Kapitel 7 Gruppenmittelwertunterschied bei einem mindestens ordinalskalierten Merkmal
Um einen Gruppenmittelwertunterschied mit dem Zweistichproben-\(t\)-Test oder dem Welch Test testen zu können muss das betrachtete Merkmal intervallskaliert und (a) die Beobachtungen beider Gruppen einer Normalverteilung entstammen oder (b) genügend Beobachtungen, normalerweise mehr als \(30\) pro Gruppe, vorhanden sein. Dies ist in der Realität nicht immer gegeben. Eine Alternative zu den oben genannten Tests, welche ohne diese Voraussetzungen auskommt, ist der \(U\)-Test nach Mann und Whitney. Dieser kann bei mindestens ordinalskalierten Variablen eingesetzt werden und es wird keine Verteilung der Daten vorausgesetzt.
Da der \(U\)-Test keine Verteilung voraussetzt und auch bei nicht intervallskalierten Merkmalen eingesetzt werden kann sind jedoch auch die Hypothesen leicht anders als beim Welch Test. Der \(U\)-Test testet in jedem Fall, ob die Verteilungen in den beiden Gruppen gleich sind. Unter ein paar Zusatzannahmen ist dies Äquivalent zur Hypothese, dass die beiden Populationsmediane sich entsprechen. Auf diese letzte Subtilität wird hier nicht eingegangen.
7.1 Wie stark unterscheiden sich die Mediane?
Beispiel 7.1 (Schmerzen bei Rothaarigen.) Beispiel frei nach Robinson et al. (2021). Viele rothaarige Menschen haben eine
höhere Schmerztoleranz. Der Mechanismus dazu ist auf das MC4R-Gen
zurückzuführen, welches vor allem bei Rothaarigen vorkommt. Um dies zu
testen haben Forschende die Schmerztoleranz von Mäusen mit und ohne
MC4R-Gen-Variante untersucht, indem sie den sogenannten Hot Plate Test
durchgeführt haben. Dabei werden die Mäuse auf eine erhitzte Platte
gestellt und die Zeit in Sekunden gemessen, bis die Maus anfängt zu
hüpfen oder sich die Pfoten zu lecken, um den Schmerz zu reduzieren.
Dies bei einer maximalen Versuchszeit von \(20\) Sekunden. Die Daten sind
unter 07-exm-red-hair-pain.sav verfügbar. Die
Beobachtete Stichprobe ergibt, dass es die \(N = 13\) MC4R-Mäuse
\(M = 12s, SD = 1.93\) und die \(15\) Non-MC4R-Mäuse \(M = 7.8s, SD = 2.16\)
auf der heissen Platte ausgehalten haben. Werden die Daten auf die
Normalverteilung getestet ergibt sich kein klares Bild. Es könnte sein,
dass die Daten nicht normalverteilt sind. Ein Welch Test wäre in diesem
Fall nicht angebracht. Da der \(U\)-Test keine Normalverteilung
voraussetzt, kann dieser hier verwendet werden.
Beim \(U\)-Test nach Mann und Whitney, werden zunächst die Beobachtungen ungeachtet der Gruppenzugehörigkeit in eine aufsteigende Reihenfolge gebracht, siehe mittige Punkte in Abbildung 7.1. Die so sortierten Beobachtungen werden nummeriert, was den sogenannten Rangnummern entspricht. Für gleiche Ränge wird den betreffenden Rängen ein mittlerer Rang zugewiesen.
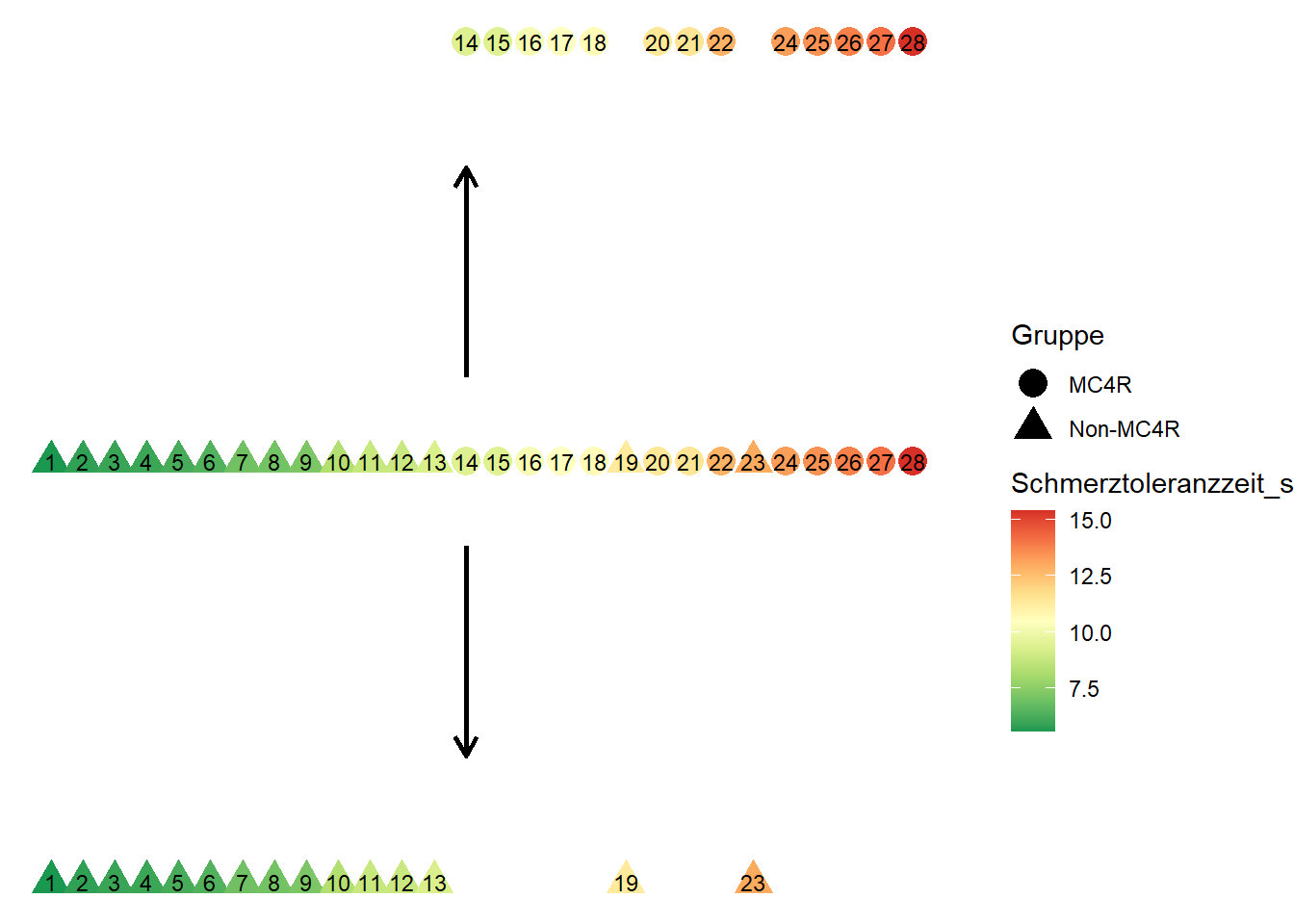
Abbildung 7.1: Mitte: Aufsteigend sortierte Beobachtungen des Merkmals Schmerztoleranz für MC4R und Non-MC4R Mäuse. Die Zahlen stehen für die Rangnummern. Oben (MC4R) und unten (Non-MC4R) stellt die Gruppenaufteilung der Rangnummern dar.
In einem zweiten Schritt werden die Beobachtungen wieder in die Gruppen aufgeteilt (siehe obere und untere Reihe in der Abbildung) und die jeweiligen Rangnummern innerhalb einer Gruppe addiert. Diese Gruppensummen werden Rangsummen genannt und sind hier \[R_\text{MC4R} = 273 \quad R_\text{Non-MC4R} = 133.\]
Die Idee dabei ist, dass wenn sich die Messungen in den beiden Gruppen
nicht oder kaum unterscheiden, dann müssten auch die Rangnummern mehr
oder weniger zufällig auf die beiden Gruppen verteilt sein. Gegeben,
dass die beiden Gruppen gleich gross sind, müssten in diesem Fall auch
die Rangsummen ungefähr gleich gross sein. Um in einem dritten Schritt
für unterschiedliche Gruppengrössen zu korrigieren, wird nun noch die
kleinste Rangsumme abgezogen, welche mit den Beobachtungen erreicht
werden könnte. Für die \(15\) Non-MC4R Beobachtungen wäre dies also
\(1+2+\ldots+ 15 = 120\) oder kurz \(n\cdot (n+1)/2 = 120\). Der so
korrigierte Wert wird \(U\)-Wert genannt und ist im Beispiel
\[U_\text{MC4R} = 273 - 91 = 182 \quad U_\text{Non-MC4R} = 133-120 = 13.\]
Wenn es keinen Gruppenunterschied gibt, dann wären diese \(U\)-Werte nahe
beieinander und beide Werte wären nicht nahe bei \(0\). Wenn es einen
Gruppenunterschied gibt, dann sind die \(U\)-Werte weit auseinander und
der kleinere der beiden Werte läge nahe bei \(0\). Dies macht sich der
\(U\)-Test zu Nutze, indem er nun den kleineren der beiden \(U\)-Werte, hier
\(13\) - die sogenannte Teststatistik - mit einer Referenztabelle
vergleicht, wo die Wahrscheinlichkeiten für einen solchen \(U\)-Wert,
gegeben dass die Nullhypothese wahr ist, hinterlegt sind. Dieser Prozess
ist in Jamovi automatisiert und es kann direkt der \(p\)-Wert in der
Ausgabe abgelesen werden, hier \(p < 0.001\).
Beispiel 7.2 (Aufgeschlossenheit bei Jung und Alt.) Eine Studentin will herausfinden, ob sich die durchschnittliche
Aufgeschlossenheit von jüngere Menschen unter \(30\) Jahren und älteren
Menschen mit über \(30\) oder genau \(30\) Jahren unterscheidet. Dazu
befragt sie zufällig Leute der beiden Gruppen mit dem TIPI, welcher die
Aufgeschlossenheit auf einer Skala von \(1\) bis \(7\) misst, wobei das
kleinste Messintervall \(0.5\) Punkte beträgt. Die Daten sind also eher
ordinal als intervallskaliert. In der Stichprobe waren
\(N = 13\) junge mit einer Aufgeschlossenheit von \(M = 5.38, SD = 0.92\) und \(N =7\) alte mit einer Aufgeschlossenheit von \(M = 5, SD = 0.87\). Die Daten sind unter 07-exm-aufgeschlossenheit-jung-alt.sav verfügbar. (Beispiel frei erfunden.)
Auch in diesem Fall werden für den \(U\)-Test zunächst die Beobachtungen gruppenunabhängig aufsteigend sortiert wie in der Mitte der Abbildung 7.2 dargestellt. Danach werden Rangnummern vergeben und die Beobachtungen wieder in ihre Gruppen geteilt, siehe die Reihen oben und unten der Abbildung. Die Ränge scheinen zufällig in die beiden Gruppen zu fallen.

Abbildung 7.2: Mitte: Aufsteigend sortierte Beobachtungen des Merkmals Schmerztoleranz für Junge und Alte. Die Zahlen stehen für die Rangnummern. Oben (Jung) und unten (Alt) stellt die Gruppenaufteilung der Rangnummern dar.
Nun werden die Ränge innerhalb einer Gruppe addiert \[R_\text{Jung} = 143 \quad R_\text{Alt} = 67.\] Die Rangsummen unterschieden sich hier nicht, weil eine Gruppe systematisch höhere Ränge erreicht, sondern, weil die Gruppe der Jungen mehr Beobachtungen enthält und damit in dieser Gruppe auch mehr Rangnummern addiert werden.
Wird dies nun korrigiert, ergeben sich die \(U\)-Werte \[U_\text{Jung} = 143 - \frac{13\cdot(13+1)}{2} = 52 \quad U_\text{Alt} = 67-\frac{7\cdot(7+1)}{2} = 39.\] Es kann festgestellt werden, dass die \(U\)-Werte nicht weit auseinander und damit weit entfernt von \(0\)-liegen. Dies deutet darauf hin, dass es keinen signifikanten Gruppenunterschied in der Aufgeschlossenheit gibt.
Tatsächlich gibt Jamovi für dieses Beispiel \(p = 0.35\) zurück.
Letzteres kann unter
Analysen > t-Tests > t-Test für unabhängige Stichproben herausgefunden
werden, wenn unter Tests der Test Mann-Whitney U ausgewählt wird.
7.2 Effektstärke
Als Effektstärke können die bisher gesehene Masse wie Cohens \(d\) nicht mehr dienen, da diese auf Parametern basieren, welche auf intervallskalierten Merkmalen beruhen. Stattdessen wird als Effektstärke die biserielle Rangkorrelation verwendet (mehr zum Thema Korrelation folgt in den nächsten Kapiteln).
Zur Illustration der Berechnung der biseriellen Rangkorrelation wird folgendes Beispiel verwendet. Es soll getestet werden, ob Hasen oder Schildkröten schneller laufen können. Dazu wird auf einer Rennstrecke die Zeit von \(10\) Hasen und \(10\) Schildkröten gestoppt. Um die biserielle Rangkorrelation zu berechnen, werden zwischen den Beobachtungsgruppen alle möglichen Paare aufgelistet - also Hase \(1\) mit Schildkröte \(1\), Hase \(1\) mit Schildkröte \(2\), usw., Hase \(2\) mit Schildkröte \(1\), Hase \(2\) mit Schildkröte \(2\), usw., bis Hase \(10\) mit Schildkröte \(10\). Dabei ergeben sich in diesem Beispiel genau \(100\) Paarungen. Nehmen wir nun an, dass für \(90\) dieser Paare, der Hase schneller lief als die Schildkröte und für \(10\) Paare die Schildkröte schneller als der Hase. Die biserielle Rangkorrelation entspricht nun der Anzahl Paare \(f\) für welche Gruppe 1 höhere Werte hatte minus der Anzahl Paare \(u\) für welche Gruppe 2 höhere Werte hatte und ist \[r = f - u = 0.9 - 0.1 = 0.8.\]
Wären die Schildkröten in der Hälfte der so aufgelisteten Paarungen besser gewesen wäre die biserielle Rangkorrelation \(r = f-u=0.5 - 0.5 = 0\). Wären die Hasen immer besser gewesen, wäre die biserielle Rangkorrelation \(r = f-u = 1-0 = 1\). Wären die Schildkröten immer besser gewesen, wäre die biserielle Rangkorrelation \(r = f-u = 0-1 = -1\). Kein Effekt entspricht also \(r = 0\), je weiter weg von \(0\) die biserielle Rangkorrelation, desto stärker ist der Effekt. Es spielt keine Rolle, ob der Effekt positiv oder negativ ist.
Die biserielle Effektstärke kann auch aus der Teststatistik \(U\) berechnet werden mit der Formel \[r = \frac{2\cdot U}{n_1\cdot n_2}-1,\] wobei hier das Vorzeichen ändert, je nach dem, für welche Gruppen \(U_1\) resp. \(U_2\) stehen.
Die Interpretation einer Korrelation als Effektstärke unterliegt einer anderen Referenz als die bisher gesehenen Effektstärken. J. Cohen (1988) schlägt zur Interpretation einer Korrelation die Richtgrössen
- \(|r| \approx 0.1\): schwacher Effekt
- \(|r| \approx 0.3\): mittlerer Effekt
- \(|r| \approx 0.5\): starker Effekt
vor. Um wieder Klarheit im Unterrichtssetting zu schaffen, werden hier die folgenden Abgrenzungen verwendet:
- \(0 < |r| \leq 0.2\): schwacher Effekt
- \(0.2 < |r| \leq 0.4\): mittlerer Effekt
- \(0.4 < |r|\): starker Effekt
In Jamovi kann die biserielle Rankorrelation unter
Zusätzliche Statistiken > Effektstärke eingeblendet werden. Für die
beiden Beispiele 7.1 und
7.2 führt dies zu folgenden
Effektstärken und Berichtensätzen:
Ein zweiseitiger \(U\)-Test nach Mann und Whitney ergibt, dass sich die mediane Schmerztoleranz von Mäusen mit MC4R Gen (\(\text{Mdn}= 11.5, N =13\)) und ohne MC4R Gen (\(\text{Mdn}=7, N = 15\)) signifikant unterscheidet, \(U = 13, p < .001, r = -0.87\) Der Effekt ist als gross einzustufen.
Ein zweiseitiger \(U\)-Test nach Mann und Whitney ergibt, dass sich die mediane Aufgeschlossenheit von jungen Menschen (\(\text{Mdn}= 5, N =13\)) und alten Menschen (\(\text{Mdn}=5, N = 7\)) nicht signifikant unterscheidet, \(U = 33.5, p = .35, r = -0.26\). Der Effekt ist als mittel einzustufen.
Hinweis. Im Berichtensatz muss Folgendes enthalten sein:
- Test und Art der Hypothesenstellung
- Dass es sich um einen Unterschied der Mediane handelt
- Zusammenfassende deskriptive Statistiken der Stichproben
- Statistiken des Tests inklusive Teststatistik, \(p\)-Wert und Effektstärke
- Die Interpretation der Effektstärke kann, wenn gefragt, hinzugefügt werden.
7.3 Übungen
Übung 7.1
Für die Dorfstrasse in Köniz wurden zwei Verkehrskonzepte verglichen
Tempo 50 mit Fussgängerstreifen und Tempo 30 ohne Fussgängerstreifen. Um
die beiden Verkehrskonzepte zu evaluieren, wurden verschiedene Zahlen
erhoben unter anderem die Durchfahrtszeit von Autos, die Anzahl
Strassenquerungen von Fussgängern und die Anzahl Unfälle. Hier soll nur
die Durchfahrtszeit von Autos in Minuten betrachtet und herausgefunden
werden wie sich die Verkehrskonzepte auf diese ausgewirkt haben. Fiktive
Daten dazu wurden als Datensatz 07-exr-tempo30.sav
abgelegt.
- Prüfen Sie, ob die Testvoraussetzungen für einen Welch Test gegeben sind.
- Beschreiben Sie die Population und das Merkmal.
- Testen Sie mit einem \(U\)-Test bei Signifikanzniveau \(5\%\), ob sich die medianen Durchfahrtszeiten in der Population unterscheiden. Berichten Sie das Resultat und interpretieren Sie die Effektstärke.
Klicke hier, um deine Lösung zu überprüfen.
Lösung. Zuerst wird der Datensatz mit Jamovi eingelesen und die
Analyseparameter werden gesetzt, siehe Abbildung
7.3.
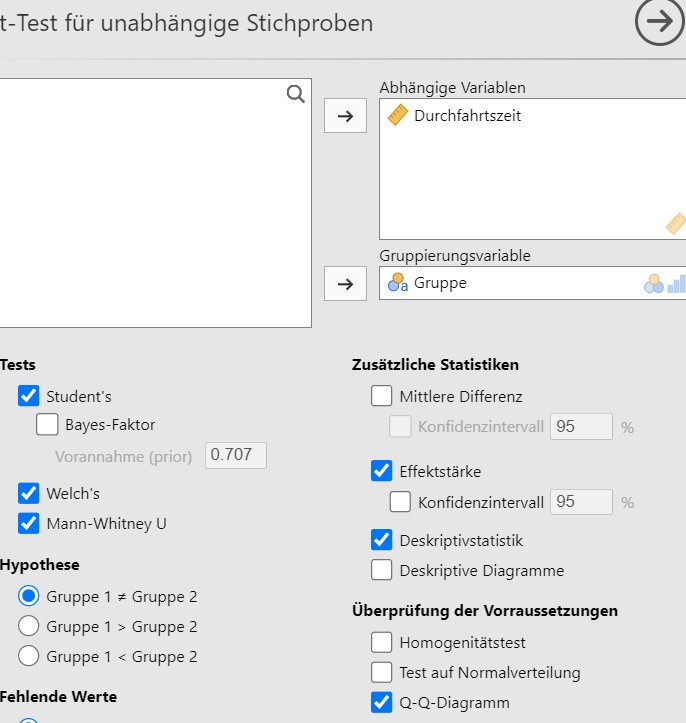
Abbildung 7.3: Jamovi Eingabe.
Dies produziert das Analyseergebnis in Abbildung 7.4.
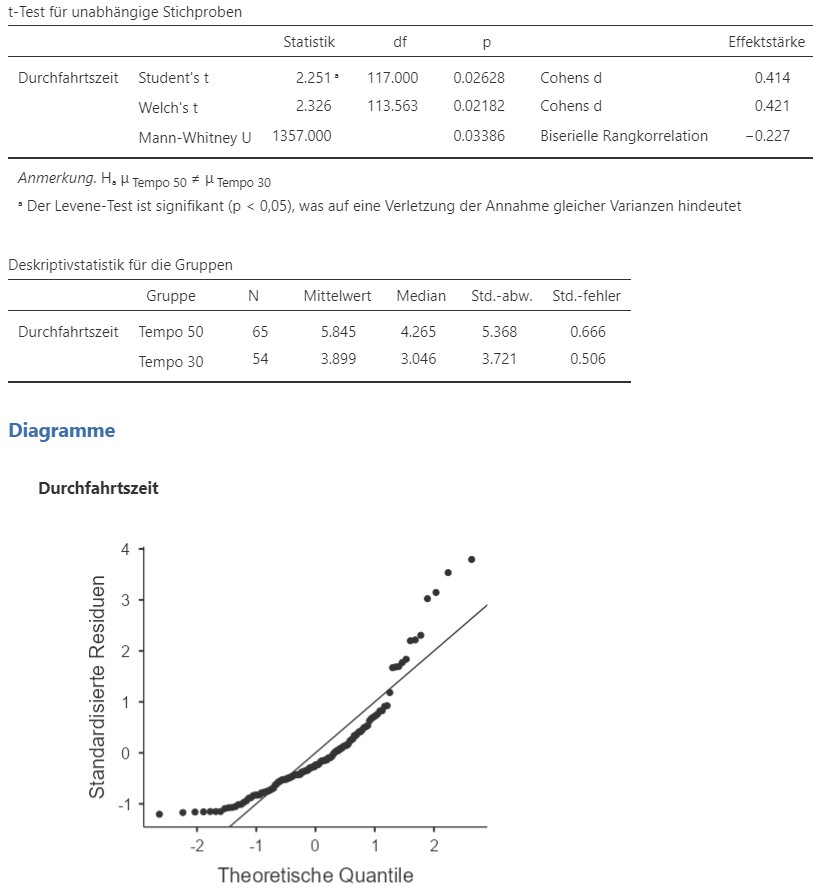
Abbildung 7.4: Jamovi Ausgabe.
Damit können die Teilfragen beantwortet werden.
- Die Durchfahrtszeit ist ein intervallskaliertes Merkmal. Ob die Beobachtungen einer Zufallsstichprobe entstammen oder nicht muss beim Versuchsaufbau berücksichtigt werden und kann nicht im Nachhinein aus den Daten gelesen werden. Es sind mehr als \(30\) Beobachtungen pro Gruppe vorhanden. Damit sind alle Voraussetzungen für den Welch Test gegeben und es könnte hier auch ein Welch Test durchgeführt werden.
- Die Population sind alle Autos die durch die betroffene Strasse fahren. Das Merkmal ist die Durchfahrtszeit von Autos in Minuten.
- Es soll getestet werden, ob sich die medianen Durchfahrtszeiten unterscheiden. Die Hypothesen für den \(U\)-Test sind also zweiseitig formuliert \(H_0: \mu_\text{Tempo 30} = \mu_\text{Tempo 50}\) und \(H_1: \mu_\text{Tempo 30} \neq \mu_\text{Tempo 50}\). Das Testergebnis kann aus Jamovi abgelesen werden und wird wie folgt berichtet und interpretiert:
Ein zweiseitiger \(U\)-Test nach Mann und Whitney ergibt, dass sich die mediane Durchfahrtszeit durch Köniz bei Tempo 30 (\(\text{Mdn}= 3.05 \text{Min}, N =54\)) und Tempo 50 (\(\text{Mdn}=4.27 \text{Min}, N = 65\)) signifikant unterscheidet, \(U = 1357, p = .034, r = -0.227\). Der Effekt ist als mittel einzustufen.
Übung 7.2
Ein Flughafen nimmt ein neues Terminal in betrieb. Um den Betrieb für
die Zukunft zu optimieren und die Wartezeit der Gäste möglichst kurz zu
halten, werden zwei Warteschlangenkonzepte getestet. Gäste werden dabei
per Kamera getrackt und ihre Wartezeit in Minuten wird im Datensatz
07-exr-warteschlangen.sav festgehalten.
- Prüfen Sie, ob die Testvoraussetzung für einen Welch Test gegeben ist.
- Beschreiben Sie die Population und das Merkmal.
- Testen Sie mit einem \(U\)-Test bei Signifikanzniveau \(5\%\), ob sich die medianen Wartezeiten der beiden Gruppen in der Population unterscheiden. Berichten Sie das Resultat und interpretieren Sie die Effektstärke.
Klicke hier, um deine Lösung zu überprüfen.
Lösung. Zuerst wird der Datensatz mit Jamovi eingelesen und die
Analyseparameter werden gesetzt, siehe Abbildung
7.5.
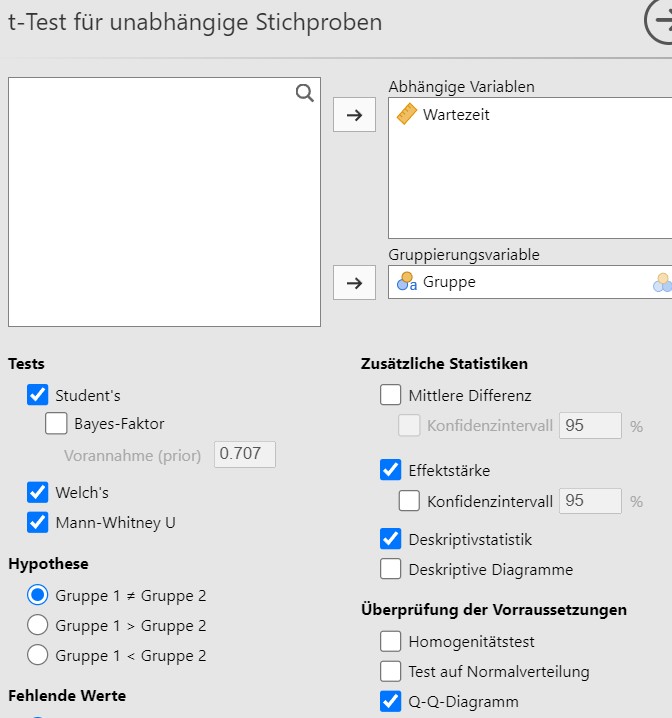
Abbildung 7.5: Jamovi Eingabe.
Dies produziert das Analyseergebnis in Abbildung 7.6.
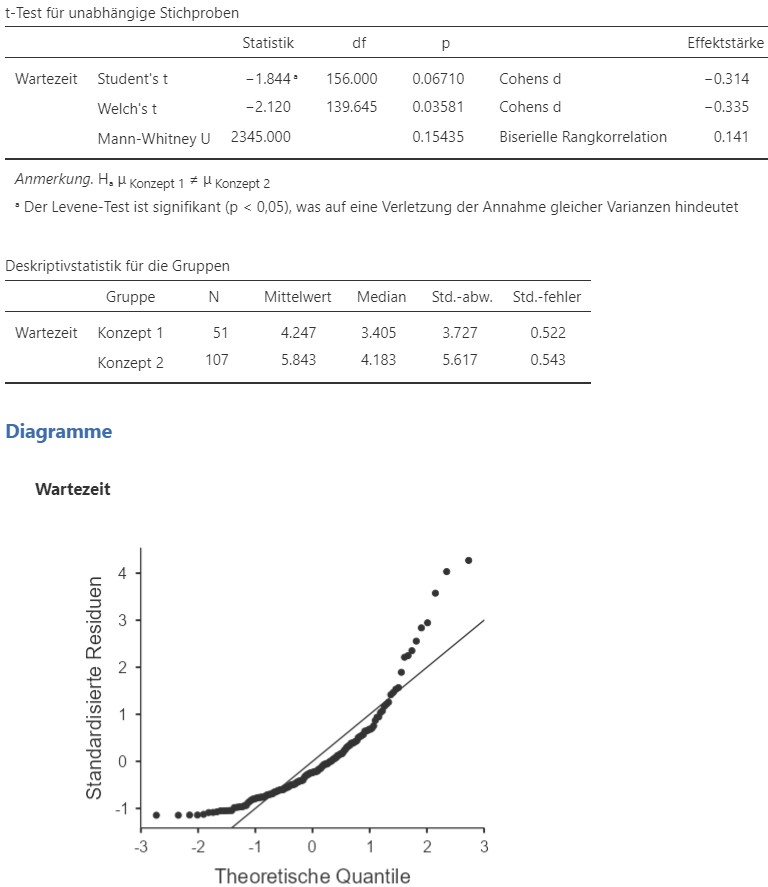
Abbildung 7.6: Jamovi Ausgabe.
Damit können die Teilfragen beantwortet werden.
- Die Wartezeit ist ein intervallskaliertes Merkmal. Ob die Beobachtungen einer Zufallsstichprobe entstammen oder nicht muss beim Versuchsaufbau berücksichtigt werden und kann nicht im Nachhinein aus den Daten gelesen werden. Es sind mehr als \(30\) Beobachtungen pro Gruppe vorhanden. Damit sind alle Voraussetzungen für den Welch Test gegeben und es könnte hier auch ein Welch Test durchgeführt werden.
- Die Population sind alle Gäste, die den neuen Terminal benutzen. Das Merkmal ist die Wartezeit der Gäste in Minuten.
- Es soll getestet werden, ob sich die medianen Durchfahrtszeiten
unterscheiden. Die Hypothesen für den \(U\)-Test sind also zweiseitig
formuliert \(H_0: \mu_\text{Konzept 1} = \mu_\text{Konzept 2}\) und
\(H_1: \mu_\text{Konzept 1} \neq \mu_\text{Konzept 2}\). Das
Testergebnis kann aus
Jamoviabgelesen werden und wird wie folgt berichtet und interpretiert:
Ein zweiseitiger \(U\)-Test nach Mann und Whitney ergibt, dass sich die mediane Wartezeit am neuen Terminal bei Konzept 1 (\(\text{Mdn}= 3.41 \text{Min}, N =51\)) und Konzept 2 (\(\text{Mdn}=4.18 \text{Min}, N = 107\)) nicht signifikant unterscheidet, \(U = 2345, p = .154, r = 0.141\). Der Effekt ist als klein einzustufen.
Übung 7.3
Studierende der Kurse Statistik \(1\) und \(2\) sollen auf einer Skala von \(1\) bis \(10\) bewerten (\(1=\) gar nicht herausfordernd, \(10 =\) äusserst herausfordernd), wie herausfordernd der Statistikunterricht für sie ist. Wird von allen Studierenden der Kurs Statistik \(2\) durchschnittlich als herausfordernder betrachtet als Statistik \(1\)?
- Stellen Sie die Testhypothesen auf.
- Weshalb wird hier ein \(U\)-Test gegenüber einem Welch Test bevorzugt?
- Führen Sie einen \(U\)-Test durch mit Signifikanzniveau \(5\%\),
berichten Sie das Ergebnis in einem Satz und interpretieren Sie die
Effektstärke. Die Daten sind unter
07-exr-statistik-herausforderung.savverfügbar. (Beispiel frei erfunden.)
Klicke hier, um deine Lösung zu überprüfen.
Lösung. Zuerst wird der Datensatz mit Jamovi eingelesen und die
Analyseparameter werden gesetzt, siehe Abbildung
7.7.
Abbildung 7.7: Jamovi Eingabe.
Dies produziert das Analyseergebnis in Abbildung 7.8.
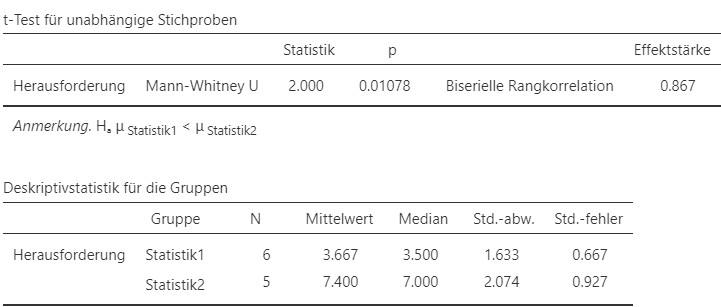
Abbildung 7.8: Jamovi Ausgabe.
Damit können die Teilfragen beantwortet werden.
- Die Frage “Wird von allen Studierenden der Kurs Statistik \(2\) durchschnittlich als herausfordernder betrachtet als Statistik \(1\)” ist einseitig formuliert. Es soll getestet werden, ob \(H_1: \mu_\text{Statistik 1} < \mu_\text{Statistik 2}\). Dies entspricht der Nullhypothese \(H_0: \mu_\text{Statistik 1} \geq \mu_\text{Statistik 2}\)
- Hier wird ein \(U\)-Test verwendet, da das Merkmal auf einem einzigen Likert-skaliertem Merkmal beruht. Dieses ist demnach ordinalskaliert. Ein Welch Test eignet sich nur für intervallskalierte Merkmale.
- Das Testergebnis kann aus
Jamoviabgelesen werden und wird wie folgt berichtet und interpretiert:
Ein einseitiger \(U\)-Test nach Mann und Whitney ergibt, dass die mediane Herausforderung in Statistik 2 (\(\text{Mdn}=7, N = 5\)) signifikant grösser ist als in Statistik 1 (\(\text{Mdn}= 3.5, N =6\)), \(U = 2, p = .011, r = 0.867\). Der Effekt ist als gross einzustufen.
Übung 7.4 Eine Neurologin sammelt Daten, um die depressive Wirkung bestimmter
Freizeitdrogen zu untersuchen. Sie schickt dazu \(20\) männliche
Clubgänger unter kontrollierten Bedingungen während vier Stunden in ein
Tanzlokal. Zehn Testpersonen nehmen eine Ecstasy Pille ein, die zehn
anderen trinken einen Liter Bier. Der Grad der Depression wird mit dem
Beck Depression Inventory (BDI) zwölf Stunden nach dem Verlassen des
Tanzlokals gemessen. Die Daten sind unter
07-exr-depression-ecstasy.sav verfügbar. Ist die
durchschnittliche Schwere der Nachtanzdepression bei der Ecstasy-Gruppe
schlimmer als bei der Alkohol-Gruppe? Testen Sie mit einem \(U\)-Test,
berichten Sie das Testresultat und schätzen sie die Effektstärke ein.
Klicke hier, um deine Lösung zu überprüfen.
Lösung. Zuerst wird der Datensatz mit Jamovi eingelesen und die
Analyseparameter werden gesetzt, siehe Abbildung
7.9.
Abbildung 7.9: Jamovi Eingabe.
Dies produziert das Analyseergebnis in Abbildung 7.10.
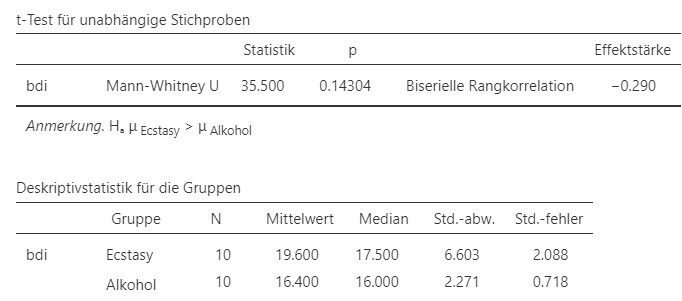
Abbildung 7.10: Jamovi Ausgabe.
Damit kann die Frage nun beantwortet werden:
Ein einseitiger \(U\)-Test nach Mann und Whitney ergibt, dass die mediane Nachtanzdepression in der Ecstasy-Gruppe (\(\text{Mdn}=17.5, N = 10\)) nicht signifikant grösser ist als in der Alkohol-Gruppe (\(\text{Mdn}= 16, N =10\)), \(U = 35.5, p = .143, r = -0.290\). Der Effekt ist als mittel einzustufen.