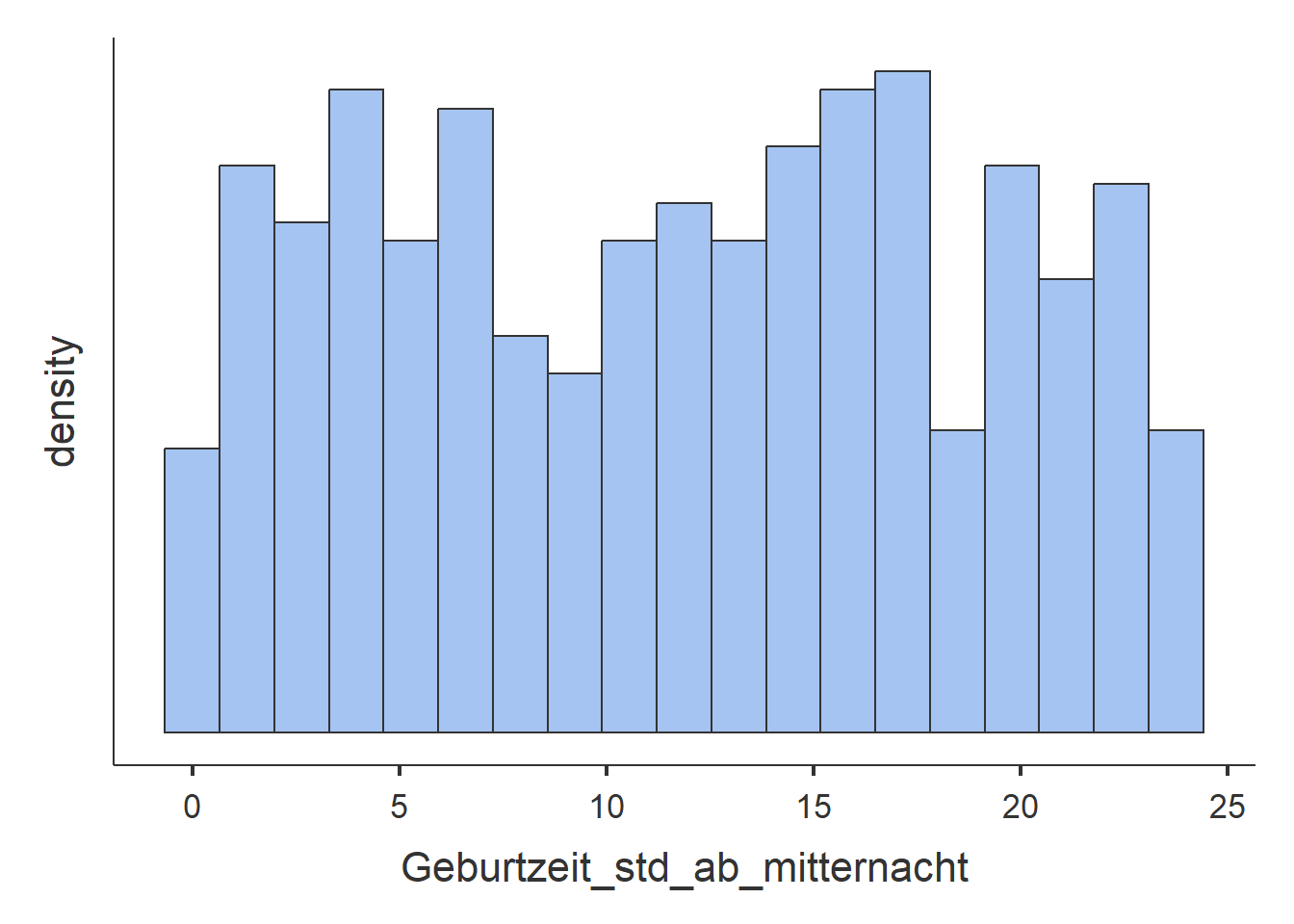
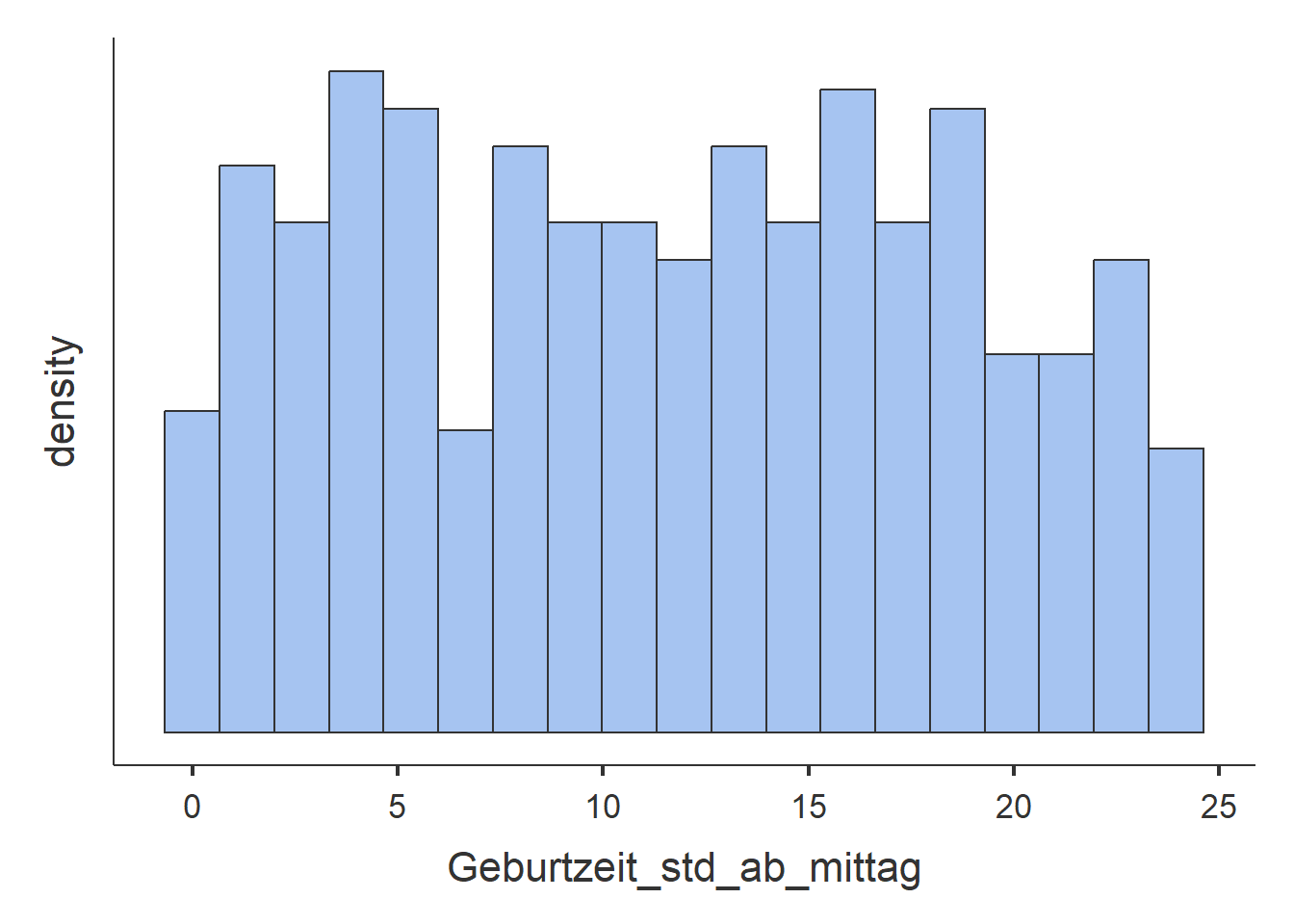
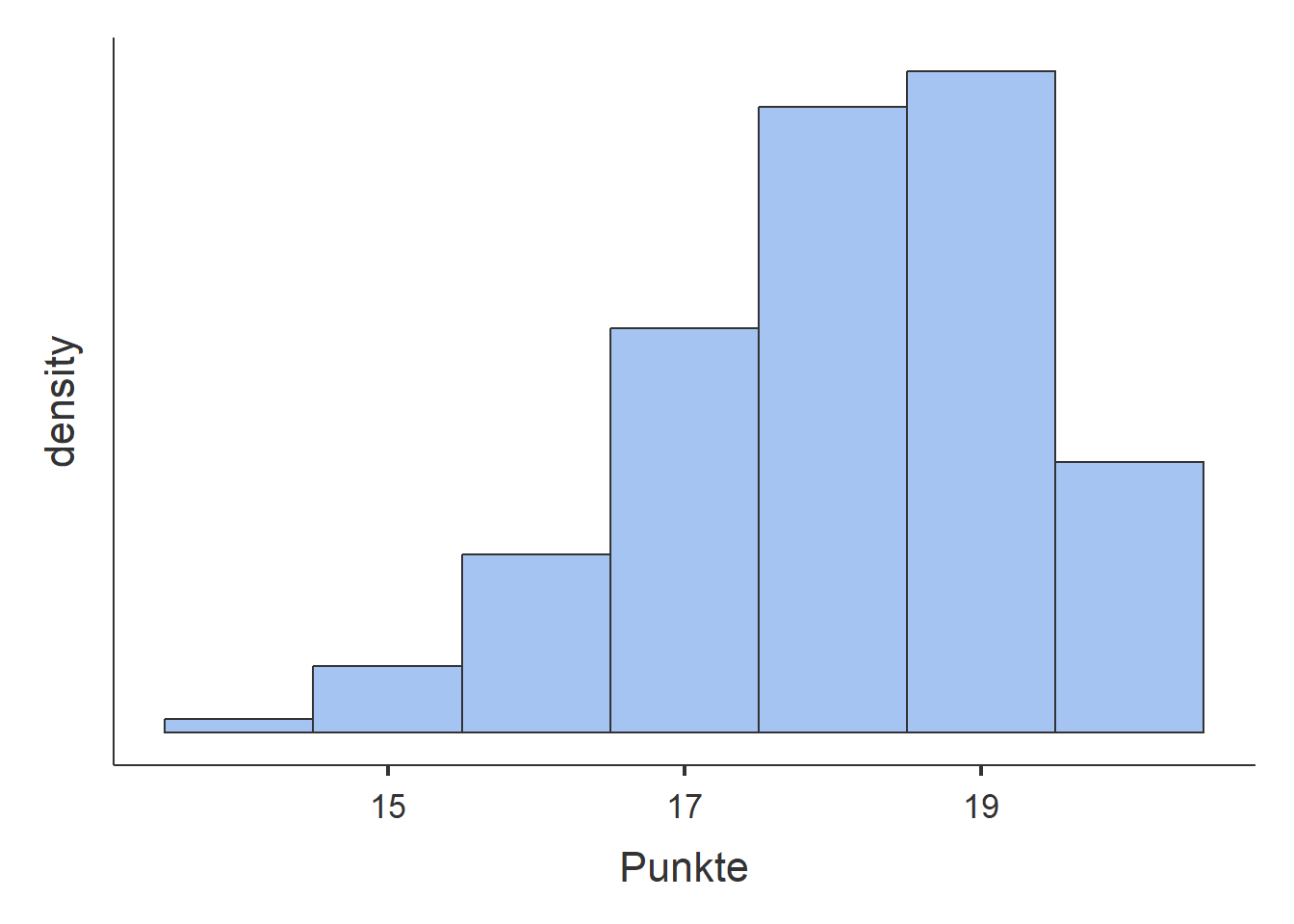
Abbildung 2.23: Histogramme.
Die Merkmale werden mit den Befehlen in Abbildung 2.21 analysiert.
- Es gibt gemäss 2.22 genau \(500\) Studienteilnehmende (siehe \(N\)).
- Die Histogramme für den IQ und die Aufgeschlossenheit weisen eine ähliche Form auf. Viele Beobachtungen sind um eine Mitte zentriert. Je weiter weg von der Mitte, desto seltener sind die Beobachtungen. Das Histogramm des IQ zeigt, dass die Verteilung rund um \(100\) zentriert ist und ca. von \(60\) bis \(140\) reicht. Je weiter entfernt von \(100\), desto weniger Beobachtungen wurden gemacht. Das Histogramm der Aufgeschlossenheit stellt dar, dass diese rund um 4 zentriert ist mit Werten von 1 bis 7. Je weiter die Werte von 4 entfernt sind, desto weniger häufig sind die Beobachtungen. Der vom Histogramm abgeleitete vorher genannte zentrale Wert entspricht ungefähr dem Mittelwert und dem Median für beide Merkmale. Für die Aufgeschlossenheit hat der Modalwert ebenfalls einen ähnlichen Wert. Der Modus für den IQ ist nicht belastbar, da die Fussnote besagt, dass mehrere Werte als Modus in Frage kommen. Eine genauere Durchsicht der IQ-Werte lässt folgern, dass aufgrund der vielen Nachkommastellen jeder IQ-Wert nur genau einmal vorkommt. Der angebene Modalwert des IQs entspricht also einfach einer zufälligen Beobachtung. Die Kennwerte für die Variabilität lassen ebenfalls auf Unterschiede zwischen den beiden Merkmalen schliessen. Die höheren Werte Standardabweichung, IQR und Wertebereich des IQ im Vergleich zur Aufgeschlossenheit legen nahe, dass die Streuung der Werte für den IQ viel grösser ist. Zum Beispiel ist eine durchschnittliche IQ-Beobachtung \(15.5\) IQ-Werte weg vom durchschnittlichen IQ und eine durchschnittliche Aufgeschlossenheits-Beobachtung nur \(1.3\) Aufgeschlossenheits-Werte weg von der duchschnittlichen Aufgeschlossenheit. Dies ist auf dem Histogramm zu erkennen, wenn die Skala der horizontalen Achse betrachtet wird. Für den IQ reicht diese von 50 bis 125 und für die Aufgeschlossenheit von \(2\) bis \(6\).
- Die Wartezeiten wurden einmal in Minuten und einmal in Stunden abgespeichtert. Die resultierenden Histogramme sind deshalb genau identisch bis auf die Werte der horizontalen Achse, welche von \(0\) bis \(0.6\) Stunden und von \(0\) bis \(40\) Minuten reicht. Im Vergleich zu den Histogrammen des IQ und der Aufmerksamkeit kann für die Wartezeit und eine asymetrische Verteilung beobachtet werden. Kurze Wartezeiten werden demnach häufiger beobachtet als längere Wartezeiten. Die meisten Wartezeiten liegen unter \(10\) Minuten, sehr selten kommt es zu Wartezeiten über \(20\) Minuten. Die Kennzahlen für die Wartezeit in Stunden können aus den Kennzahlen der Wartezeit in Stunden hergeleitet werden indem die Werte durch \(60\) geteilt werden. Es reicht deshalb die Kennzahlen für die Wartezeit in Minuten zu betrachten. Die durchschnittliche Wartezeit liegt bei \(M=5.07\) Minuten, \(Mdn = 3.35\). Der Modalwert ist wiederum nicht interpretierbar aus demselben Grund wie oben. Der Median bedeutet, dass \(50\%\) der Wartezeiten kleiner und \(50\%\) der Wartezeiten grösser waren als \(3.35\) Minuten. Das arithmetische Mittel ist höher als der Median. Die einigen wenigen Beobachtungen mit sehr langen Wartezeiten haben also das arithmetische Mittel im Vergleich zum Median stärker beeinflusst.
- TODO.
- TODO: Zentraler Wert hier nicht identifiziertbar, Streuung auch nicht.
2.4 Test
Übung 2.7
Welche der folgenden Merkmalen sind mindestens intervallskaliert?
- Verkaufspreise einer Kunstauktion.
- Eine Person stimmt ja, nein oder enthält sich bei einer Abstimmung.
- Beobachtungen des Intelligenzquotienten.
- Reaktionszeit.
Klicke hier, um deine Lösung zu überprüfen.
Lösung.
- Ja
- Nein
- Ja
- Ja
Übung 2.8
Welche der folgenden Aussagen sind wahr, welche falsch?
- Der Median ist immer kleiner als das arithmetische Mittel.
- Das arithmetische Mittel ist anfälliger für Messfehler als der Median.
- Die Balkenhöhe eines Histogramms steht für die Anzahl Beobachtungen.
- Bei einem Histogramm ist steht das beobachtete Merkmal auf der \(x\)-Achse.
Übung 2.9
Von einem intervallskalierten Merkmal wurden folgende fünf Beobachtungen gemacht: \(12, 23, 15, 12, 7\). Welche der folgenden Aussagen sind wahr, welche falsch?
- Der Median liegt bei \(15\).
- Der Modus ist \(12\).
- Das arithmetische Mittel ist kleiner als der Median.
- \(\sum_{i = 1}^n x_i\) entspricht der Summe der Beobachtungen, also \(69\).
Klicke hier, um deine Lösung zu überprüfen.
Lösung.
- Falsch
- Richtig
- Falsch
- Richtig
Übung 2.10
Es wird beobachtet wie viele Autos ein Haushalt hat. Die Daten sind in 02-exr-autos-haushalt.sav abgelegt. Welche der folgenden Aussagen sind wahr, welche falsch?
- Die durchschnittliche Anzahl Autos pro Haushalt liegt bei \(M=0.87\).
- Der Modus liegt bei \(1\).
- Der Median liegt bei \(M=1\).
- Es wurden \(N=92\) Personen beobachtet.
Klicke hier, um deine Lösung zu überprüfen.
Lösung.
- Richtig
- Falsch, siehe
Modalwert. - Falsch, richtig wäre \(Mdn=1\).
- Falsch, es wurden Haushalte beobachtet nicht Personen.
Übung 2.11
Von einem intervallskalierten Merkmal wurden folgende fünf Beobachtungen gemacht: \(12, 23, 15, 12, 7\). Welche der folgenden Aussagen sind wahr, welche falsch?
- \(SD = 5.89\).
- \(R = 5\).
- \(IQR = 3\).
- \(s = 5.89\).
Klicke hier, um deine Lösung zu überprüfen.
Lösung.
- Richtig
- Falsch
- Richtig
- Richtig
Übung 2.12
Welche der folgenden Aussagen sind wahr, welche falsch?
- Die Spannweite ist immer grösser als der Interquartilabstand.
- \(50\%\) der Beobachtungen sind auf einer Distanz ausgebreitet, welche dem Interquartilabstand entspricht.
- Der Interquartilabstand entspricht der Datenstreuung von der kleinsten Beobachtung bis zum Median.
- Die Standardabweichung wird durch Messfehler weniger beeinflusst als der Interquartilabstand.
Klicke hier, um deine Lösung zu überprüfen.
Lösung.
- Richtig
- Richtig
- Falsch
- Falsch