Kapitel 4 Durchschnitt und Standardabweichung schätzen
Wie die in Abschnitt 3.2 skizzierte Lösung für das Problem der zufälligen Stichprobe konkret umgesetzt wird, hängt von der Problemstellung ab. Im Folgenden wird ein Verfahren zur Generalisierung der Schätzung der zentralen Tendenz basierend auf einer Stichprobe präsentiert.
4.1 Wo liegt der Durchschnitt der Grundgesamtheit?
Ein Parameter, über welchen wir gerne eine Aussage treffen würden, ist die zentrale Tendenz in der Grundgesamtheit. Diese wird Erwartungswert (Symbol \(\mu\) [gr.: mü]) genannt. Wenn das arithmetische Mittel der Stichprobe berechnet wird, ergibt dies auch ein Schätzwert für besagten Erwartungswert. Aufgrund der zufälligen Stichprobenziehung ist jedoch auch klar, dass dieser Schätzwert nie genau dem wahren Erwartungswert entspricht.
In Beispiel 3.1 liegt das arithmetische Mittel in der Stichprobe der Studierenden bei \(M=43.2\). Dieser Wert entspricht nun auch der Schätzung des Erwartungswertes, also der geschätzten durchschnittlichen Angst aller Menschen. Die Folgefrage ist also wie genau unsere Schätzung ist. Um dies zu quantifizieren, wiederholen wir die Stichprobenziehung und berechnen das arithmetische Mittel dieser zweiten Stichprobe. Dann wiederholen wir diesen Prozess, zum Beispiel \(1000\) mal.
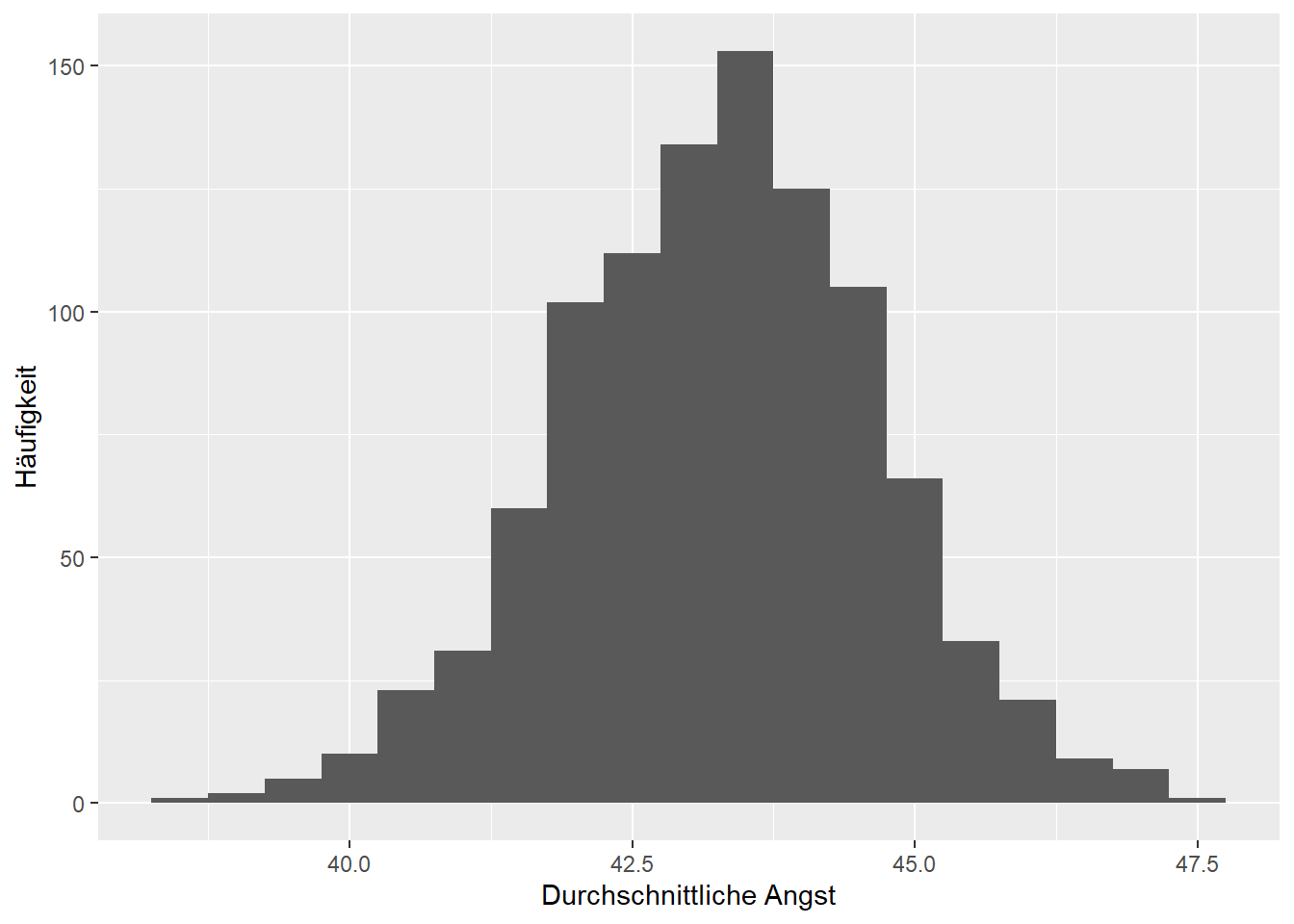
Abbildung 4.1: Verteilung der arithmetischen Mittel von 1000 zufällig gezogenen Stichproben der Angst.
Die Häufigkeitsverteilung der berechneten arithmetischen Mittel in Abbildung 4.1 lässt nun eine Aussage über die Häufigkeit und damit über die Wahrscheinlichkeit von gewissen Werten als Erwartungswert zu. Ein Durchschnittswert der Zustandesangst um die \(43\) ist hier am wahrscheinlichsten und ein Wert tiefer als \(41\) oder höher \(45\) eher selten. Um diese Aussage präziser zu gestalten, werden konventionell die \(95\)% häufigsten Werte (die höchsten Balken im Histogramm) als wahrscheinlich betrachtet. Die \(5\)% verbleibenden Werte, verteilt auf das untere und obere Extrem, werden als unwahrscheinlich betrachtet. Das \(2.5\)% Perzentil trennt die \(2.5\)% tiefsten arithmetischen Mittel ab und liegt im Beispiel bei \(40.4\). Das \(97.5\)%-Perzentil trennt die höchsten \(2.5\)% (oder eben die tiefsten \(97.5\)%) arithmetischen Mittel ab und liegt bei \(46\). Dies ist in Abbildung 4.2 ersichtlich.
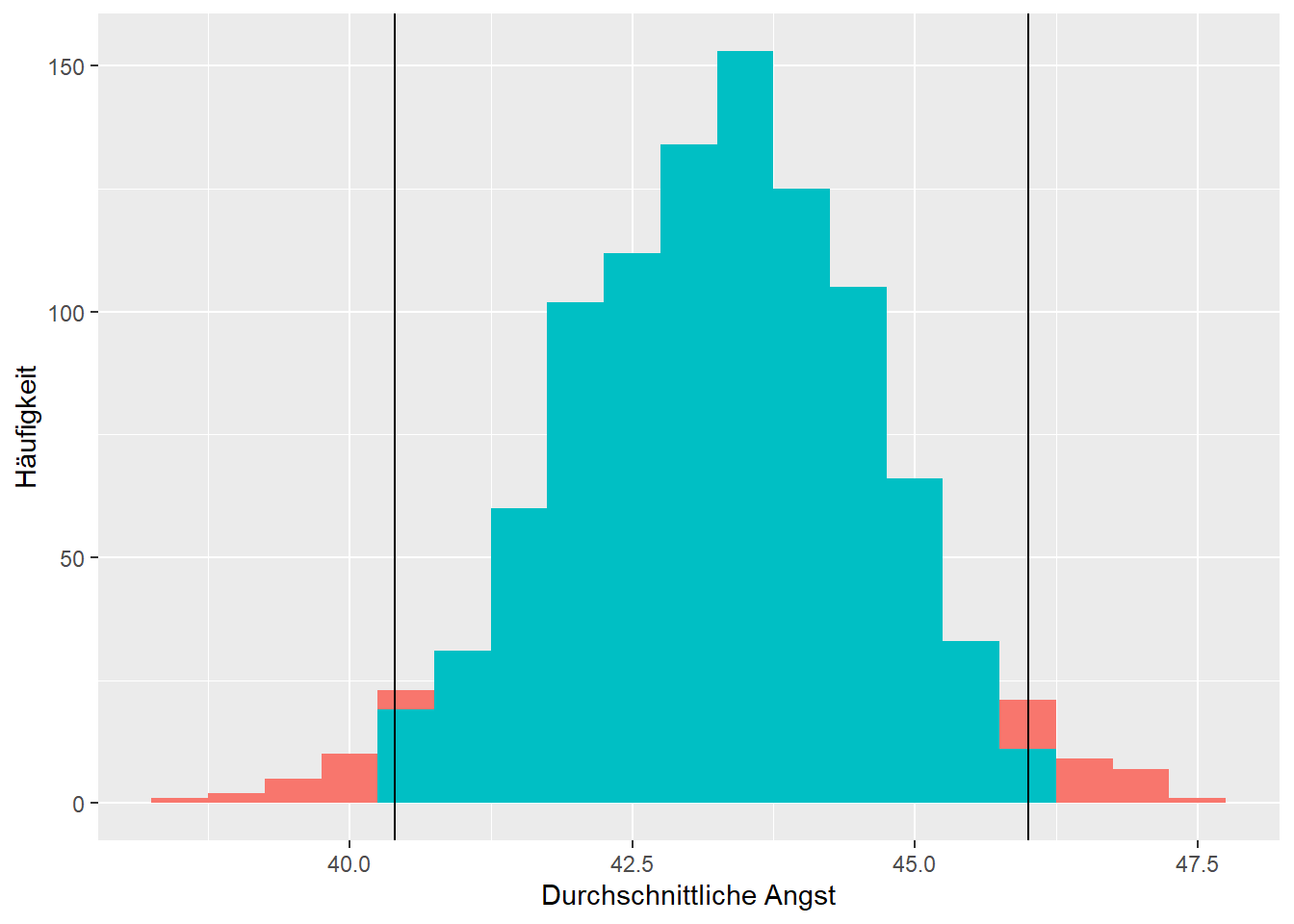
Abbildung 4.2: Verteilung der arithmetischen Mittel von 1000 zufällig gezogenen Stichproben der Angst.
Beispiel 4.1 (Verträglichkeit) Einer der Big-5 Persönlichkeitszüge ist die Verträglichkeit. Eine einfache Art die Big-5 zu messen ist mit den 10 Fragen aus dem ten-item personality inventory TIPI (Gosling, Rentfrow, and Swann 2003). Für die Verträglichkeit müssen zwei Items (Item 1: Critical, quarrelsome; Item 2: Sympathetic, warm) auf einer Likert-Skala von 1 bis 7 eingeordnet werden. Anschliessend werden die Antworten gemittelt. Ein Student möchte herausfinden, ob mit diesem Messinstrument die durchschnittliche Verträglichkeit aller Menschen mittig also bei \(4\) liegt. Dafür befragt er \(n = 100\) Personen und findet die Werte \(M=3.91, s = 1.73\).
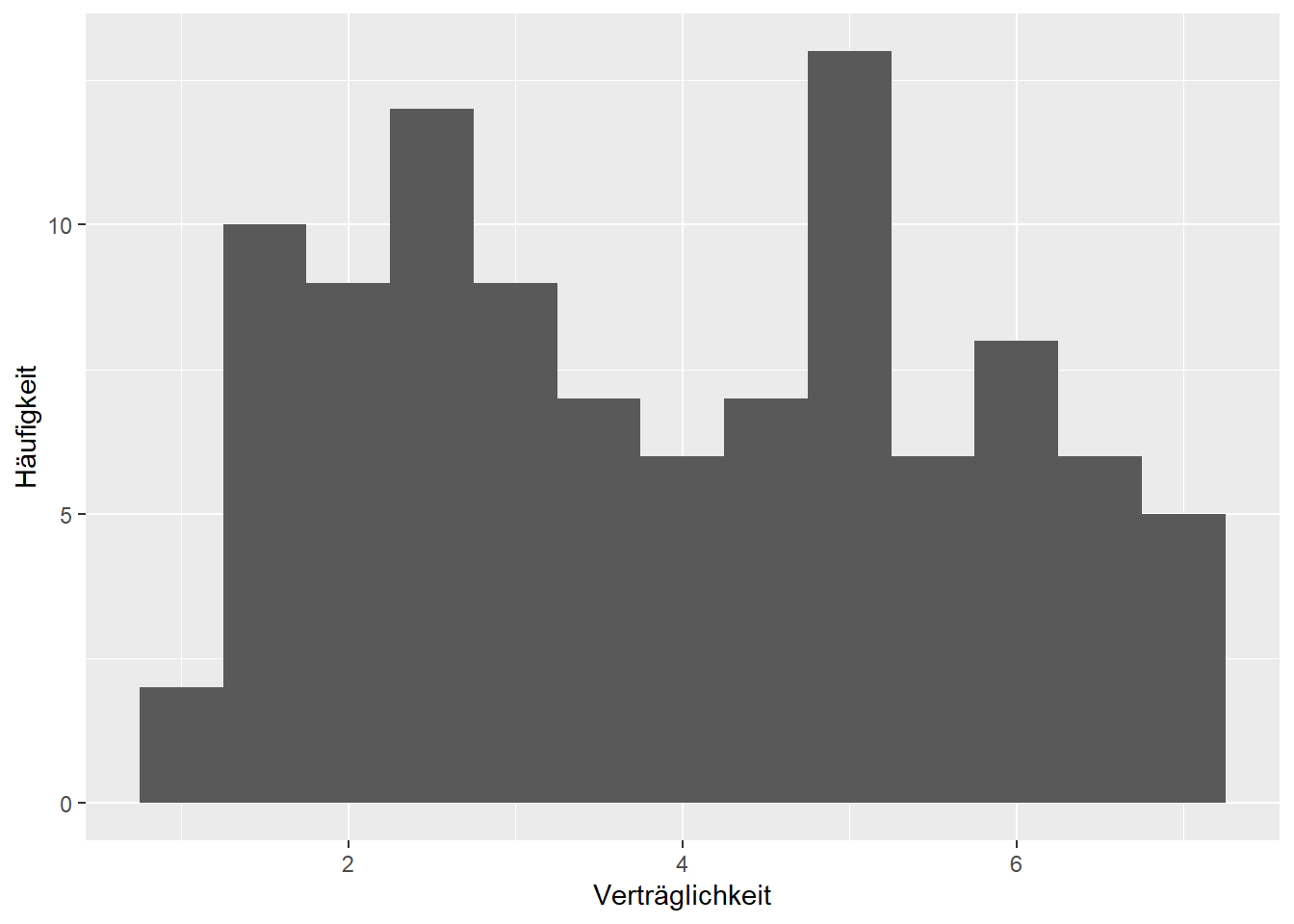
Abbildung 4.3: Verteilung der 100 beobachteten Verträglichkeitswerte einer zufällig gezogenen Stichprobe.
Die Verteilung der Beobachtungen, siehe Abbildung 4.3, zeigt, dass alle Werte zwischen \(1\) und \(7\) vorkommen, aber keine zentrale Tendenz greifbar ist. Um herauszufinden wie zutreffend die Schätzung des Erwartungswertes der Verträglichkeit von \(M=3.91\) ist, stelle man sich wieder vor, dass der Student \(1000\)-mal die Stichprobenziehung wiederholt und jedes Mal das arithmetische Mittel \(M\) von neuem berechnet. Die Verteilung der arithmetischen Mittel dieser Stichproben ist in Abbildung 4.4 dargestellt. Bei dieser Verteilung kann erneut links und rechts \(2.5\%\) der Werte abgeschnitten werden, um zum Schluss zu gelangen, dass das arithmetische Mittel in \(95\%\) der Fälle zwischen \(3.7\) und \(4.3\) zu liegen kommt.
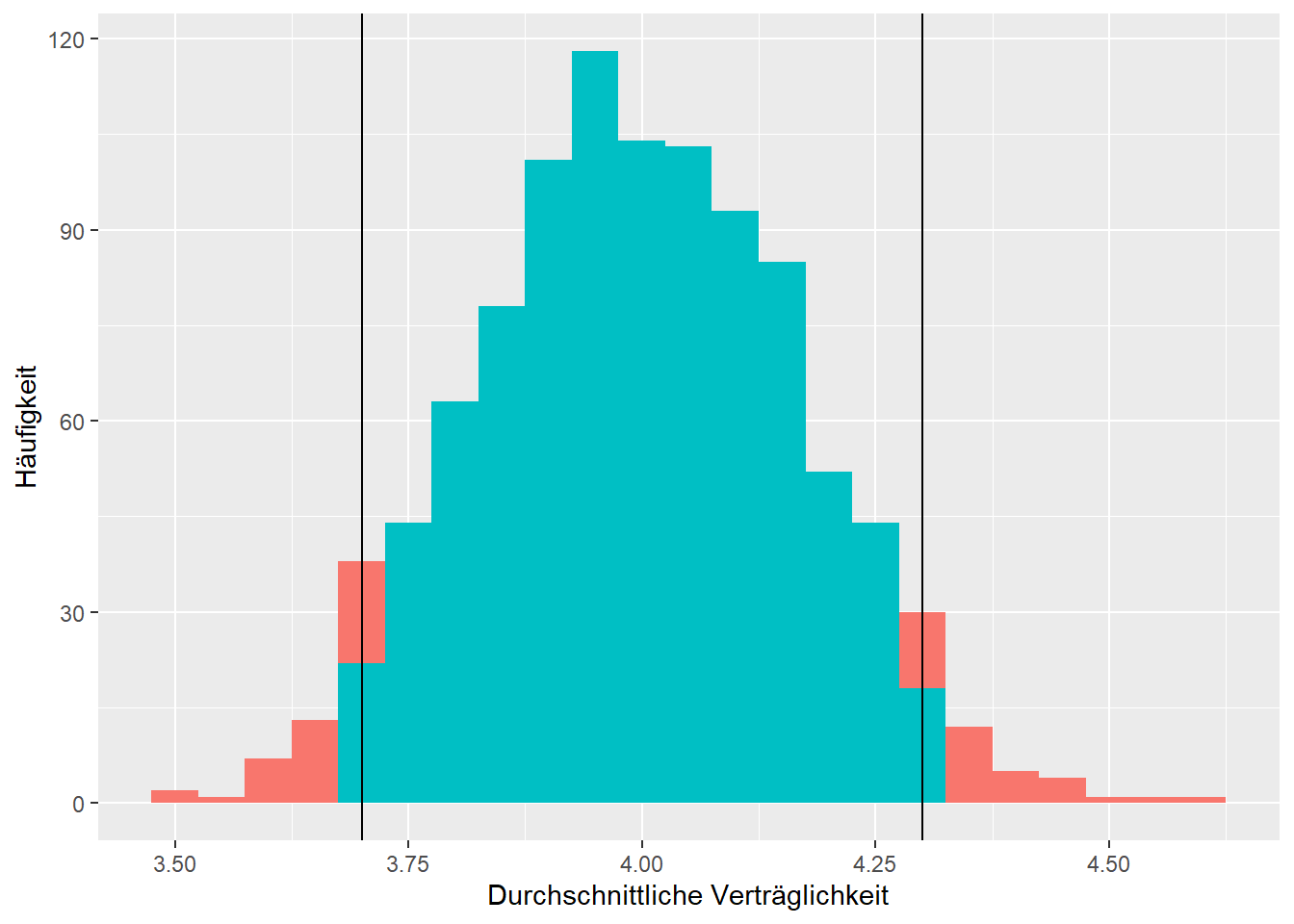
Abbildung 4.4: Verteilung der arithmetischen Mittel von 1000 zufällig gezogenen Stichproben der Verträglichkeit.
Das Problem mit diesem Vorgehen ist, dass es aus finanziellen oder technischen Gründen selten möglich ist mehrere Stichproben aus derselben Population zu ziehen. Glücklicherweise haben Statistiker:innen herausgefunden, dass die Häufigkeitsverteilungen wie in Abbildungen 4.2 und 4.4 immer dieselbe Verteilung haben und dies unabhängig davon wie die ursprüngliche Verteilung des Merkmals aussah. Diese Verteilung ist eine sogenannte Normalverteilung.
Die Normalverteilung sieht einer Glocke ähnlich. Deshalb wird sie auch Gausssche Glockenkurve nach Carl F. Gauss (1777-1855) benannt. Die Normalverteilung kann mit nur zwei Parametern beschrieben werden.
- \(\mu_g\) gibt an, wo auf der \(x\)-Achse der höchste Punkt der Glocke liegt
- \(\sigma_g\) gibt an, wie flach die Glockenform ist (ein grosser Wert entspricht einer flachen Glockenform, ein tiefer Wert einer steilen Glockenform).
Auf seeing-theory.brown.edu > Continuous > Normal kann der Einfluss von \(\mu_g\) und \(\sigma_g\) auf die Normalverteilung erfahren werden.
Diese Tatsache, dass die Durchschnitte aller intervallskalierten Merkmale normalverteilt sind, ist so zentral für die Statistik, dass sie Zentraler Grenzwertsatz genannt wurde. Der zentrale Grenzwertsatz besagt genauer, dass bei einem Merkmal mit Erwartungswert \(\mu\) und Standardabweichung \(\sigma\), der Durchschnitt aller Stichprobenwerte einer Normalverteilung mit \(\mu_g = \mu\) und \(\sigma_g = \frac{\sigma}{\sqrt{n}}\) entspricht, wobei \(n\) die Stichprobengrösse und \(\sigma\) die Standardabweichung des Merkmals in der Population bezeichnet.
Hinweis.
- \(\mu_g = \mu\) bedeutet, dass der Wert, welcher unter der Normalverteilung am wahrscheinlichsten ist, genau dem Erwartungswert des untersuchten Merkmales entspricht.
- \(\sigma_g = \frac{\sigma}{\sqrt{n}}\) hat zwei Implikationen:
- je grösser die Streuung des Merkmals (grosses \(\sigma\)) desto breiter ist auch die Streuung der arithmetischen Mittel (grosses \(\sigma_g\)). Dies bedeutet, je weniger Streuung das Merkmal aufweist, desto genauer ist die Bestimmung des Erwartungswertes des Merkmales.
- je grösser die Anzahl Beobachtungen \(n\), desto kleiner die Streuung der arithmetischen Mittel (kleines \(\sigma_g\)). Dies bedeutet, je grösser die Stichprobe ist, desto genauer ist die Bestimmung des Erwartungswertes des Merkmales.
Die Abbildungen 4.5 und 4.6 illustrieren den zentralen Grenzwertsatz für Beispiel 3.1 und 4.1 respektive, wobei die Normalverteilung der roten Linie entspricht. Dabei wird einstweilen angenommen, dass \(\mu\) und \(\sigma\) bekannt sind. Diese Annahme wird später aufgelöst und dient hier lediglich der Illustration.
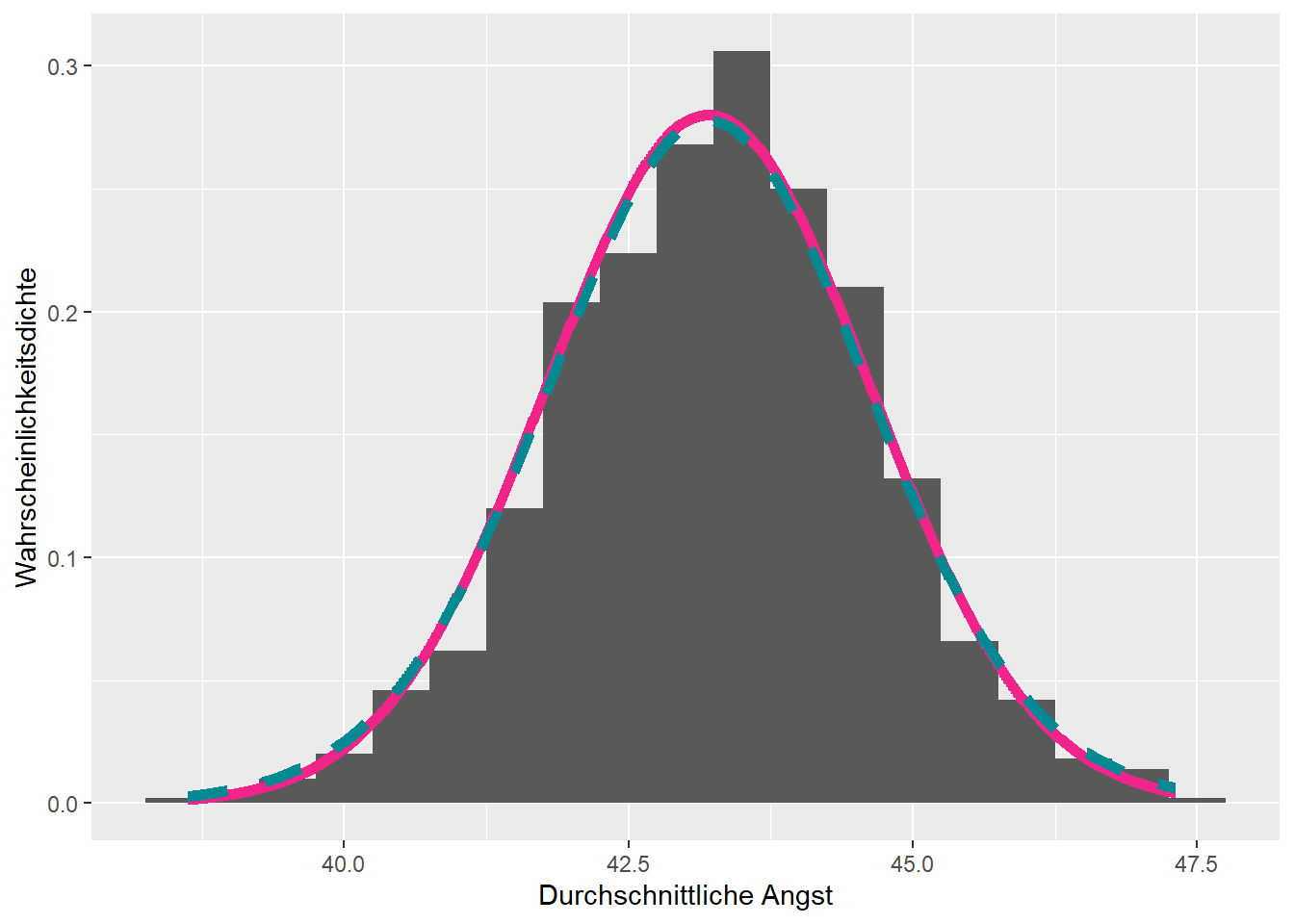
Abbildung 4.5: Die arithmetischen Mittel sind Normalverteilt mit Parametern \(\mu_g = 43.34\) und \(\sigma_g = 9.72 / \sqrt{30}\).
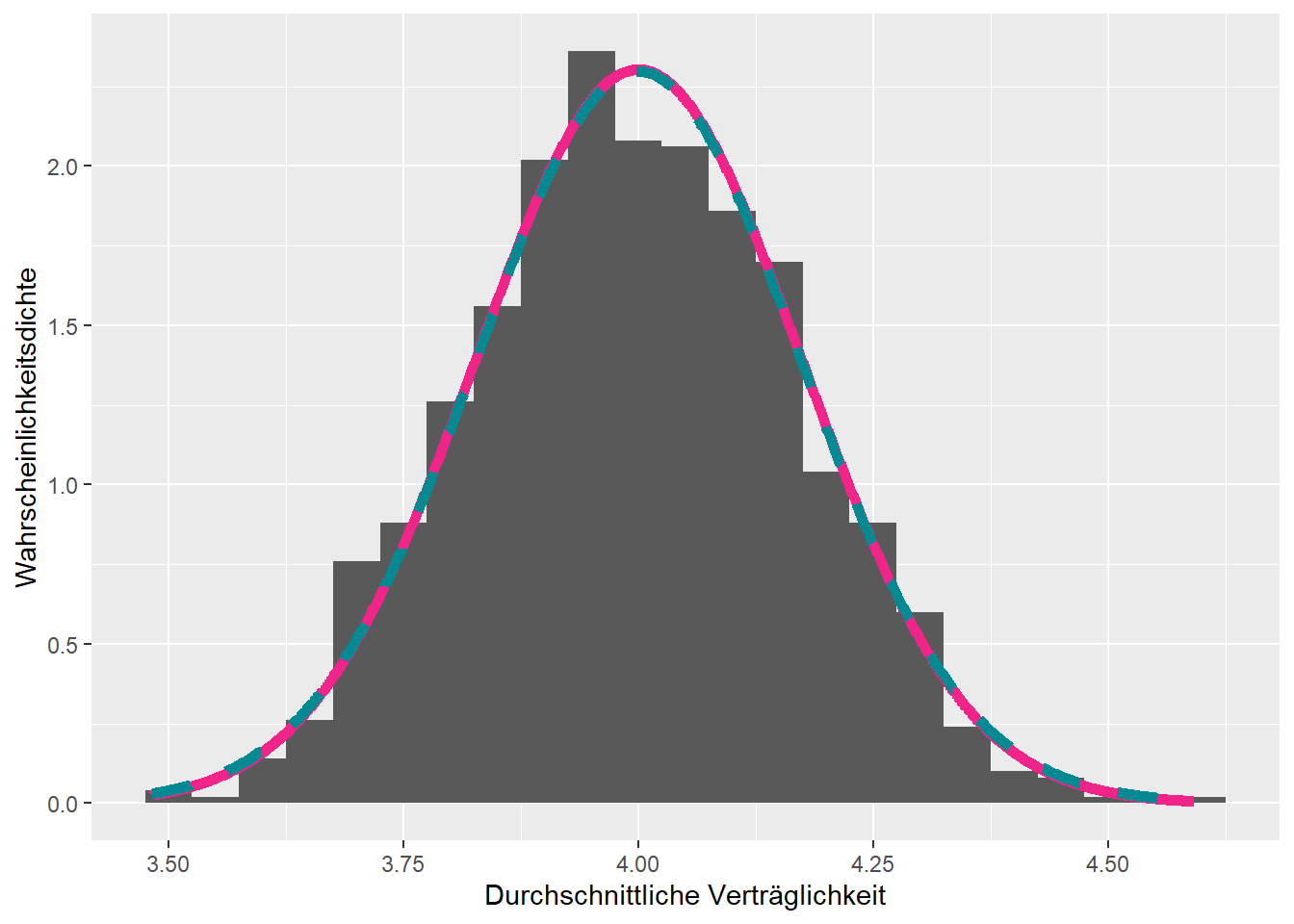
Abbildung 4.6: Die arithmetischen Mittel sind Normalverteilt mit Parametern \(\mu_g = 3.91\) und \(\sigma_g = 1.73 / \sqrt{100}\).
Die Erkenntnis des zentralen Grenzwertsatz macht also das wiederholte Ziehen von Stichproben unnötig. Die Normalverteilung ist theoretisch konstruiert und ihr \(2.5\%\)- und \(97.5\%\)-Perzentil können theoretisch hergeleitet werden. Tabelle 4.1 wird kann beobachtet werden, dass für unsere zwei Beispiele die Perzentile der Stichprobe und der Normalverteilung sehr ähnlich, wenn auch nicht exakt gleich sind. Die Ungenauigkeit rührt daher, dass der zentrale Grenzwertsatz nur dann exakt funktioniert, wenn die Anzahl Beobachtungen (unendlich) gross ist.
| Beispiel | 2.5% | 97.5% | 2.5% | 97.5% | 2.5% | 97.5% |
|---|---|---|---|---|---|---|
| Angst | 40.4 | 46.0 | 42.23 | 44.46 | 42.18 | 44.50 |
| Vertraeglichkeit | 3.7 | 4.3 | 3.66 | 4.34 | 3.66 | 4.34 |
Einstweilen wurde hier angenommen, dass die Streuung des Merkmals \(\sigma\) bekannt ist. Dies ist in der Realität nie der Fall und eine weitere, wenn auch weniger grosse, Ungenauigkeitsquelle. Wenn \(\sigma\) also auch aus der Stichprobe geschätzt werden muss, ist die Annäherung der Verteilung der arithmetischen Mittel besser gegeben mit einer Student-\(t\)-Verteilung oder kurz \(t\)-Verteilung. Die grüne gestrichelte Linie in den Abbildungen 4.5 und 4.6 entspricht der \(t\)-Verteilung im jeweiligen Beispiel.
Der Unterschied zwischen der Normalverteilung und der \(t\)-Verteilung ist nur sichtbar, wenn \(n\) klein ist. In Beispiel 3.1 mit \(n = 30\) ist ein kleiner Unterschied, in Beispiel 4.1 mit \(n = 100\) ist kein Unterschied zwischen der Normalverteilung und der \(t\)-Verteilung sichtbar. Tatsächlich wird die \(t\)-Verteilung mit einem Parameter charakterisiert, welcher Freiheitsgrade (eng. degrees of freedom, \(df\)) genannt wird. In Abbildung 4.7 wird die \(t\)-Verteilung mit verschiedenen Freiheitsgraden mit der Normalverteilung verglichen. Bei der \(t\)-Verteilung mit den kleinsten Freiheitsgraden sind extremere Werte wahrscheinlicher als \(t\)-Verteilungen mit grösseren Freiheitsgraden.
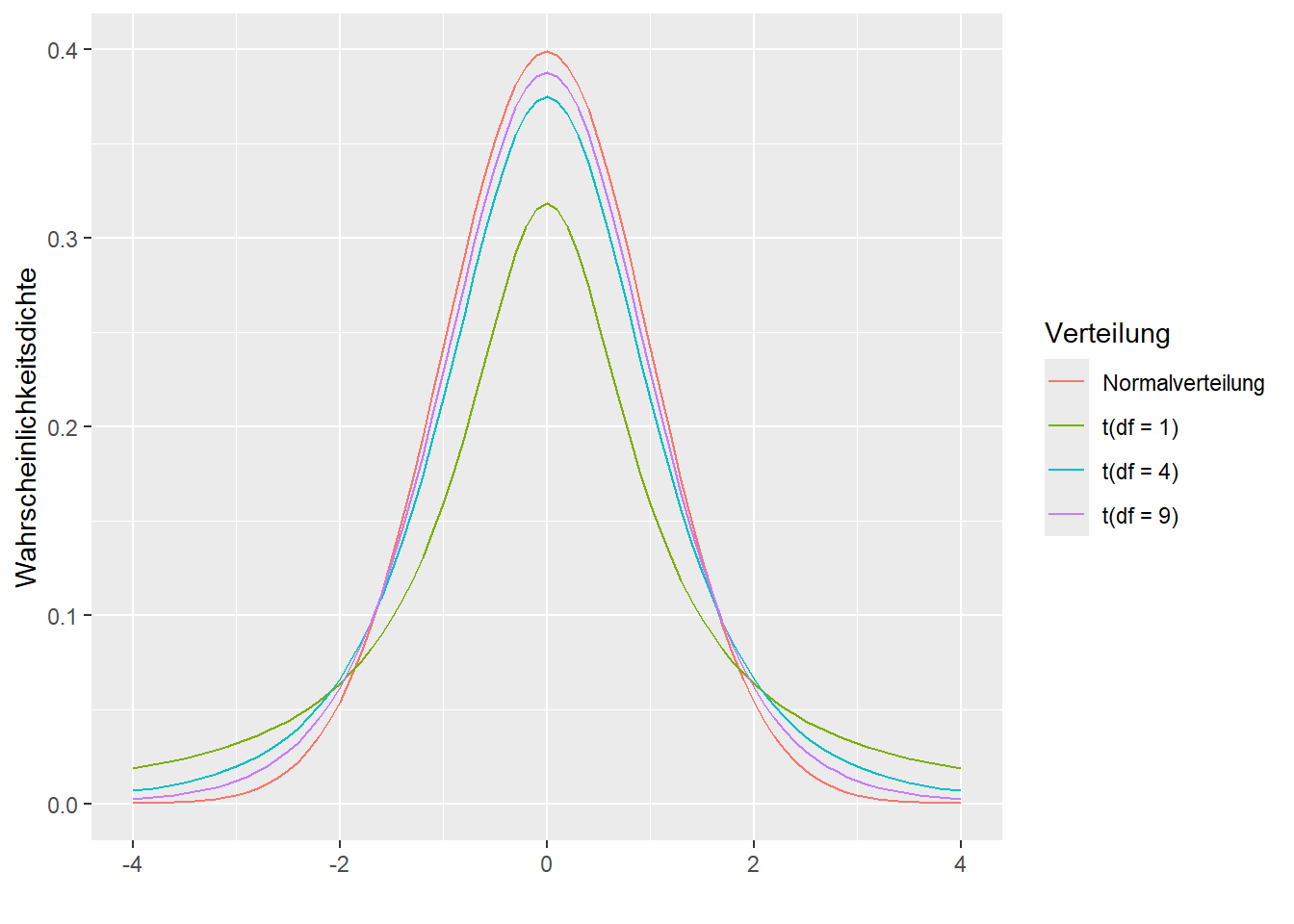
Abbildung 4.7: Student-t-Verteilungen mit 1, 4 und 9 Freiheitsgraden im Vergleich zu der Normalverteilung.
Die Freiheitsgrade der \(t\)-Verteilung in der Annäherung oben entsprechen der Anzahl Beobachtungen minus 1, also \(df = n-1\). Die höhere Wahrscheinlichkeit von extremeren Werten bei kleinen Freiheitsgraden spiegelt die grössere Unsicherheit der Schätzung des Erwartungswertes wider, wenn die Standardabweichung unbekannt und damit auch geschätzt werden muss. Je kleiner \(n\) ist, desto stärker fällt diese Unsicherheit aus.
Die arithmetischen Mittel bei unbekannter Standardabweichung sind bei wiederholter Stichprobenziehung genau \(t\)-verteilt. Um die Genauigkeit der Schätzung des Erwartungswertes zu bestimmen, genügt es folglich, das 2.5% und das 97.5% Perzentil der \(t\)-Verteilung mit \(n-1\) Freiheitsgraden zu bestimmen. Diese Perzentile können mit
\[\begin{equation} \bar{x} - \frac{s}{\sqrt{n}} \cdot t_{97.5\%, n-1} < \mu < \bar{x} + \frac{s}{\sqrt{n}} \cdot t_{97.5\%, n-1}\tag{4.1} \end{equation}\]
berechnet werden, wobei \(\bar{x}\) das arithmetische Mittel, \(s\) die Standardabweichung und \(t_{97.5\%, n-1}\) dem Wert des \(97.5\%\)-Perzentil einer auf \(0\) zentrierten \(t\)-Verteilung mit \(n-1\) Freiheitsgraden entspricht. Letzere Perzentile der \(t\)-Verteilung können bei Bedarf in entsprechenden Tabellen nachgeschlagen werden. Diese Tabelle ist auch in Jamovi hinterlegt. Der Wert für \(t_{97.5\%, 30-1}=t_{97.5\%, 29}\) wird aufgerufen indem bei Rj-Editor der Code qt(0.975, df = 29) ausgeführt wird. Wenn dies geklappt hat sollte der Wert 2.045 angezeigt werden. Als Gedankenstütze ist es im Moment jedoch ausreichend für \(t_{97.5\%, n-1}\) immer \(2\) zu denken, da dies ungefähr dem wahren Wert entspricht, wenn \(n\) grösser als \(50\) ist.
Das \(2.5\%\) und das \(97.5\%\) Perzentil der Verteilung der arithmetischen Mittel ergeben nun die untere respektive obere Schranke eines Intervalls. Ein Intervall bezeichnet durch die Symbolik \([\)untere Schranke, obere Schranke\(]\) beinhaltet alle Zahlen zwischen der unteren und der oberen Schranke. Ein Intervall mit den oben beschriebenen Perzentilen als Schranken wurde so berechnet, dass bei wiederholter Stichprobenziehung der wahre Erwartungswert in \(95\%\) der Fälle umschlossen wird. Grob übersetzt bedeutet dies, dass wir zu \(95\%\) sicher oder konfident sind, dass der Erwarungswert in diesem Intervall liegt. Dieses Intervall wird deshalb als \(95\%\)-Konfidenzintervall (Symbol KI) bezeichnet. Als Sicherheit wird konventionell oft \(95\%\) gewählt, andere Sicherheitswerte sind aber ebenfalls möglich und sinnvoll. Diese Werte heissen Vertrauenswahrscheinlichkeit. Ein \(95\%\)-Konfidenzintervall ist also ein Konfidenzintervall mit \(95\%\) Vertrauenswahrscheinlichkeit. Andersherum betrachtet kann auch festgestellt werden, dass bei einem \(95\%\)-Konfidenzintervall die Wahrscheinlichkeit sich zu irren bei \(5\%\) liegt. Irren bedeutet hier, dass der wahre Erwartungswert bei wiederholter Stichprobenziehung von \(5\%\) der Konfidenzintervallen nicht überdeckt wird. Dieser Wert wird demnach Irrtumswahrscheinlichkeit genannt und mit \(\alpha\) bezeichnet. Es ist demnach äquivalent von einem \(99\%\) Konfidenzintervall oder von einem Konfidenzintervall mit \(1\%\) Irrtumswahrscheinlichkeit zu sprechen.
In Beispiel 3.1, kann aus der Tabelle 4.1 entnommen werden, dass die Angst in der Population bei \(M = 43.34\) \(95\%\) KI \([42.18,44.5]\) liegt. In Beispiel 4.1, kann aus der Tabelle 4.1 entnommen werden, dass die Verträglichkeit in der Population bei \(M = 3.91\) \(95\%\) KI \([3.66,4.34]\) liegt. Wann immer eine Schätzung eines zentralen Wertes berichtet wird, soll dies ab jetzt in der soeben gezeigten Darstellung inklusive Angabe des Konfidenzintervalls erfolgen. Damit wird der Leserin aufgezeigt, wo der Schätzwert der zentralen Tendenz liegt und gleichzeitig wird intuitiv vermittelt, wie genau die Schätzung ist.
Es ist nun spannend zu explorieren, wie sich die Stichprobengrösse \(n\) oder die geschätzte Standardabweichung \(s\) auf die Länge des Konfidenzintervalls auswirkt. Dies kann in den Übungen 4.4 und 4.5 selbst erforscht werden.
4.2 Übungen
Übung 4.1
Die Firma Pear bringt ein neues Smartphone das F42 der Reihe Supernova X auf den Markt. Das Smartphone ist für Jugendliche im Alter von \(15-20\) Jahre konzipiert. Um herauszufinden, welcher Marktpreis für das F42 verlangt werden kann, erfragt Pear bei \(70\) Jugendlichen die Zahlbereitschaft. Die Daten stehen unter 04-exr-marktpreisanalyse.sav zur Verfügung. Wie gross ist die durchschnittliche Zahlbereitschaft der Jugendlichen? Berichten Sie die Ergebnisse der Marktanalyse mit einem \(95\%\)-Konfidenzintervall.
Klicke hier, um deine Lösung zu überprüfen.
Lösung. Der Datensatz wird bei Jamovi eingelesen und die Analyseparameter wie in Abbildung 4.8 gesetzt. Die Nachkommastellen können im Menu oben rechts bei den drei vertikalen Punkten eingestellt werden.
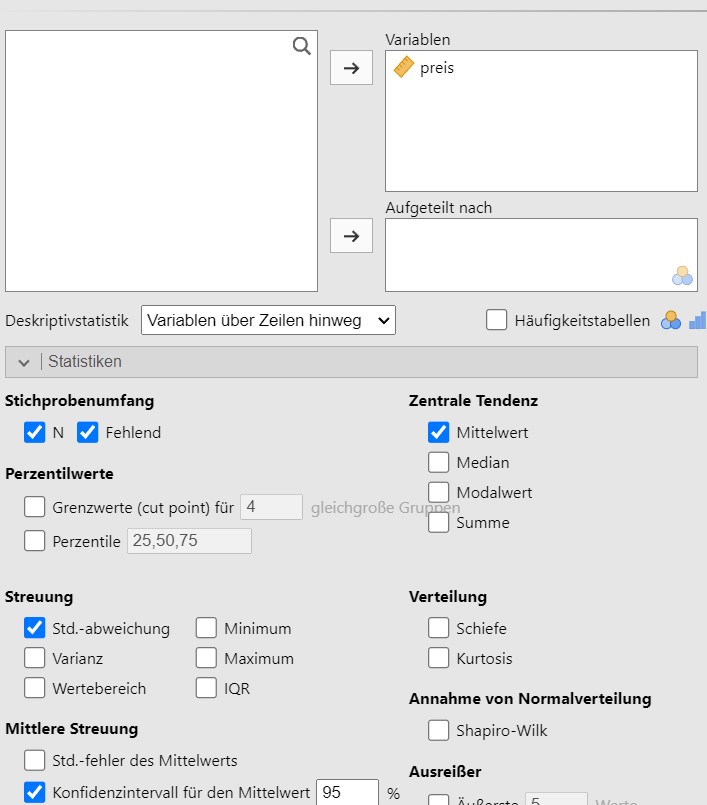
Abbildung 4.8: Jamovi setzen der Analyseparameter.
Dies produziert das Analyseergebnis in Abbildung 4.9.
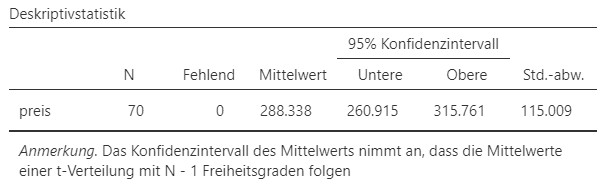
Abbildung 4.9: Jamovi Ausgabe.
Die Marktanalyse mit \(N = 70\) Befragten hat ergeben, dass Jugendliche im Alter von \(15-20\) Jahren bereit sind durchschnittlich \(M = 288.34\) CHF \(95\%\)-KI \([260.92,315.76]\) auszugeben für das neue Supernova X F42 von Pear.
Übung 4.2
In einer Studie werden \(421\) Probandinnen über eine Woche lang beauftragt immer wieder fremde Personen anzusprechen. Dabei wird unter anderem am Anfang und am Ende der Woche gemessen, wie unangenehm auf einer Skala von \(1\) bis \(5\) dies für die Probandinnen ist. Die Daten stehen unter 04-exr-stranger.sav zur Verfügung. Verwenden Sie für drei Nachkommastellen in Jamovi für die folgenden Teilaufgaben.
- Berechnen Sie das \(95\%\)-Konfidenzintervall für die durchschnittliche Unangenehmheit in der Grundgesamtheit für die Situation am Anfang und am Ende der Studie und berichten und interpretieren Sie das Resultat. Denken Sie die Intervention hat die Unangenehmheit, welche durch das Ansprechen von Fremden entsteht, in der Grundgesamtheit durchschnittlich gesenkt?
- Vergleichen Sie die Längen der errechneten Konfidenzintervalle.
- Wiederholen Sie die Aufgabe und berechnen Sie jetzt das \(90\%\) und das \(99\%\)-Konfidenzintervall. Wie verhält sich die Länge des Konfidenzintervalls bei unterschiedlichen Vertrauenswahrscheinlichkeiten?
Diese Aufgabe ist angelehnt an Sandstrom, Boothby, and Cooney (2022).
Klicke hier, um deine Lösung zu überprüfen.
Lösung. Der Datensatz wird bei Jamovi eingelesen und die Analyseparameter wie in Abbildung 4.10 gesetzt. Die Nachkommastellen können im Menu oben rechts bei den drei vertikalen Punkten eingestellt werden.
Abbildung 4.10: Jamovi setzen der Analyseparameter.
Dies produziert das Analyseergebnis in Abbildung 4.11.

Abbildung 4.11: Jamovi Ausgabe.
- Die durchschnittliche Unangenehmheit lag am Anfang der Woche bei \(M=3.784, 95\%\) KI \([3.764, 3.803]\) Punkten und am Ende der Woche bei \(M=3.328, 95\%\) KI \([3.309, 3.348]\) Punkten. Wenn die Studie \(100\) mal wiederholt wird und jedes Mal ein \(95\%\) Konfidenzintervall für den Erwartungswert der Unangenehmheit berechnet wird, so wird der tatsächliche Erwartungswert in \(95\%\) der Fälle also ungefähr \(95\) mal vom Konfidenzintervall überdeckt. Da die Konfidenzintervalle weit auseinander liegen, kann davon ausgegangen werden, dass die Unangenehmheit durchschnittlich tatsächlich nach dem Versuch tiefer liegt als vor dem Versuch. Die Unangenehmheit kann also durch Training vermindert werden.
- Die Länge der Konfidenzintervalle betragen am Anfang der Woche \(3.803-3.764=0.039\) und am Ende der Woche \(3.348-3.309= 0.039\).
- Um das \(90\%\) Konfidenzintervall zu berechnen kann in der in Abbildung 4.10 dargestellten Maske der Wert für
Konfidenzintervall für den Mittelwertauf \(90\) gesetzt werden. Die durchschnittliche Unangenehmheit lag am Anfang der Woche bei \(M=3.784, 90\%\) KI \([3.767, 3.800]\) Punkten und am Ende der Woche bei \(M=3.328, 90\%\) KI \([3.312, 3.345]\) Punkten. Die durchschnittliche Unangenehmheit lag am Anfang der Woche bei \(M=3.784, 99\%\) KI \([3.758, 3.809]\) Punkten und am Ende der Woche bei \(M=3.328, 99\%\) KI \([3.303, 3.354]\) Punkten. Die Länge der \(90\%\) Konfidenzintervalle ist \(3.800-3.767=0.033\) und \(3.345-3.312=0.033\). Die Länge der \(99\%\) Konfidenzintervalle ist \(3.809-3.758=0.051\) und \(3.354-3.303=0.051\). Es kann also hier empirisch festgestellt werden, dass das Konfidenzintervall grösser wird, je höher die Vertrauenswahrscheinlichkeit sein soll.
Übung 4.3
Scrolle auf seeing-theory.brown.edu > Continuous > Normal bis links ‘Central Limit Theorem’ sichtbar ist.
Mit \(\alpha\) und \(\beta\) kann die Stichprobenverteilung verändert werden. Wenn \(\alpha = \beta = 1\), handelt es sich um eine Gleichverteilung, das heisst, die Beobachtungen sind auf der ganzen Breite gleich wahrscheinlich. Ein Beispiel der realen Welt dazu sind Wochentage, an welchen man krank wird. Bei \(\alpha = 2\) und \(\beta = 5\) sind Beobachtungen links viel häufiger als Beobachtungen rechts. Ein Beispiel dazu wären Geburtszeiten: Geburten sind Tagsüber viel häufiger, weil geplante Geburten (also Kaiserschnitte) auf die Frühschicht geplant werden. Draw = 1 und Draw = 50 bedeutet, dass eine, respektive \(50\), Stichprobe gezogen wird. Sample size ist die Stichprobengrösse.
Der zentrale Grenzwertsatz sagt nun, dass, wenn eine Stichprobe gezogen wird (Punkte fallen von der draw Linie runter) und der Durchschnitt davon gebildet wird (Punkte fallen auf die average-Linie) und dieser Prozess wiederholt wird, so sind die Durchschnitte Normalverteilt. Letzteres bedeutet, dass das Histogramm eine Glockenform hat (vergleiche mit der Linie, welche durch Theoretical angezeigt wird).
- Stelle \(\alpha = 1, \beta = 1\),
Sample size = 3. Wie viele Stichprobenziehungen braucht es, damit die Durchschnitte normalverteilt aussehen? - Stelle \(\alpha = 1, \beta = 1\),
Sample size = 10. Wie viele Stichprobenziehungen braucht es, damit die Durchschnitte normalverteilt aussehen? - Stelle \(\alpha = 2, \beta = 5\),
Sample size = 3. Wie viele Stichprobenziehungen braucht es, damit die Durchschnitte normalverteilt aussehen? - Stelle \(\alpha = 2, \beta = 5\),
Sample size = 10. Wie viele Stichprobenziehungen braucht es, damit die Durchschnitte normalverteilt aussehen? - Was kann daraus geschlossen werden?
Klicke hier, um deine Lösung zu überprüfen.
Lösung. Die folgenden Angaben können individuell unterschiedlich ausfallen. Gründe sind die subjektive Einschätzung, ob ein Histogramm bereits wie die Normalverteilung aussieht oder nicht und der Zufall, welcher bei der Zufallsstichprobenziehung entsteht.
- \(1000\) bis \(2500\) Stichproben.
- \(150\) bis \(250\) Stichproben.
- \(500\) bis \(1100\) Stichproben.
- \(50\) bis \(200\) Stichproben.
- Je mehr Beobachtungen in einer Stichprobe, desto schneller ist der Durchschnitt normalverteilt. Je nach Stichprobenverteilung (Einstellung der \(\alpha\) und \(\beta\)-Werte in der Simulation), ist der Durchschnitt schneller oder langsamer normalverteilt.
Übung 4.4
Eine Mensa will herausfinden, wie lange die Leute um 12h durchschnittlich anstehen müssen. Dazu befragt sie 5 Kund:innen. Das Resultat der Untersuchung ist, dass die Kund:innen im Durchschnitt \(0.4\) Stunden anstehen müssen. Leider ist das Konfidenzintervall sehr gross. Da die Mensa nicht weiss, wie viele Leute befragt werden müssen, um ein kleineres Konfidenzintervall zu erhalten befragt sie in 4 weiteren Runden jeweils 20, 50, 100 und 1000 Kund:innen. Die Daten aller \(5\) Untersuchungen sind unter 04-exr-stichprobengroesse.sav abgelegt. Für jede der \(5\) Stichproben:
- Was ist die Schätzung des Erwartungswertes der Wartezeit?
- Wie gross ist die Standardabweichung der Wartezeit?
- Wie gross ist die Standardabweichung der arithmetischen Mittel?
- Bestimmen Sie die 95%-Konfidenzintervalle.
- Berechnen Sie die Länge jedes Konfidenzintervalls.
Vergleichen Sie die Resultate der Berechnungen für jede Stichprobe:
- Weshalb ist die Schätzung für den Erwartungswert für jede Stichprobe unterschiedlich?
- Was lässt sich über den Zusammenhang zwischen Stichprobengrösse und der Länge des Konfidenzintervalls sagen?
Klicke hier, um deine Lösung zu überprüfen.
Lösung. Abbildung 4.12 zeigt die Berechnungsanweisungen für Jamovi und die resultierende Tabelle daraus.
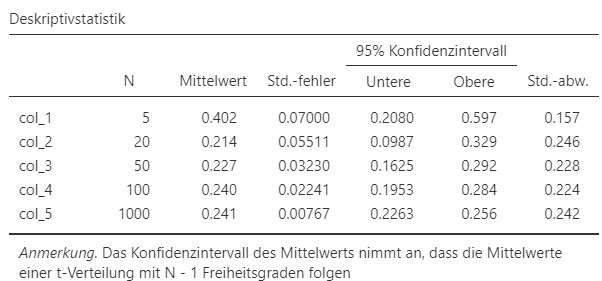
Abbildung 4.12: Links: Jamovi-Anleitung zur Erstellung der Tabelle mit den relevanten Kenngrössen; rechts: Tabelle mit relevanten Kenngrössen.
- Der Erwartungswert der Wartezeiten (das heisst der Populationsmittelwert der Wartezeiten) wird mit dem arithmetischen Mittel der Stichprobe geschätzt und kann in der Tabelle bei
Mittelwertabgelesen werden. Der Erwartungswert der Wartezeiten beträgt bei allen Stichproben ausser bei der ersten ungefähr 0.22 Stunden, also ein bisschen weniger als eine Viertelstunde. - Der Standardabweichung der Wartezeiten der Stichprobe sind in der Tabelle bei
Std.-abw.abzulesen. Die Standardabweichungen sind für alle Stichproben ausser der ersten ungefähr bei 0.23. - Die Standardabweichung der arithmetischen Mittel liegt bei \(s/\sqrt{n}\). Für die erste Stichprobe ist dies \(0.157 / \sqrt{5} = 0.0702125\). Diese Werte werden auch als Standardfehler bezeichnet und sind in der Tabelle bei
Std.-fehlerablesbar. - Die untere und obere Schranke der 95%-Konfidenzintervalle sind bei
UntereundObererespektive abzulesen.
- Die Länge des Konfidenzintervalls entspricht jeweils dem höheren Wert minus dem tieferen Wert. Für die erste Stichprobe ist dies \(0.597 - 0.208 = 0.389\), für die anderen 0.23, 0.13, 0.09 und 0.03.
- Die Schätzung des Erwartungswertes ist das arithmetische Mittel der Stichprobe. Da jedes Mal eine neue Zufallsstichprobe gezogen wurde und diese nicht dieselben Beobachtungen enthalten, ergeben sich auch jedes Mal andere Stichprobenmittelwerte.
- Je grösser \(n\), desto kleiner ist das Konfidenzintervall. Wenn man also ein kleines Konfidenzintervall erreichen will, braucht man eine grössere Stichprobe.
Übung 4.5
Eine Klasse bringt bei einem Biologietest eine durchwachsene Leistung, siehe 04-exr-biologietest.sav. Die Lehrkraft entscheidet sich die genau gleichen Test zu wiederholen. Berichten Sie das durchschnittliche Resultat der beiden Tests und schätzen Sie den Einfluss der Standardabweichung auf die Länge des Konfidenzintervalls ein.
Klicke hier, um deine Lösung zu überprüfen.
Lösung. Der Datensatz wird bei Jamovi eingelesen und die Analyseparameter wie in Abbildung 4.13 gesetzt. Die Nachkommastellen können im Menu oben rechts bei den drei vertikalen Punkten eingestellt werden.
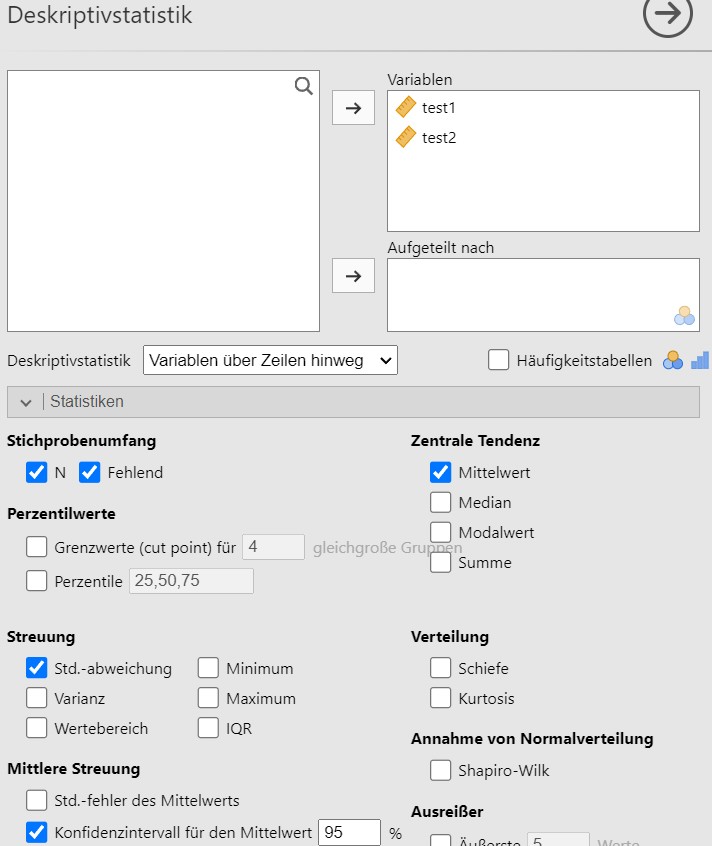
Abbildung 4.13: Jamovi setzen der Analyseparameter.
Dies produziert das Analyseergebnis in Abbildung 4.14.

Abbildung 4.14: Jamovi Ausgabe.
Die Klasse mit \(N=20\) Lernenden hat beim ersten Biologietest eine durchschnittliche Punktzahl von \(M=14.6\) Punkten \(95\%\) KI \([11.9,17.3]\) erzielt. Bei der Wiederholung des Tests wurde eine durchschnittliche Punktzahl von \(M=14.8\) Punkten \(95\%\) KI \([14.0,15.6]\) erzielt. Die Standardabweichung des Testergebnisses war beim ersten Mal \(SD=5.8\) Punkte und bei der Wiederholung \(SD=1.7\) Punkte. Die Länge des Konfidenzintervalls war bei der ersten Durchführung mit \(17.3-11.9=5.4\) Punkten bedeutend grösser als bei der zweiten Durchführung mit \(15.6-14.0=1.6\). Eine grössere Standardabweichung führt also zu einer grösseren Länge des Konfidenzintervalls. Dies kann auch durch Durchprobieren von Testwerten in Gleichung (4.1) festgestellt werden.
4.3 Test
Übung 4.6 Welche der folgenden Aussagen zum Konfidenzintervall des Erwartungswertes sind wahr, welche falsch?
- Je mehr Personen befragt werden, desto grösser wird das Konfidenzintervall.
- Je grösser die Standardabweichung des Merkmals, desto grösser wird das Konfidenzintervall.
- Um ein kleineres Konfidenzintervall zu erreichen, können mehr Beobachtungen gemacht werden.
- Je grösser die Irrtumswahrscheinlichkeit, desto grösser das Konfidenzintervall.
Klicke hier, um deine Lösung zu überprüfen.
Lösung.
- Falsch
- Richtig
- Richtig
- Falsch
Übung 4.7 Im Datensatz 02-exr-koerpergroesse-sex.sav wurden Körpergrössen von Versuchsteilnehmenden erfasst. Welche der folgenden Aussagen sind wahr, welche falsch?
- Die durchschnittliche Körpergrösse der Frauen liegt bei \(M = 166.0\) cm \(90\%\) KI \([164.7, 167.3]\).
- Die durchschnittliche Körpergrösse der Männer liegt bei \(M = 180.3\) cm \(95\%\) KI \([178.6, 182.0]\).
- Es wurden \(N= 163\) Frauen beobachtet.
- Die durchschnittliche Körpergrösse der Männer und Frauen liegt bei \(M = 173.1\) cm \(99\%\) KI \([171.4, 174.9]\).
Klicke hier, um deine Lösung zu überprüfen.
Lösung.
- Falsch
- Richtig
- Richtig
- Richtig